 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelfElicit: Your Language Model Secretly Knows Where is the Relevant Evidence
Feb 12, 2025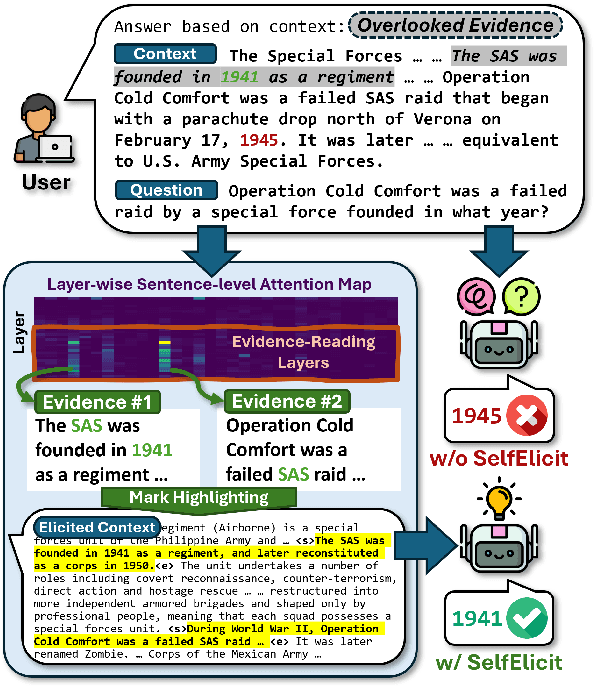
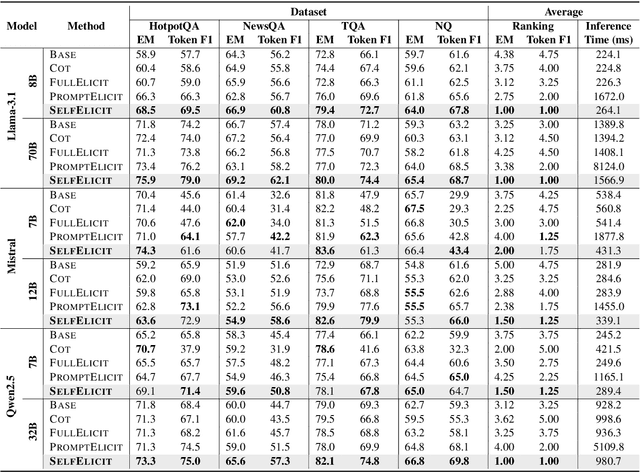
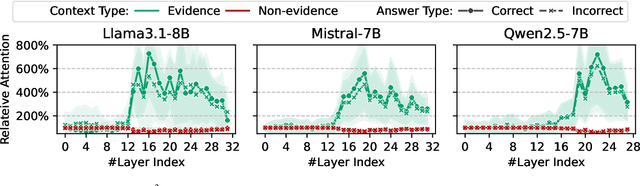
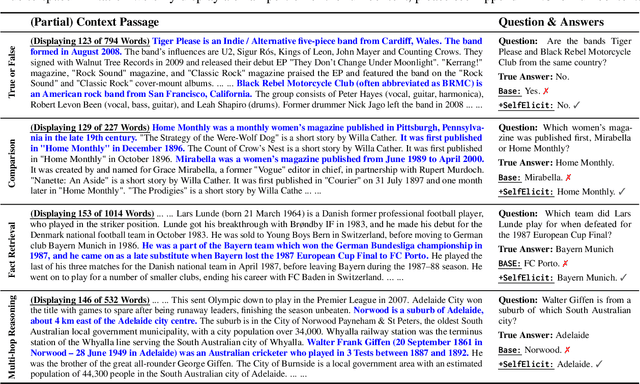
Providing Language Models (LMs) with relevant evidence in the context (either via retrieval or user-provided) can significantly improve their ability to provide factually correct grounded responses. However, recent studies have found that LMs often struggle to fully comprehend and utilize key evidence from the context, especially when it contains noise and irrelevant information - an issue common in real-world scenarios. To address this, we propose SelfElicit, an inference-time approach that helps LMs focus on key contextual evidence through self-guided explicit highlighting. By leveraging the inherent evidence-finding capabilities of LMs using the attention scores of deeper layers, our method automatically identifies and emphasizes key evidence within the input context, facilitating more accurate and factually grounded responses without additional training or iterative prompting. We demonstrate that SelfElicit brings consistent and significant improvement on multiple evidence-based QA tasks for various LM families while maintaining computational efficiency. Our code and documentation are available at https://github.com/ZhiningLiu1998/SelfElicit.
Context-Aware Clustering using Large Language Models
May 02, 2024Despite the remarkable success of Large Language Models (LLMs) in text understanding and generation, their potential for text clustering tasks remains underexplored. We observed that powerful closed-source LLMs provide good quality clusterings of entity sets but are not scalable due to the massive compute power required and the associated costs. Thus, we propose CACTUS (Context-Aware ClusTering with aUgmented triplet losS), a systematic approach that leverages open-source LLMs for efficient and effective supervised clustering of entity subsets, particularly focusing on text-based entities. Existing text clustering methods fail to effectively capture the context provided by the entity subset. Moreover, though there are several language modeling based approaches for clustering, very few are designed for the task of supervised clustering. This paper introduces a novel approach towards clustering entity subsets using LLMs by capturing context via a scalable inter-entity attention mechanism. We propose a novel augmented triplet loss function tailored for supervised clustering, which addresses the inherent challenges of directly applying the triplet loss to this problem. Furthermore, we introduce a self-supervised clustering task based on text augmentation techniques to improve the generalization of our model. For evaluation, we collect ground truth clusterings from a closed-source LLM and transfer this knowledge to an open-source LLM under the supervised clustering framework, allowing a faster and cheaper open-source model to perform the same task. Experiments on various e-commerce query and product clustering datasets demonstrate that our proposed approach significantly outperforms existing unsupervised and supervised baselines under various external clustering evaluation metrics.
Neural Augmentation of Kalman Filter with Hypernetwork for Channel Tracking
Sep 26, 2021
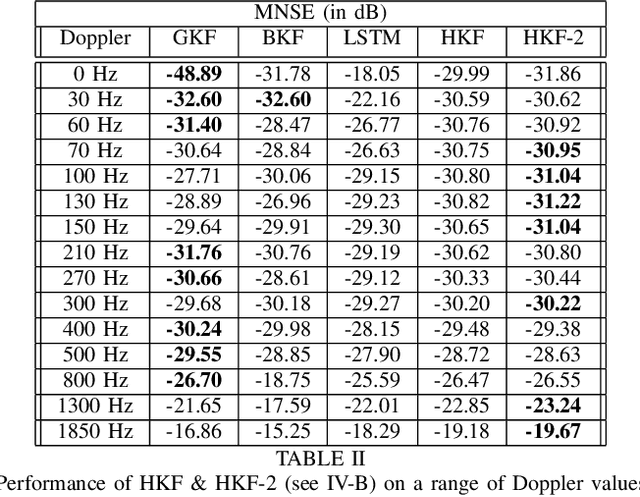
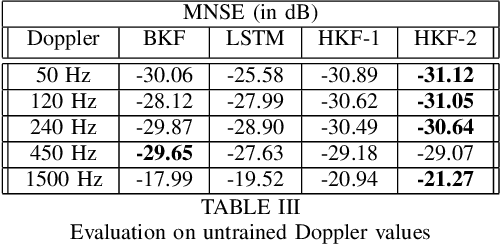
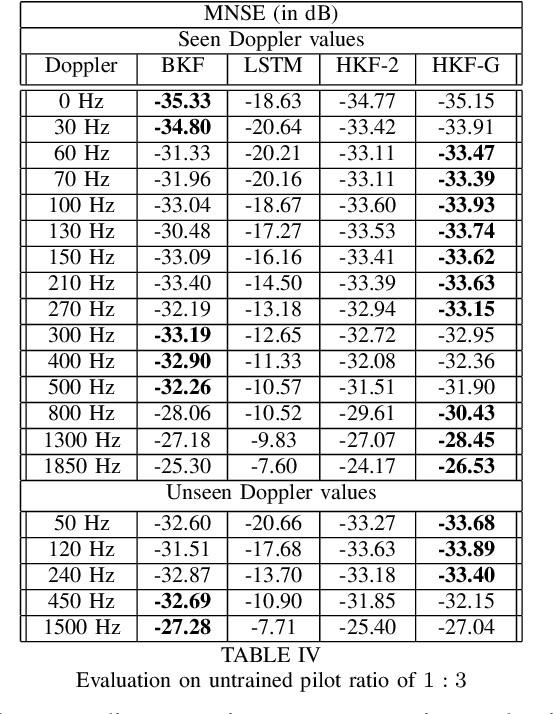
We propose Hypernetwork Kalman Filter (HKF) for tracking applications with multiple different dynamics. The HKF combines generalization power of Kalman filters with expressive power of neural networks. Instead of keeping a bank of Kalman filters and choosing one based on approximating the actual dynamics, HKF adapts itself to each dynamics based on the observed sequence. Through extensive experiments on CDL-B channel model, we show that the HKF can be used for tracking the channel over a wide range of Doppler values, matching Kalman filter performance with genie Doppler information. At high Doppler values, it achieves around 2dB gain over genie Kalman filter. The HKF generalizes well to unseen Doppler, SNR values and pilot patterns unlike LSTM, which suffers from severe performance degradation.
A White Paper on Neural Network Quantization
Jun 15, 2021
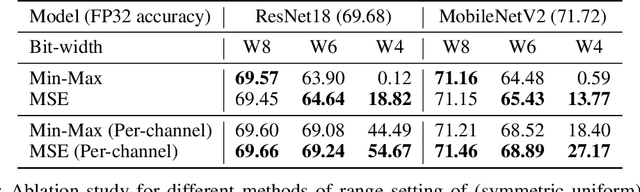
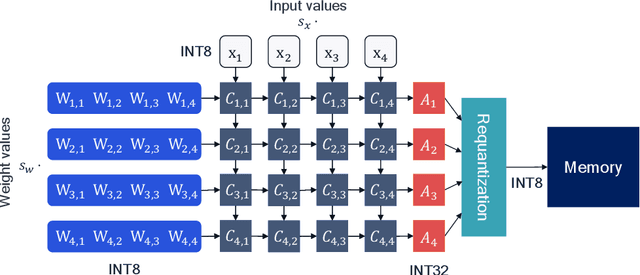
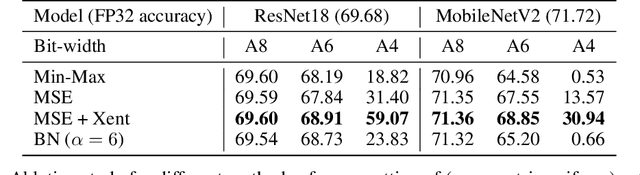
While neural networks have advanced the frontiers in many applications, they often come at a high computational cost. Reducing the power and latency of neural network inference is key if we want to integrate modern networks into edge devices with strict power and compute requirements. Neural network quantization is one of the most effective ways of achieving these savings but the additional noise it induces can lead to accuracy degradation. In this white paper, we introduce state-of-the-art algorithms for mitigating the impact of quantization noise on the network's performance while maintaining low-bit weights and activations. We start with a hardware motivated introduction to quantization and then consider two main classes of algorithms: Post-Training Quantization (PTQ) and Quantization-Aware-Training (QAT). PTQ requires no re-training or labelled data and is thus a lightweight push-button approach to quantization. In most cases, PTQ is sufficient for achieving 8-bit quantization with close to floating-point accuracy. QAT requires fine-tuning and access to labeled training data but enables lower bit quantization with competitive results. For both solutions, we provide tested pipelines based on existing literature and extensive experimentation that lead to state-of-the-art performance for common deep learning models and tasks.
Bayesian Bits: Unifying Quantization and Pruning
May 15, 2020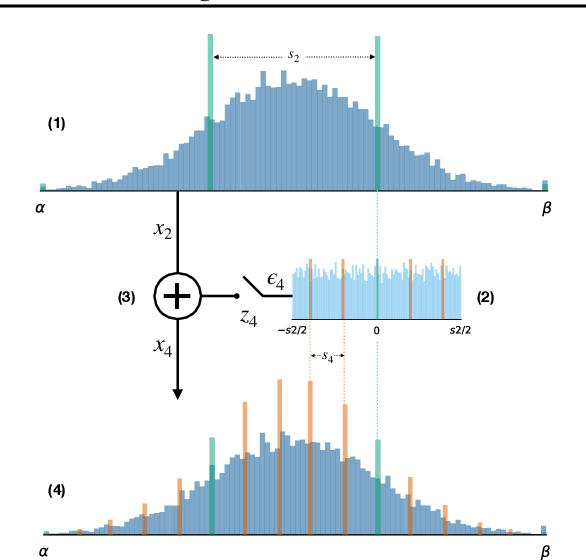
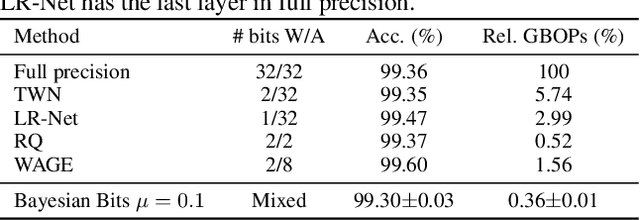
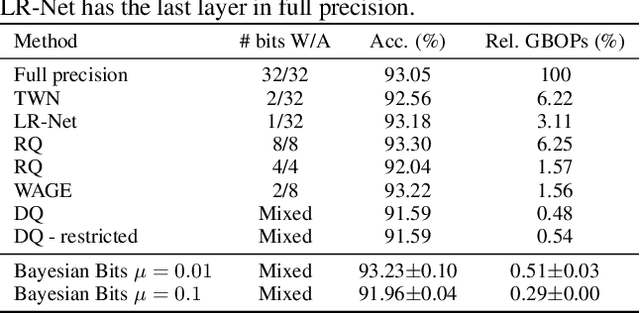
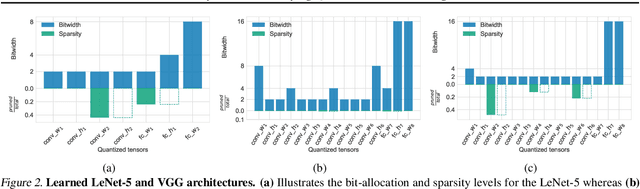
We introduce Bayesian Bits, a practical method for joint mixed precision quantization and pruning through gradient based optimization. Bayesian Bits employs a novel decomposition of the quantization operation, which sequentially considers doubling the bit width. At each new bit width, the residual error between the full precision value and the previously rounded value is quantized. We then decide whether or not to add this quantized residual error for a higher effective bit width and lower quantization noise. By starting with a power-of-two bit width, this decomposition will always produce hardware-friendly configurations, and through an additional 0-bit option, serves as a unified view of pruning and quantization. Bayesian Bits then introduces learnable stochastic gates, which collectively control the bit width of the given tensor. As a result, we can obtain low bit solutions by performing approximate inference over the gates, with prior distributions that encourage most of them to be switched off. We further show that, under some assumptions, L0 regularization of the network parameters corresponds to a specific instance of the aforementioned framework. We experimentally validate our proposed method on several benchmark datasets and show that we can learn pruned, mixed precision networks that provide a better trade-off between accuracy and efficiency than their static bit width equivalents.
Up or Down? Adaptive Rounding for Post-Training Quantization
Apr 22, 2020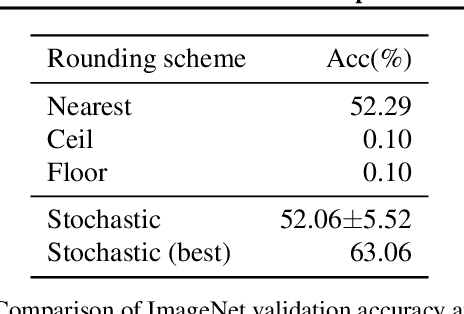
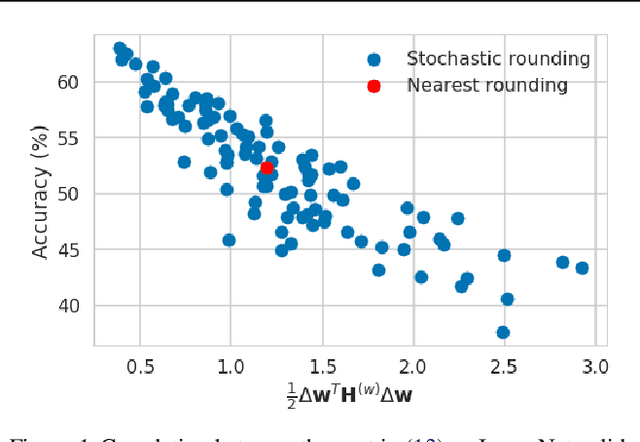
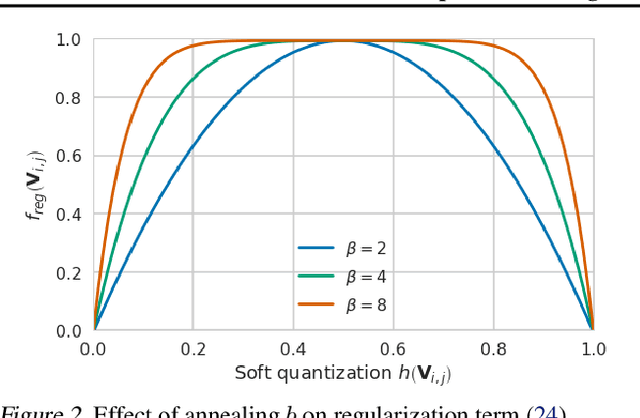
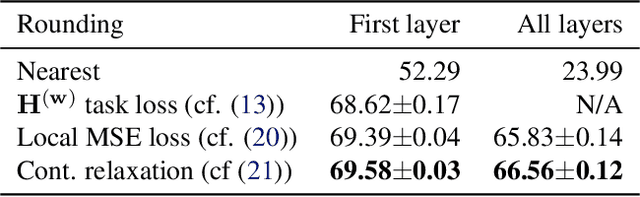
When quantizing neural networks, assigning each floating-point weight to its nearest fixed-point value is the predominant approach. We find that, perhaps surprisingly, this is not the best we can do. In this paper, we propose AdaRound, a better weight-rounding mechanism for post-training quantization that adapts to the data and the task loss. AdaRound is fast, does not require fine-tuning of the network, and only uses a small amount of unlabelled data. We start by theoretically analyzing the rounding problem for a pre-trained neural network. By approximating the task loss with a Taylor series expansion, the rounding task is posed as a quadratic unconstrained binary optimization problem. We simplify this to a layer-wise local loss and propose to optimize this loss with a soft relaxation. AdaRound not only outperforms rounding-to-nearest by a significant margin but also establishes a new state-of-the-art for post-training quantization on several networks and tasks. Without fine-tuning, we can quantize the weights of Resnet18 and Resnet50 to 4 bits while staying within an accuracy loss of 1%.
Class-Conditional Compression and Disentanglement: Bridging the Gap between Neural Networks and Naive Bayes Classifiers
Jun 06, 2019In this draft, which reports on work in progress, we 1) adapt the information bottleneck functional by replacing the compression term by class-conditional compression, 2) relax this functional using a variational bound related to class-conditional disentanglement, 3) consider this functional as a training objective for stochastic neural networks, and 4) show that the latent representations are learned such that they can be used in a naive Bayes classifier. We continue by suggesting a series of experiments along the lines of Nonlinear In-formation Bottleneck [Kolchinsky et al., 2018], Deep Variational Information Bottleneck [Alemi et al., 2017], and Information Dropout [Achille and Soatto, 2018]. We furthermore suggest a neural network where the decoder architecture is a parameterized naive Bayes decoder.
Learning Representations for Neural Network-Based Classification Using the Information Bottleneck Principle
Jul 12, 2018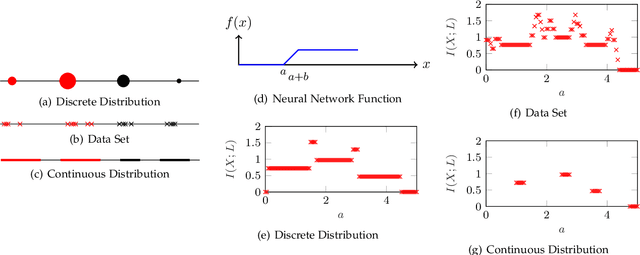
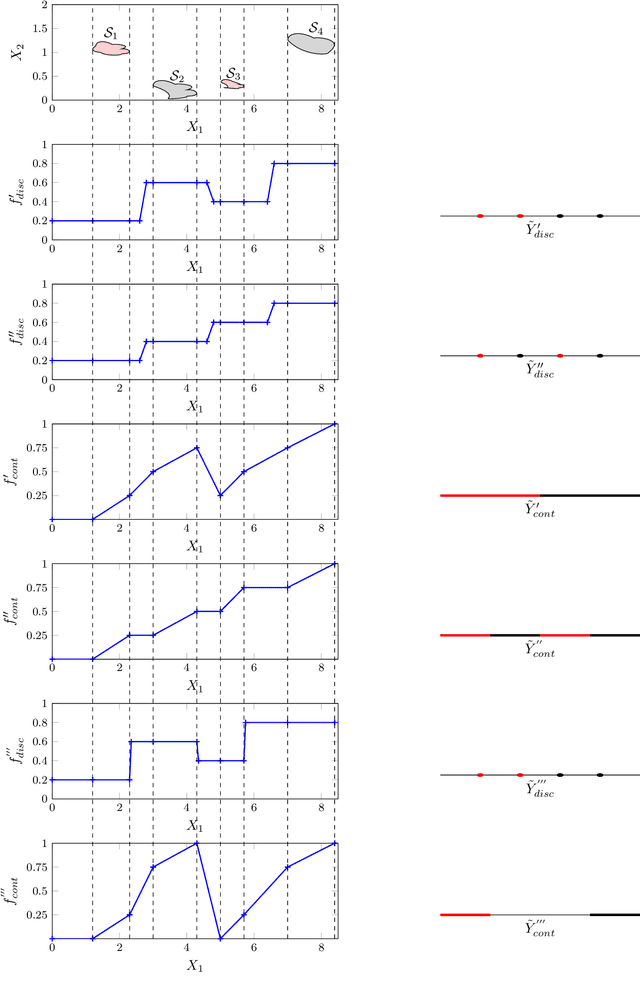
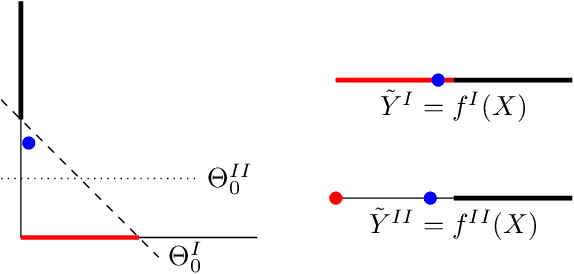
In this theory paper, we investigate training deep neural networks (DNNs) for classification via minimizing the information bottleneck (IB) functional. We show that the resulting optimization problem suffers from two severe issues: First, for deterministic DNNs, either the IB functional is infinite for almost all values of network parameters, making the optimization problem ill-posed, or it is piecewise constant, hence not admitting gradient-based optimization methods. Second, the invariance of the IB functional under bijections prevents it from capturing desirable properties for classification, such as robustness, architectural simplicity, and simplicity of the learned representation. We argue that these issues are partly resolved for stochastic DNNs, DNNs that include a (hard or soft) decision rule, or by replacing the IB functional with related, but more well-behaved cost functions. We conclude that recent successes reported about training DNNs using the IB framework must be attributed to such solutions. As a side effect, our results imply limitations of the IB framework for the analysis of DNNs. We also note that rather than trying to repair the inherent problems in IB functional, a better approach may be to design regularizers on latent representation enforcing the desired properties directly.
Co-Clustering via Information-Theoretic Markov Aggregation
Jun 15, 2018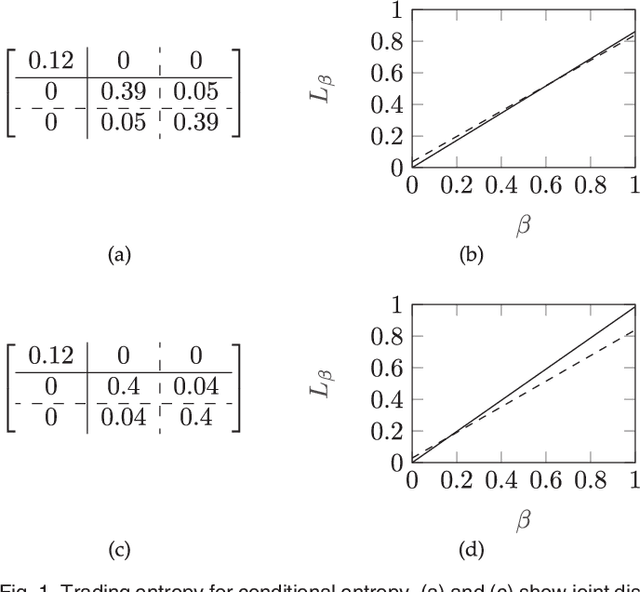
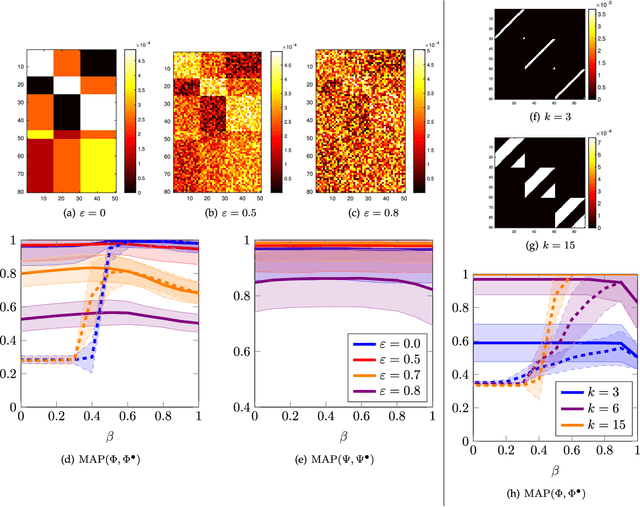
We present an information-theoretic cost function for co-clustering, i.e., for simultaneous clustering of two sets based on similarities between their elements. By constructing a simple random walk on the corresponding bipartite graph, our cost function is derived from a recently proposed generalized framework for information-theoretic Markov chain aggregation. The goal of our cost function is to minimize relevant information loss, hence it connects to the information bottleneck formalism. Moreover, via the connection to Markov aggregation, our cost function is not ad hoc, but inherits its justification from the operational qualities associated with the corresponding Markov aggregation problem. We furthermore show that, for appropriate parameter settings, our cost function is identical to well-known approaches from the literature, such as Information-Theoretic Co-Clustering of Dhillon et al. Hence, understanding the influence of this parameter admits a deeper understanding of the relationship between previously proposed information-theoretic cost functions. We highlight some strengths and weaknesses of the cost function for different parameters. We also illustrate the performance of our cost function, optimized with a simple sequential heuristic, on several synthetic and real-world data sets, including the Newsgroup20 and the MovieLens100k data sets.
Understanding Individual Neuron Importance Using Information Theory
Apr 18, 2018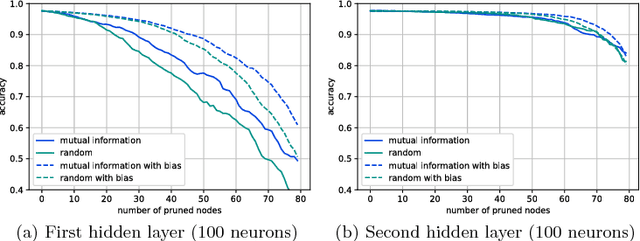
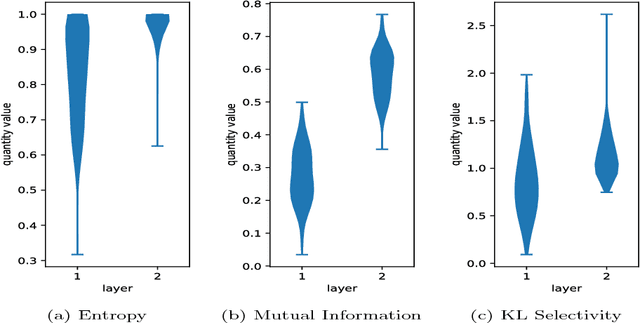
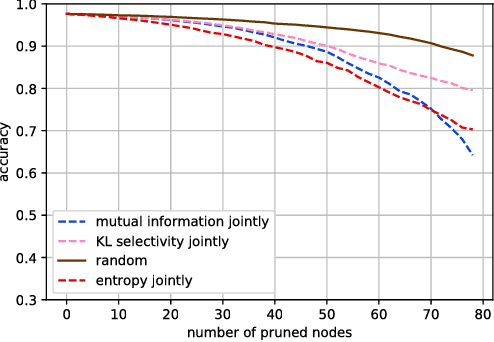
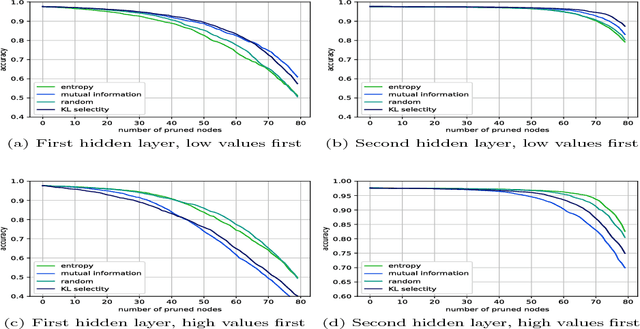
In this work, we characterize the outputs of individual neurons in a trained feed-forward neural network by entropy, mutual information with the class variable, and a class selectivity measure based on Kullback-Leibler divergence. By cumulatively ablating neurons in the network, we connect these information-theoretic measures to the impact their removal has on classification performance on the test set. We observe that, looking at the neural network as a whole, none of these measures is a good indicator for classification performance, thus confirming recent results by Morcos et al. However, looking at specific layers separately, both mutual information and class selectivity are positively correlated with classification performance. We thus conclude that it is ill-advised to compare these measures across layers, and that different layers may be most appropriately characterized by different measures. We then discuss pruning neurons from neural networks to reduce computational complexity of inference. Drawing from our results, we perform pruning based on information-theoretic measures on a fully connected feed-forward neural network with two hidden layers trained on MNIST dataset and compare the results to a recently proposed pruning method. We furthermore show that the common practice of re-training after pruning can partly be obviated by a surgery step called bias balancing, without incurring significant performance degradation.