 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Plugin Method for Metric Optimization of Black-Box Models
Mar 03, 2025Many machine learning algorithms and classifiers are available only via API queries as a ``black-box'' -- that is, the downstream user has no ability to change, re-train, or fine-tune the model on a particular target distribution. Indeed, the downstream user may not even have knowledge of the \emph{original} training distribution or performance metric used to construct and optimize the black-box model. We propose a simple and efficient method, Plugin, which \emph{post-processes} arbitrary multiclass predictions from any black-box classifier in order to simultaneously (1) adapt these predictions to a target distribution; and (2) optimize a particular metric of the confusion matrix. Importantly, Plugin is a completely \textit{post-hoc} method which does not rely on feature information, only requires a small amount of probabilistic predictions along with their corresponding true label, and optimizes metrics by querying. We empirically demonstrate that Plugin is both broadly applicable and has performance competitive with related methods on a variety of tabular and language tasks.
Counterfactually Probing Language Identity in Multilingual Models
Oct 29, 2023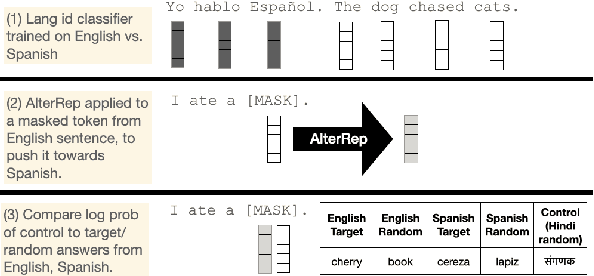
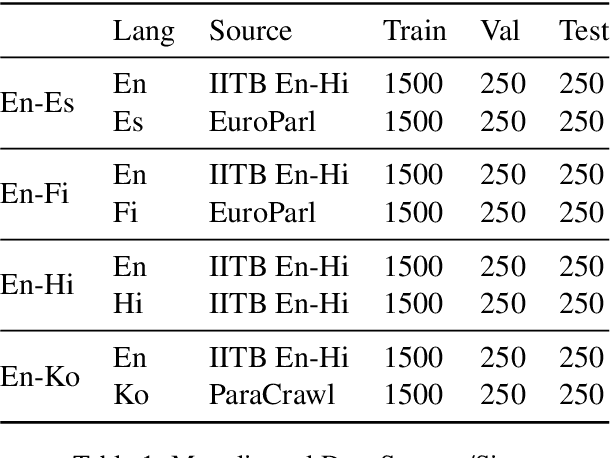
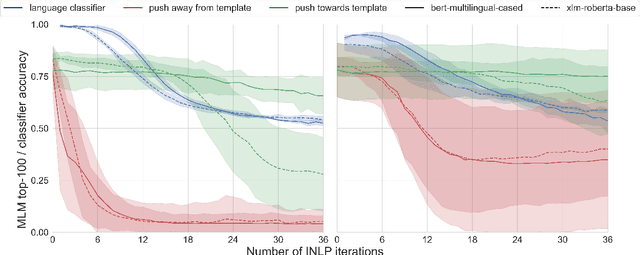
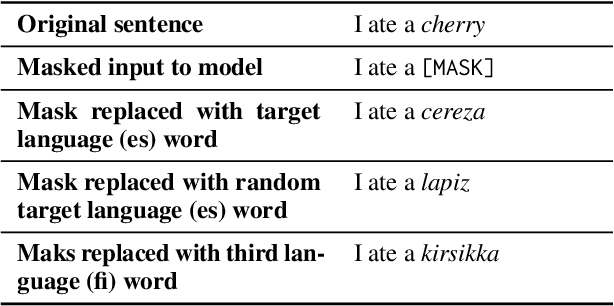
Techniques in causal analysis of language models illuminate how linguistic information is organized in LLMs. We use one such technique, AlterRep, a method of counterfactual probing, to explore the internal structure of multilingual models (mBERT and XLM-R). We train a linear classifier on a binary language identity task, to classify tokens between Language X and Language Y. Applying a counterfactual probing procedure, we use the classifier weights to project the embeddings into the null space and push the resulting embeddings either in the direction of Language X or Language Y. Then we evaluate on a masked language modeling task. We find that, given a template in Language X, pushing towards Language Y systematically increases the probability of Language Y words, above and beyond a third-party control language. But it does not specifically push the model towards translation-equivalent words in Language Y. Pushing towards Language X (the same direction as the template) has a minimal effect, but somewhat degrades these models. Overall, we take these results as further evidence of the rich structure of massive multilingual language models, which include both a language-specific and language-general component. And we show that counterfactual probing can be fruitfully applied to multilingual models.
Unit-based Speech-to-Speech Translation Without Parallel Data
May 24, 2023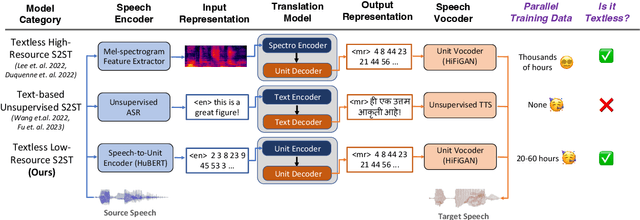
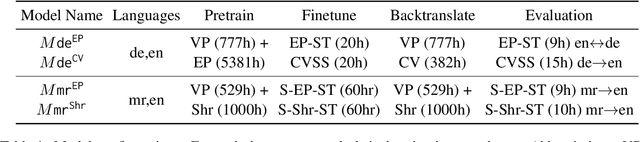
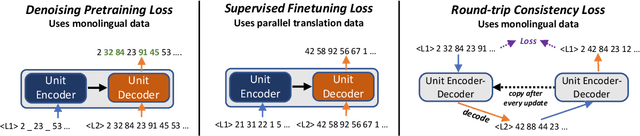
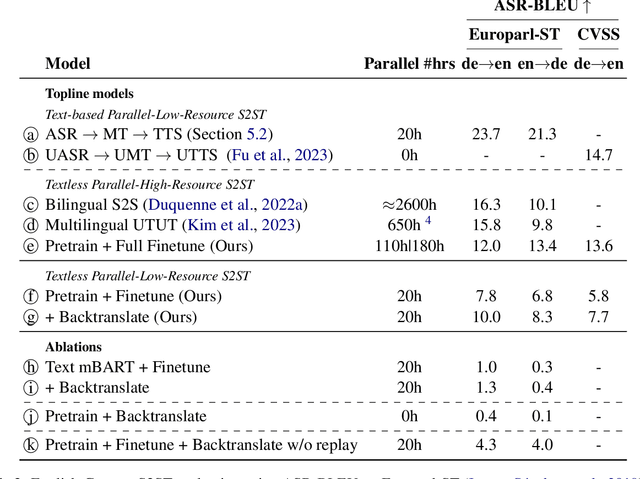
We propose an unsupervised speech-to-speech translation (S2ST) system that does not rely on parallel data between the source and target languages. Our approach maps source and target language speech signals into automatically discovered, discrete units and reformulates the problem as unsupervised unit-to-unit machine translation. We develop a three-step training procedure that involves (a) pre-training an unit-based encoder-decoder language model with a denoising objective (b) training it with word-by-word translated utterance pairs created by aligning monolingual text embedding spaces and (c) running unsupervised backtranslation bootstrapping off of the initial translation model. Our approach avoids mapping the speech signal into text and uses speech-to-unit and unit-to-speech models instead of automatic speech recognition and text to speech models. We evaluate our model on synthetic-speaker Europarl-ST English-German and German-English evaluation sets, finding that unit-based translation is feasible under this constrained scenario, achieving 9.29 ASR-BLEU in German to English and 8.07 in English to German.
TyDiP: A Dataset for Politeness Classification in Nine Typologically Diverse Languages
Nov 29, 2022We study politeness phenomena in nine typologically diverse languages. Politeness is an important facet of communication and is sometimes argued to be cultural-specific, yet existing computational linguistic study is limited to English. We create TyDiP, a dataset containing three-way politeness annotations for 500 examples in each language, totaling 4.5K examples. We evaluate how well multilingual models can identify politeness levels -- they show a fairly robust zero-shot transfer ability, yet fall short of estimated human accuracy significantly. We further study mapping the English politeness strategy lexicon into nine languages via automatic translation and lexicon induction, analyzing whether each strategy's impact stays consistent across languages. Lastly, we empirically study the complicated relationship between formality and politeness through transfer experiments. We hope our dataset will support various research questions and applications, from evaluating multilingual models to constructing polite multilingual agents.
CALCS 2021 Shared Task: Machine Translation for Code-Switched Data
Feb 19, 2022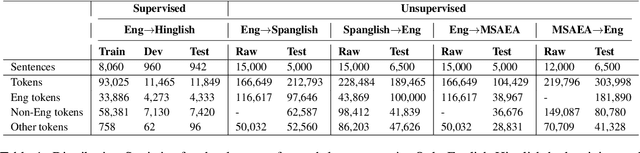
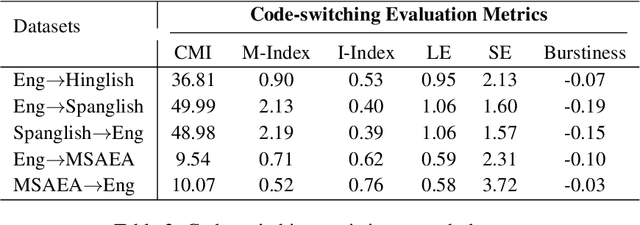

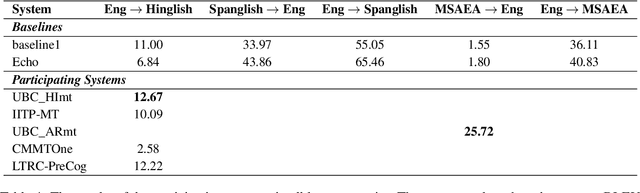
To date, efforts in the code-switching literature have focused for the most part on language identification, POS, NER, and syntactic parsing. In this paper, we address machine translation for code-switched social media data. We create a community shared task. We provide two modalities for participation: supervised and unsupervised. For the supervised setting, participants are challenged to translate English into Hindi-English (Eng-Hinglish) in a single direction. For the unsupervised setting, we provide the following language pairs: English and Spanish-English (Eng-Spanglish), and English and Modern Standard Arabic-Egyptian Arabic (Eng-MSAEA) in both directions. We share insights and challenges in curating the "into" code-switching language evaluation data. Further, we provide baselines for all language pairs in the shared task. The leaderboard for the shared task comprises 12 individual system submissions corresponding to 5 different teams. The best performance achieved is 12.67% BLEU score for English to Hinglish and 25.72% BLEU score for MSAEA to English.
Predicting the Performance of Multilingual NLP Models
Oct 17, 2021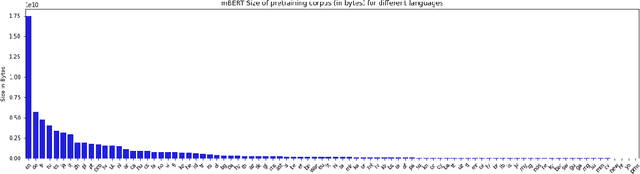
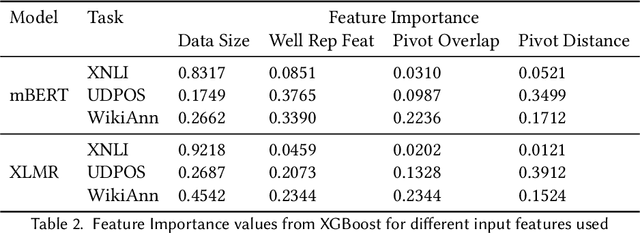
Recent advancements in NLP have given us models like mBERT and XLMR that can serve over 100 languages. The languages that these models are evaluated on, however, are very few in number, and it is unlikely that evaluation datasets will cover all the languages that these models support. Potential solutions to the costly problem of dataset creation are to translate datasets to new languages or use template-filling based techniques for creation. This paper proposes an alternate solution for evaluating a model across languages which make use of the existing performance scores of the model on languages that a particular task has test sets for. We train a predictor on these performance scores and use this predictor to predict the model's performance in different evaluation settings. Our results show that our method is effective in filling the gaps in the evaluation for an existing set of languages, but might require additional improvements if we want it to generalize to unseen languages.
GLUECoS : An Evaluation Benchmark for Code-Switched NLP
May 14, 2020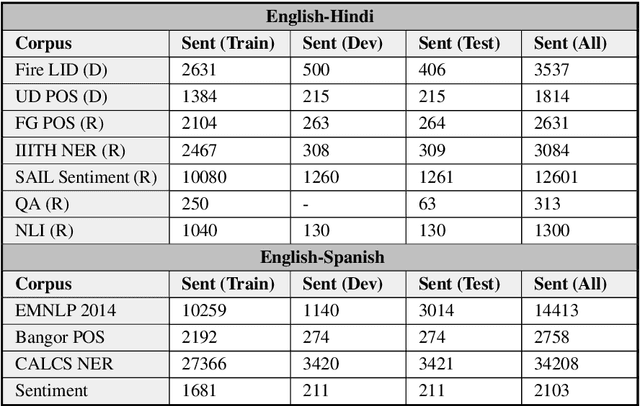
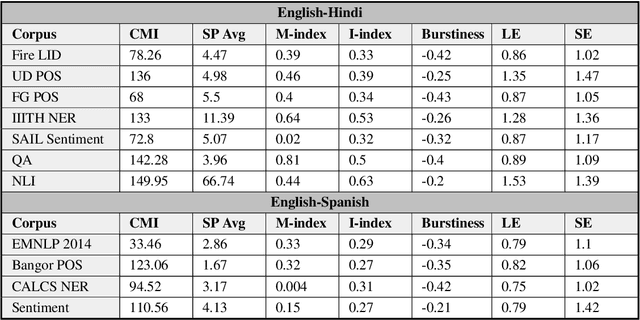
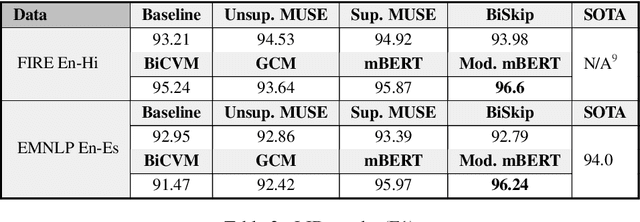
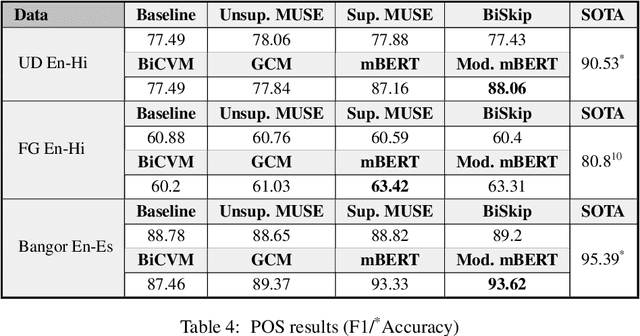
Code-switching is the use of more than one language in the same conversation or utterance. Recently, multilingual contextual embedding models, trained on multiple monolingual corpora, have shown promising results on cross-lingual and multilingual tasks. We present an evaluation benchmark, GLUECoS, for code-switched languages, that spans several NLP tasks in English-Hindi and English-Spanish. Specifically, our evaluation benchmark includes Language Identification from text, POS tagging, Named Entity Recognition, Sentiment Analysis, Question Answering and a new task for code-switching, Natural Language Inference. We present results on all these tasks using cross-lingual word embedding models and multilingual models. In addition, we fine-tune multilingual models on artificially generated code-switched data. Although multilingual models perform significantly better than cross-lingual models, our results show that in most tasks, across both language pairs, multilingual models fine-tuned on code-switched data perform best, showing that multilingual models can be further optimized for code-switching tasks.
Unsung Challenges of Building and Deploying Language Technologies for Low Resource Language Communities
Dec 07, 2019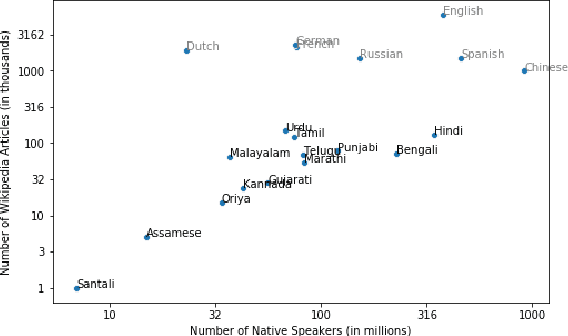
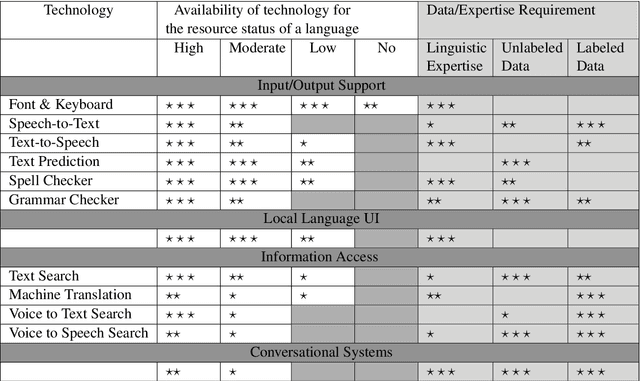
In this paper, we examine and analyze the challenges associated with developing and introducing language technologies to low-resource language communities. While doing so, we bring to light the successes and failures of past work in this area, challenges being faced in doing so, and what they have achieved. Throughout this paper, we take a problem-facing approach and describe essential factors which the success of such technologies hinges upon. We present the various aspects in a manner which clarify and lay out the different tasks involved, which can aid organizations looking to make an impact in this area. We take the example of Gondi, an extremely-low resource Indian language, to reinforce and complement our discussion.
Automated curriculum generation for Policy Gradients from Demonstrations
Dec 01, 2019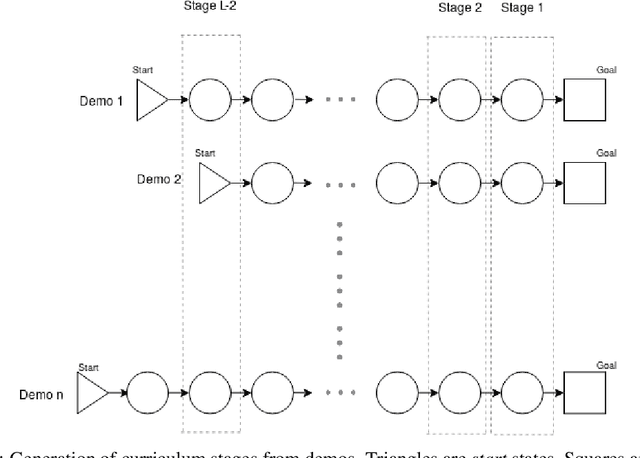

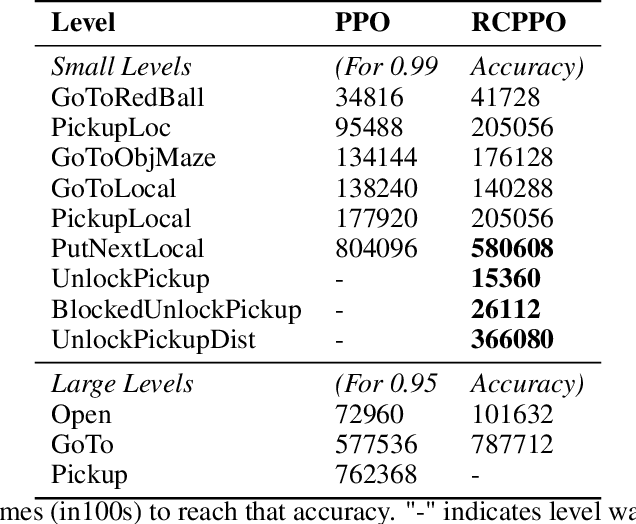
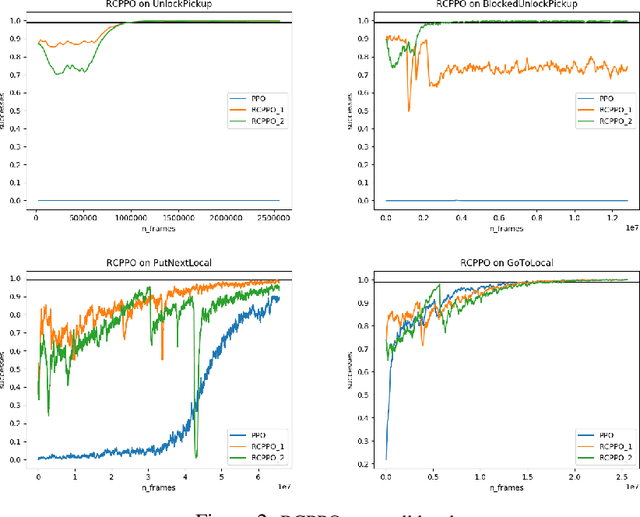
In this paper, we present a technique that improves the process of training an agent (using RL) for instruction following. We develop a training curriculum that uses a nominal number of expert demonstrations and trains the agent in a manner that draws parallels from one of the ways in which humans learn to perform complex tasks, i.e by starting from the goal and working backwards. We test our method on the BabyAI platform and show an improvement in sample efficiency for some of its tasks compared to a PPO (proximal policy optimization) baseline.