 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode as Agent Harness
May 18, 2026Recent large language models (LLMs) have demonstrated strong capabilities in understanding and generating code, from competitive programming to repository-level software engineering. In emerging agentic systems, code is no longer only a target output. It increasingly serves as an operational substrate for agent reasoning, acting, environment modeling, and execution-based verification. We frame this shift through the lens of agent harnesses and introduce code as agent harness: a unified view that centers code as the basis for agent infrastructure. To systematically study this perspective, we organize the survey around three connected layers. First, we study the harness interface, where code connects agents to reasoning, action, and environment modeling. Second, we examine harness mechanisms: planning, memory, and tool use for long-horizon execution, together with feedback-driven control and optimization that make harness reliable and adaptive. Third, we discuss scaling the harness from single-agent systems to multi-agent settings, where shared code artifacts support multi-agent coordination, review, and verification. Across these layers, we summarize representative methods and practical applications of code as agent harness, spanning coding assistants, GUI/OS automation, embodied agents, scientific discovery, personalization and recommendation, DevOps, and enterprise workflows. We further outline open challenges for harness engineering, including evaluation beyond final task success, verification under incomplete feedback, regression-free harness improvement, consistent shared state across multiple agents, human oversight for safety-critical actions, and extensions to multimodal environments. By centering code as the harness of agentic AI, this survey provides a unified roadmap toward executable, verifiable, and stateful AI agent systems.
ReMix: Reinforcement routing for mixtures of LoRAs in LLM finetuning
Mar 10, 2026Low-rank adapters (LoRAs) are a parameter-efficient finetuning technique that injects trainable low-rank matrices into pretrained models to adapt them to new tasks. Mixture-of-LoRAs models expand neural networks efficiently by routing each layer input to a small subset of specialized LoRAs of the layer. Existing Mixture-of-LoRAs routers assign a learned routing weight to each LoRA to enable end-to-end training of the router. Despite their empirical promise, we observe that the routing weights are typically extremely imbalanced across LoRAs in practice, where only one or two LoRAs often dominate the routing weights. This essentially limits the number of effective LoRAs and thus severely hinders the expressive power of existing Mixture-of-LoRAs models. In this work, we attribute this weakness to the nature of learnable routing weights and rethink the fundamental design of the router. To address this critical issue, we propose a new router designed that we call Reinforcement Routing for Mixture-of-LoRAs (ReMix). Our key idea is using non-learnable routing weights to ensure all active LoRAs to be equally effective, with no LoRA dominating the routing weights. However, our routers cannot be trained directly via gradient descent due to our non-learnable routing weights. Hence, we further propose an unbiased gradient estimator for the router by employing the reinforce leave-one-out (RLOO) technique, where we regard the supervision loss as the reward and the router as the policy in reinforcement learning. Our gradient estimator also enables to scale up training compute to boost the predictive performance of our ReMix. Extensive experiments demonstrate that our proposed ReMix significantly outperform state-of-the-art parameter-efficient finetuning methods under a comparable number of activated parameters.
TSAQA: Time Series Analysis Question And Answering Benchmark
Jan 30, 2026Time series data are integral to critical applications across domains such as finance, healthcare, transportation, and environmental science. While recent work has begun to explore multi-task time series question answering (QA), current benchmarks remain limited to forecasting and anomaly detection tasks. We introduce TSAQA, a novel unified benchmark designed to broaden task coverage and evaluate diverse temporal analysis capabilities. TSAQA integrates six diverse tasks under a single framework ranging from conventional analysis, including anomaly detection and classification, to advanced analysis, such as characterization, comparison, data transformation, and temporal relationship analysis. Spanning 210k samples across 13 domains, the dataset employs diverse formats, including true-or-false (TF), multiple-choice (MC), and a novel puzzling (PZ), to comprehensively assess time series analysis. Zero-shot evaluation demonstrates that these tasks are challenging for current Large Language Models (LLMs): the best-performing commercial LLM, Gemini-2.5-Flash, achieves an average score of only 65.08. Although instruction tuning boosts open-source performance: the best-performing open-source model, LLaMA-3.1-8B, shows significant room for improvement, highlighting the complexity of temporal analysis for LLMs.
Do VLMs Have a Moral Backbone? A Study on the Fragile Morality of Vision-Language Models
Jan 23, 2026Despite substantial efforts toward improving the moral alignment of Vision-Language Models (VLMs), it remains unclear whether their ethical judgments are stable in realistic settings. This work studies moral robustness in VLMs, defined as the ability to preserve moral judgments under textual and visual perturbations that do not alter the underlying moral context. We systematically probe VLMs with a diverse set of model-agnostic multimodal perturbations and find that their moral stances are highly fragile, frequently flipping under simple manipulations. Our analysis reveals systematic vulnerabilities across perturbation types, moral domains, and model scales, including a sycophancy trade-off where stronger instruction-following models are more susceptible to persuasion. We further show that lightweight inference-time interventions can partially restore moral stability. These results demonstrate that moral alignment alone is insufficient and that moral robustness is a necessary criterion for the responsible deployment of VLMs.
Agentic Reasoning for Large Language Models
Jan 18, 2026Reasoning is a fundamental cognitive process underlying inference, problem-solving, and decision-making. While large language models (LLMs) demonstrate strong reasoning capabilities in closed-world settings, they struggle in open-ended and dynamic environments. Agentic reasoning marks a paradigm shift by reframing LLMs as autonomous agents that plan, act, and learn through continual interaction. In this survey, we organize agentic reasoning along three complementary dimensions. First, we characterize environmental dynamics through three layers: foundational agentic reasoning, which establishes core single-agent capabilities including planning, tool use, and search in stable environments; self-evolving agentic reasoning, which studies how agents refine these capabilities through feedback, memory, and adaptation; and collective multi-agent reasoning, which extends intelligence to collaborative settings involving coordination, knowledge sharing, and shared goals. Across these layers, we distinguish in-context reasoning, which scales test-time interaction through structured orchestration, from post-training reasoning, which optimizes behaviors via reinforcement learning and supervised fine-tuning. We further review representative agentic reasoning frameworks across real-world applications and benchmarks, including science, robotics, healthcare, autonomous research, and mathematics. This survey synthesizes agentic reasoning methods into a unified roadmap bridging thought and action, and outlines open challenges and future directions, including personalization, long-horizon interaction, world modeling, scalable multi-agent training, and governance for real-world deployment.
AdaFuse: Adaptive Ensemble Decoding with Test-Time Scaling for LLMs
Jan 09, 2026Large language models (LLMs) exhibit complementary strengths arising from differences in pretraining data, model architectures, and decoding behaviors. Inference-time ensembling provides a practical way to combine these capabilities without retraining. However, existing ensemble approaches suffer from fundamental limitations. Most rely on fixed fusion granularity, which lacks the flexibility required for mid-generation adaptation and fails to adapt to different generation characteristics across tasks. To address these challenges, we propose AdaFuse, an adaptive ensemble decoding framework that dynamically selects semantically appropriate fusion units during generation. Rather than committing to a fixed granularity, AdaFuse adjusts fusion behavior on the fly based on the decoding context, with words serving as basic building blocks for alignment. To be specific, we introduce an uncertainty-based criterion to decide whether to apply ensembling at each decoding step. Under confident decoding states, the model continues generation directly. In less certain states, AdaFuse invokes a diversity-aware scaling strategy to explore alternative candidate continuations and inform ensemble decisions. This design establishes a synergistic interaction between adaptive ensembling and test-time scaling, where ensemble decisions guide targeted exploration, and the resulting diversity in turn strengthens ensemble quality. Experiments on open-domain question answering, arithmetic reasoning, and machine translation demonstrate that AdaFuse consistently outperforms strong ensemble baselines, achieving an average relative improvement of 6.88%. The code is available at https://github.com/CCM0111/AdaFuse.
Mem-Gallery: Benchmarking Multimodal Long-Term Conversational Memory for MLLM Agents
Jan 07, 2026Long-term memory is a critical capability for multimodal large language model (MLLM) agents, particularly in conversational settings where information accumulates and evolves over time. However, existing benchmarks either evaluate multi-session memory in text-only conversations or assess multimodal understanding within localized contexts, failing to evaluate how multimodal memory is preserved, organized, and evolved across long-term conversational trajectories. Thus, we introduce Mem-Gallery, a new benchmark for evaluating multimodal long-term conversational memory in MLLM agents. Mem-Gallery features high-quality multi-session conversations grounded in both visual and textual information, with long interaction horizons and rich multimodal dependencies. Building on this dataset, we propose a systematic evaluation framework that assesses key memory capabilities along three functional dimensions: memory extraction and test-time adaptation, memory reasoning, and memory knowledge management. Extensive benchmarking across thirteen memory systems reveals several key findings, highlighting the necessity of explicit multimodal information retention and memory organization, the persistent limitations in memory reasoning and knowledge management, as well as the efficiency bottleneck of current models.
Flow Matching Meets Biology and Life Science: A Survey
Jul 23, 2025Over the past decade, advances in generative modeling, such as generative adversarial networks, masked autoencoders, and diffusion models, have significantly transformed biological research and discovery, enabling breakthroughs in molecule design, protein generation, drug discovery, and beyond. At the same time, biological applications have served as valuable testbeds for evaluating the capabilities of generative models. Recently, flow matching has emerged as a powerful and efficient alternative to diffusion-based generative modeling, with growing interest in its application to problems in biology and life sciences. This paper presents the first comprehensive survey of recent developments in flow matching and its applications in biological domains. We begin by systematically reviewing the foundations and variants of flow matching, and then categorize its applications into three major areas: biological sequence modeling, molecule generation and design, and peptide and protein generation. For each, we provide an in-depth review of recent progress. We also summarize commonly used datasets and software tools, and conclude with a discussion of potential future directions. The corresponding curated resources are available at https://github.com/Violet24K/Awesome-Flow-Matching-Meets-Biology.
PLANETALIGN: A Comprehensive Python Library for Benchmarking Network Alignment
May 27, 2025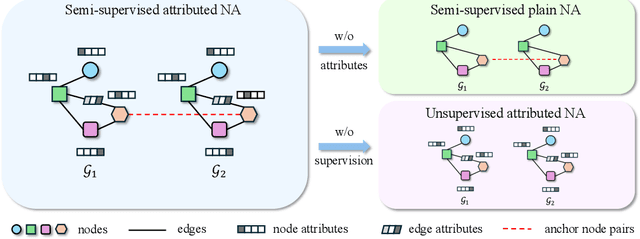
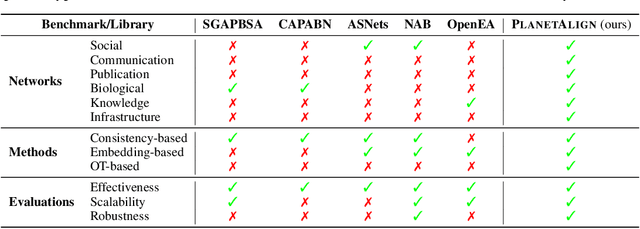
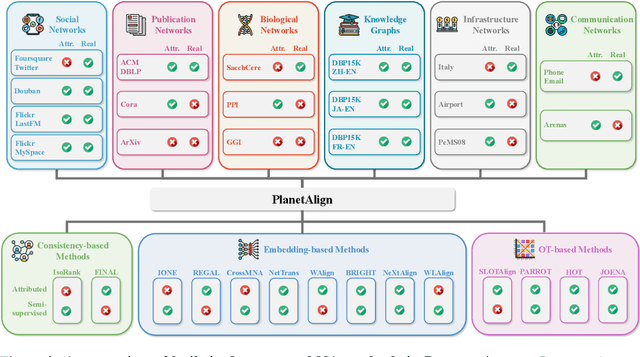
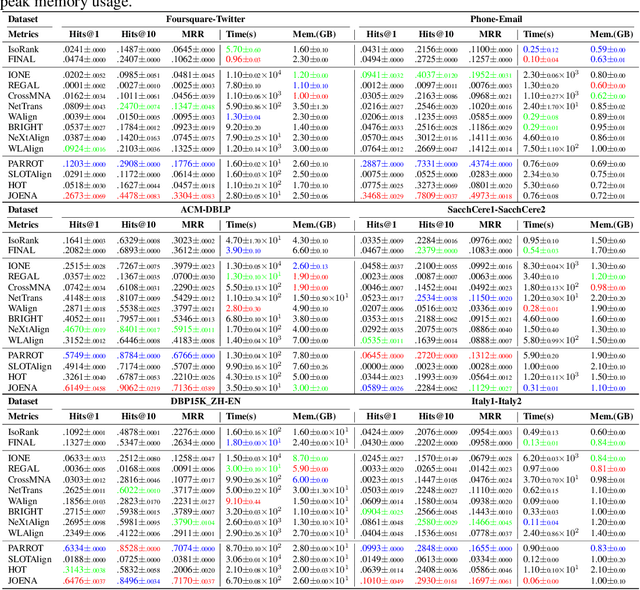
Network alignment (NA) aims to identify node correspondence across different networks and serves as a critical cornerstone behind various downstream multi-network learning tasks. Despite growing research in NA, there lacks a comprehensive library that facilitates the systematic development and benchmarking of NA methods. In this work, we introduce PLANETALIGN, a comprehensive Python library for network alignment that features a rich collection of built-in datasets, methods, and evaluation pipelines with easy-to-use APIs. Specifically, PLANETALIGN integrates 18 datasets and 14 NA methods with extensible APIs for easy use and development of NA methods. Our standardized evaluation pipeline encompasses a wide range of metrics, enabling a systematic assessment of the effectiveness, scalability, and robustness of NA methods. Through extensive comparative studies, we reveal practical insights into the strengths and limitations of existing NA methods. We hope that PLANETALIGN can foster a deeper understanding of the NA problem and facilitate the development and benchmarking of more effective, scalable, and robust methods in the future. The source code of PLANETALIGN is available at https://github.com/yq-leo/PlanetAlign.
Breaking Silos: Adaptive Model Fusion Unlocks Better Time Series Forecasting
May 24, 2025Time-series forecasting plays a critical role in many real-world applications. Although increasingly powerful models have been developed and achieved superior results on benchmark datasets, through a fine-grained sample-level inspection, we find that (i) no single model consistently outperforms others across different test samples, but instead (ii) each model excels in specific cases. These findings prompt us to explore how to adaptively leverage the distinct strengths of various forecasting models for different samples. We introduce TimeFuse, a framework for collective time-series forecasting with sample-level adaptive fusion of heterogeneous models. TimeFuse utilizes meta-features to characterize input time series and trains a learnable fusor to predict optimal model fusion weights for any given input. The fusor can leverage samples from diverse datasets for joint training, allowing it to adapt to a wide variety of temporal patterns and thus generalize to new inputs, even from unseen datasets. Extensive experiments demonstrate the effectiveness of TimeFuse in various long-/short-term forecasting tasks, achieving near-universal improvement over the state-of-the-art individual models. Code is available at https://github.com/ZhiningLiu1998/TimeFuse.