 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Plugin Method for Metric Optimization of Black-Box Models
Mar 03, 2025Many machine learning algorithms and classifiers are available only via API queries as a ``black-box'' -- that is, the downstream user has no ability to change, re-train, or fine-tune the model on a particular target distribution. Indeed, the downstream user may not even have knowledge of the \emph{original} training distribution or performance metric used to construct and optimize the black-box model. We propose a simple and efficient method, Plugin, which \emph{post-processes} arbitrary multiclass predictions from any black-box classifier in order to simultaneously (1) adapt these predictions to a target distribution; and (2) optimize a particular metric of the confusion matrix. Importantly, Plugin is a completely \textit{post-hoc} method which does not rely on feature information, only requires a small amount of probabilistic predictions along with their corresponding true label, and optimizes metrics by querying. We empirically demonstrate that Plugin is both broadly applicable and has performance competitive with related methods on a variety of tabular and language tasks.
Unleashing the Power of LLMs as Multi-Modal Encoders for Text and Graph-Structured Data
Oct 15, 2024



Graph-structured information offers rich contextual information that can enhance language models by providing structured relationships and hierarchies, leading to more expressive embeddings for various applications such as retrieval, question answering, and classification. However, existing methods for integrating graph and text embeddings, often based on Multi-layer Perceptrons (MLPs) or shallow transformers, are limited in their ability to fully exploit the heterogeneous nature of these modalities. To overcome this, we propose Janus, a simple yet effective framework that leverages Large Language Models (LLMs) to jointly encode text and graph data. Specifically, Janus employs an MLP adapter to project graph embeddings into the same space as text embeddings, allowing the LLM to process both modalities jointly. Unlike prior work, we also introduce contrastive learning to align the graph and text spaces more effectively, thereby improving the quality of learned joint embeddings. Empirical results across six datasets spanning three tasks, knowledge graph-contextualized question answering, graph-text pair classification, and retrieval, demonstrate that Janus consistently outperforms existing baselines, achieving significant improvements across multiple datasets, with gains of up to 11.4% in QA tasks. These results highlight Janus's effectiveness in integrating graph and text data. Ablation studies further validate the effectiveness of our method.
All Against Some: Efficient Integration of Large Language Models for Message Passing in Graph Neural Networks
Jul 20, 2024



Graph Neural Networks (GNNs) have attracted immense attention in the past decade due to their numerous real-world applications built around graph-structured data. On the other hand, Large Language Models (LLMs) with extensive pretrained knowledge and powerful semantic comprehension abilities have recently shown a remarkable ability to benefit applications using vision and text data. In this paper, we investigate how LLMs can be leveraged in a computationally efficient fashion to benefit rich graph-structured data, a modality relatively unexplored in LLM literature. Prior works in this area exploit LLMs to augment every node features in an ad-hoc fashion (not scalable for large graphs), use natural language to describe the complex structural information of graphs, or perform computationally expensive finetuning of LLMs in conjunction with GNNs. We propose E-LLaGNN (Efficient LLMs augmented GNNs), a framework with an on-demand LLM service that enriches message passing procedure of graph learning by enhancing a limited fraction of nodes from the graph. More specifically, E-LLaGNN relies on sampling high-quality neighborhoods using LLMs, followed by on-demand neighborhood feature enhancement using diverse prompts from our prompt catalog, and finally information aggregation using message passing from conventional GNN architectures. We explore several heuristics-based active node selection strategies to limit the computational and memory footprint of LLMs when handling millions of nodes. Through extensive experiments & ablation on popular graph benchmarks of varying scales (Cora, PubMed, ArXiv, & Products), we illustrate the effectiveness of our E-LLaGNN framework and reveal many interesting capabilities such as improved gradient flow in deep GNNs, LLM-free inference ability etc.
Context-Aware Clustering using Large Language Models
May 02, 2024Despite the remarkable success of Large Language Models (LLMs) in text understanding and generation, their potential for text clustering tasks remains underexplored. We observed that powerful closed-source LLMs provide good quality clusterings of entity sets but are not scalable due to the massive compute power required and the associated costs. Thus, we propose CACTUS (Context-Aware ClusTering with aUgmented triplet losS), a systematic approach that leverages open-source LLMs for efficient and effective supervised clustering of entity subsets, particularly focusing on text-based entities. Existing text clustering methods fail to effectively capture the context provided by the entity subset. Moreover, though there are several language modeling based approaches for clustering, very few are designed for the task of supervised clustering. This paper introduces a novel approach towards clustering entity subsets using LLMs by capturing context via a scalable inter-entity attention mechanism. We propose a novel augmented triplet loss function tailored for supervised clustering, which addresses the inherent challenges of directly applying the triplet loss to this problem. Furthermore, we introduce a self-supervised clustering task based on text augmentation techniques to improve the generalization of our model. For evaluation, we collect ground truth clusterings from a closed-source LLM and transfer this knowledge to an open-source LLM under the supervised clustering framework, allowing a faster and cheaper open-source model to perform the same task. Experiments on various e-commerce query and product clustering datasets demonstrate that our proposed approach significantly outperforms existing unsupervised and supervised baselines under various external clustering evaluation metrics.
An Interpretable Ensemble of Graph and Language Models for Improving Search Relevance in E-Commerce
Mar 01, 2024



The problem of search relevance in the E-commerce domain is a challenging one since it involves understanding the intent of a user's short nuanced query and matching it with the appropriate products in the catalog. This problem has traditionally been addressed using language models (LMs) and graph neural networks (GNNs) to capture semantic and inter-product behavior signals, respectively. However, the rapid development of new architectures has created a gap between research and the practical adoption of these techniques. Evaluating the generalizability of these models for deployment requires extensive experimentation on complex, real-world datasets, which can be non-trivial and expensive. Furthermore, such models often operate on latent space representations that are incomprehensible to humans, making it difficult to evaluate and compare the effectiveness of different models. This lack of interpretability hinders the development and adoption of new techniques in the field. To bridge this gap, we propose Plug and Play Graph LAnguage Model (PP-GLAM), an explainable ensemble of plug and play models. Our approach uses a modular framework with uniform data processing pipelines. It employs additive explanation metrics to independently decide whether to include (i) language model candidates, (ii) GNN model candidates, and (iii) inter-product behavioral signals. For the task of search relevance, we show that PP-GLAM outperforms several state-of-the-art baselines as well as a proprietary model on real-world multilingual, multi-regional e-commerce datasets. To promote better model comprehensibility and adoption, we also provide an analysis of the explainability and computational complexity of our model. We also provide the public codebase and provide a deployment strategy for practical implementation.
Hyperbolic Graph Neural Networks at Scale: A Meta Learning Approach
Oct 29, 2023



The progress in hyperbolic neural networks (HNNs) research is hindered by their absence of inductive bias mechanisms, which are essential for generalizing to new tasks and facilitating scalable learning over large datasets. In this paper, we aim to alleviate these issues by learning generalizable inductive biases from the nodes' local subgraph and transfer them for faster learning over new subgraphs with a disjoint set of nodes, edges, and labels in a few-shot setting. We introduce a novel method, Hyperbolic GRAph Meta Learner (H-GRAM), that, for the tasks of node classification and link prediction, learns transferable information from a set of support local subgraphs in the form of hyperbolic meta gradients and label hyperbolic protonets to enable faster learning over a query set of new tasks dealing with disjoint subgraphs. Furthermore, we show that an extension of our meta-learning framework also mitigates the scalability challenges seen in HNNs faced by existing approaches. Our comparative analysis shows that H-GRAM effectively learns and transfers information in multiple challenging few-shot settings compared to other state-of-the-art baselines. Additionally, we demonstrate that, unlike standard HNNs, our approach is able to scale over large graph datasets and improve performance over its Euclidean counterparts.
Complex Logical Reasoning over Knowledge Graphs using Large Language Models
May 02, 2023Reasoning over knowledge graphs (KGs) is a challenging task that requires a deep understanding of the complex relationships between entities and the underlying logic of their relations. Current approaches rely on learning geometries to embed entities in vector space for logical query operations, but they suffer from subpar performance on complex queries and dataset-specific representations. In this paper, we propose a novel decoupled approach, Language-guided Abstract Reasoning over Knowledge graphs (LARK), that formulates complex KG reasoning as a combination of contextual KG search and abstract logical query reasoning, to leverage the strengths of graph extraction algorithms and large language models (LLM), respectively. Our experiments demonstrate that the proposed approach outperforms state-of-the-art KG reasoning methods on standard benchmark datasets across several logical query constructs, with significant performance gain for queries of higher complexity. Furthermore, we show that the performance of our approach improves proportionally to the increase in size of the underlying LLM, enabling the integration of the latest advancements in LLMs for logical reasoning over KGs. Our work presents a new direction for addressing the challenges of complex KG reasoning and paves the way for future research in this area.
Text Enriched Sparse Hyperbolic Graph Convolutional Networks
Jul 07, 2022

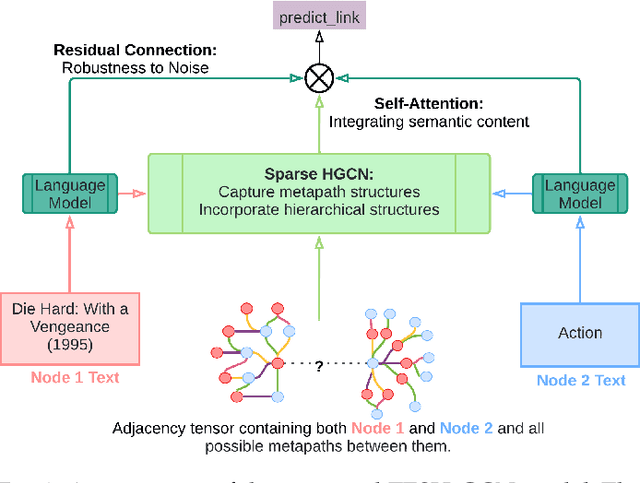
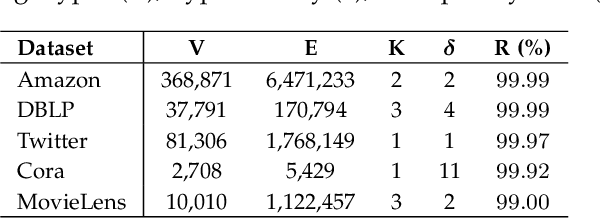
Heterogeneous networks, which connect informative nodes containing text with different edge types, are routinely used to store and process information in various real-world applications. Graph Neural Networks (GNNs) and their hyperbolic variants provide a promising approach to encode such networks in a low-dimensional latent space through neighborhood aggregation and hierarchical feature extraction, respectively. However, these approaches typically ignore metapath structures and the available semantic information. Furthermore, these approaches are sensitive to the noise present in the training data. To tackle these limitations, in this paper, we propose Text Enriched Sparse Hyperbolic Graph Convolution Network (TESH-GCN) to capture the graph's metapath structures using semantic signals and further improve prediction in large heterogeneous graphs. In TESH-GCN, we extract semantic node information, which successively acts as a connection signal to extract relevant nodes' local neighborhood and graph-level metapath features from the sparse adjacency tensor in a reformulated hyperbolic graph convolution layer. These extracted features in conjunction with semantic features from the language model (for robustness) are used for the final downstream task. Experiments on various heterogeneous graph datasets show that our model outperforms the current state-of-the-art approaches by a large margin on the task of link prediction. We also report a reduction in both the training time and model parameters compared to the existing hyperbolic approaches through a reformulated hyperbolic graph convolution. Furthermore, we illustrate the robustness of our model by experimenting with different levels of simulated noise in both the graph structure and text, and also, present a mechanism to explain TESH-GCN's prediction by analyzing the extracted metapaths.
Pseudo-Poincaré: A Unification Framework for Euclidean and Hyperbolic Graph Neural Networks
Jun 09, 2022



Hyperbolic neural networks have recently gained significant attention due to their promising results on several graph problems including node classification and link prediction. The primary reason for this success is the effectiveness of the hyperbolic space in capturing the inherent hierarchy of graph datasets. However, they are limited in terms of generalization, scalability, and have inferior performance when it comes to non-hierarchical datasets. In this paper, we take a completely orthogonal perspective for modeling hyperbolic networks. We use Poincar\'e disk to model the hyperbolic geometry and also treat it as if the disk itself is a tangent space at origin. This enables us to replace non-scalable M\"obius gyrovector operations with an Euclidean approximation, and thus simplifying the entire hyperbolic model to a Euclidean model cascaded with a hyperbolic normalization function. Our approach does not adhere to M\"obius math, yet it still works in the Riemannian manifold, hence we call it Pseudo-Poincar\'e framework. We applied our non-linear hyperbolic normalization to the current state-of-the-art homogeneous and multi-relational graph networks and demonstrate significant improvements in performance compared to both Euclidean and hyperbolic counterparts. The primary impact of this work lies in its ability to capture hierarchical features in the Euclidean space, and thus, can replace hyperbolic networks without loss in performance metrics while simultaneously leveraging the power of Euclidean networks such as interpretability and efficient execution of various model components.
Towards Scalable Hyperbolic Neural Networks using Taylor Series Approximations
Jun 07, 2022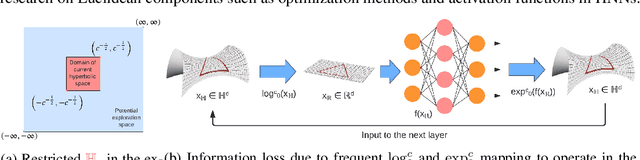
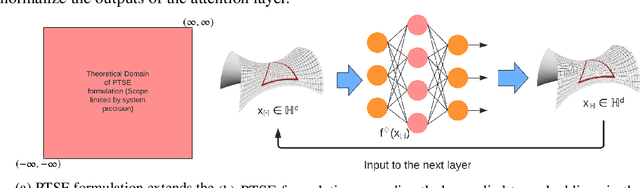
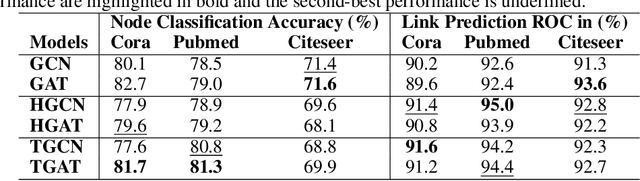
Hyperbolic networks have shown prominent improvements over their Euclidean counterparts in several areas involving hierarchical datasets in various domains such as computer vision, graph analysis, and natural language processing. However, their adoption in practice remains restricted due to (i) non-scalability on accelerated deep learning hardware, (ii) vanishing gradients due to the closure of hyperbolic space, and (iii) information loss due to frequent mapping between local tangent space and fully hyperbolic space. To tackle these issues, we propose the approximation of hyperbolic operators using Taylor series expansions, which allows us to reformulate the computationally expensive tangent and cosine hyperbolic functions into their polynomial equivariants which are more efficient. This allows us to retain the benefits of preserving the hierarchical anatomy of the hyperbolic space, while maintaining the scalability over current accelerated deep learning infrastructure. The polynomial formulation also enables us to utilize the advancements in Euclidean networks such as gradient clipping and ReLU activation to avoid vanishing gradients and remove errors due to frequent switching between tangent space and hyperbolic space. Our empirical evaluation on standard benchmarks in the domain of graph analysis and computer vision shows that our polynomial formulation is as scalable as Euclidean architectures, both in terms of memory and time complexity, while providing results as effective as hyperbolic models. Moreover, our formulation also shows a considerable improvement over its baselines due to our solution to vanishing gradients and information loss.