 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinigrid & Miniworld: Modular & Customizable Reinforcement Learning Environments for Goal-Oriented Tasks
Jun 24, 2023
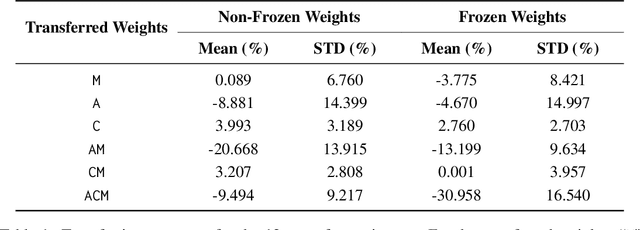


We present the Minigrid and Miniworld libraries which provide a suite of goal-oriented 2D and 3D environments. The libraries were explicitly created with a minimalistic design paradigm to allow users to rapidly develop new environments for a wide range of research-specific needs. As a result, both have received widescale adoption by the RL community, facilitating research in a wide range of areas. In this paper, we outline the design philosophy, environment details, and their world generation API. We also showcase the additional capabilities brought by the unified API between Minigrid and Miniworld through case studies on transfer learning (for both RL agents and humans) between the different observation spaces. The source code of Minigrid and Miniworld can be found at https://github.com/Farama-Foundation/{Minigrid, Miniworld} along with their documentation at https://{minigrid, miniworld}.farama.org/.
DeepDrummer : Generating Drum Loops using Deep Learning and a Human in the Loop
Aug 26, 2020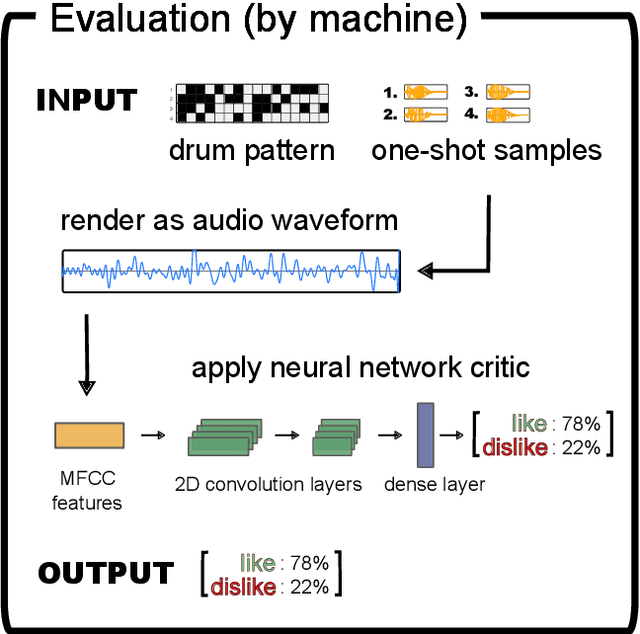
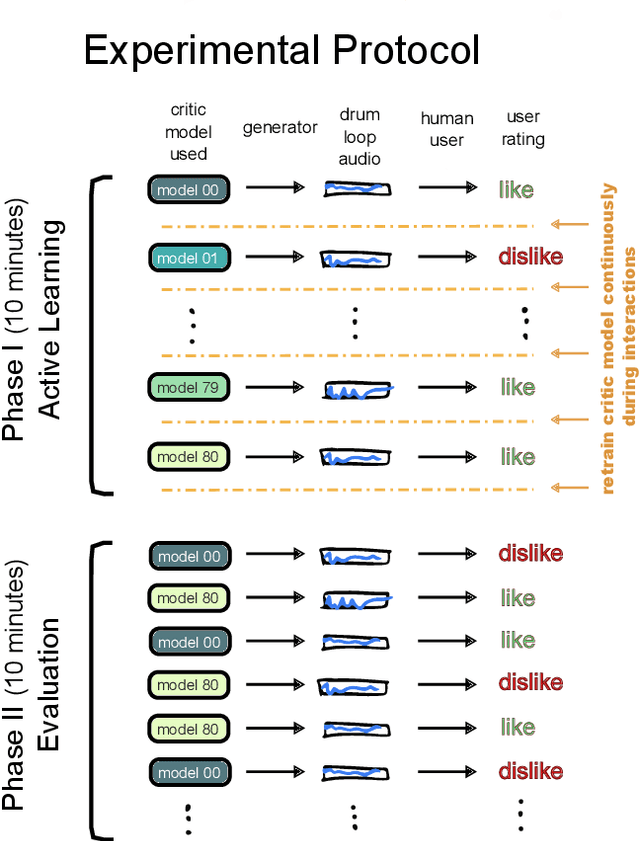

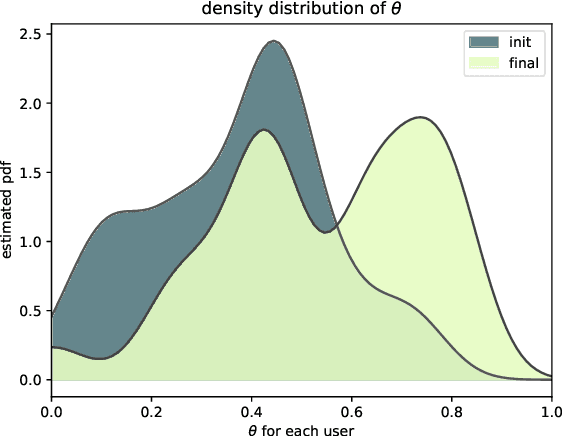
DeepDrummer is a drum loop generation tool that uses active learning to learn the preferences (or current artistic intentions) of a human user from a small number of interactions. The principal goal of this tool is to enable an efficient exploration of new musical ideas. We train a deep neural network classifier on audio data and show how it can be used as the core component of a system that generates drum loops based on few prior beliefs as to how these loops should be structured. We aim to build a system that can converge to meaningful results even with a limited number of interactions with the user. This property enables our method to be used from a cold start situation (no pre-existing dataset), or starting from a collection of audio samples provided by the user. In a proof of concept study with 25 participants, we empirically demonstrate that DeepDrummer is able to converge towards the preference of our subjects after a small number of interactions.
BabyAI 1.1
Jul 24, 2020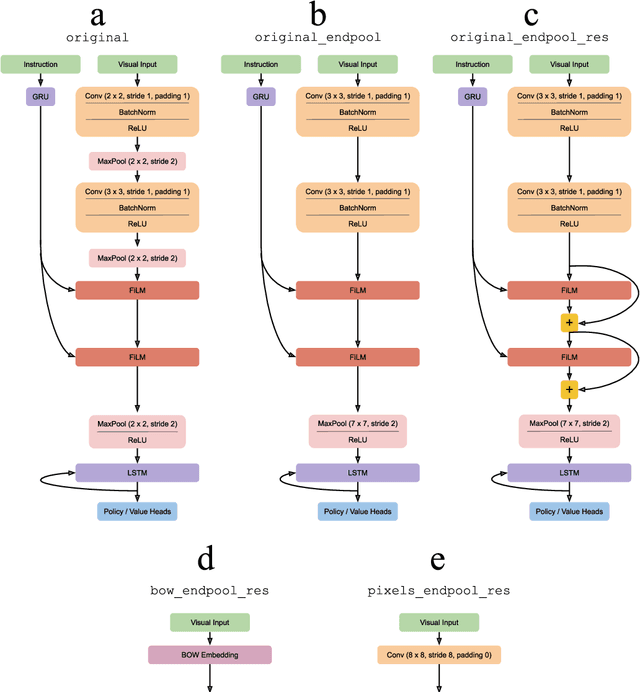
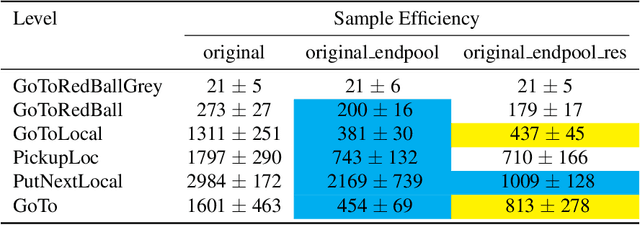

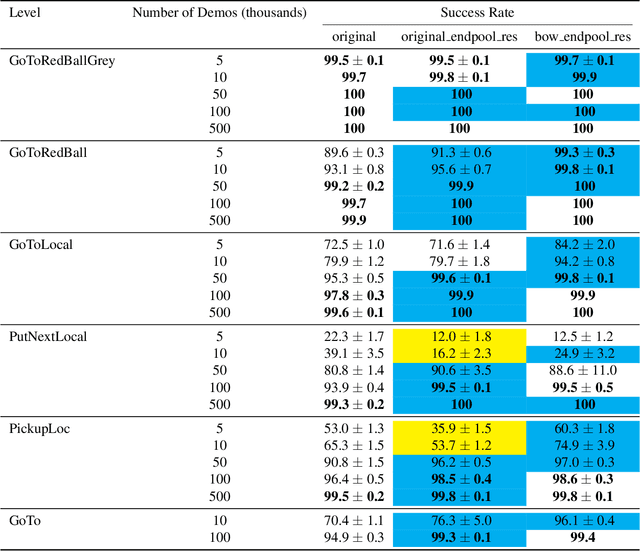
The BabyAI platform is designed to measure the sample efficiency of training an agent to follow grounded-language instructions. BabyAI 1.0 presents baseline results of an agent trained by deep imitation or reinforcement learning. BabyAI 1.1 improves the agent's architecture in three minor ways. This increases reinforcement learning sample efficiency by up to 3 times and improves imitation learning performance on the hardest level from 77 % to 90.4 %. We hope that these improvements increase the computational efficiency of BabyAI experiments and help users design better agents.
Combating False Negatives in Adversarial Imitation Learning
Feb 02, 2020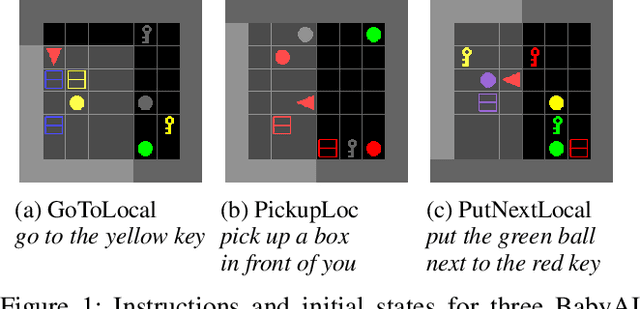

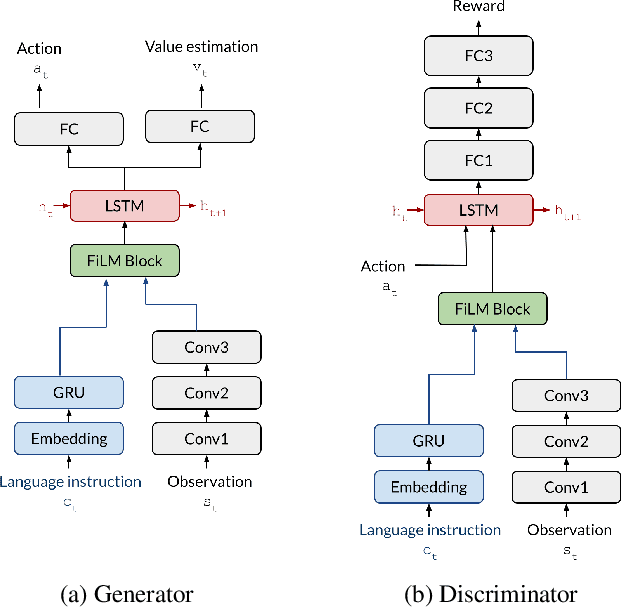
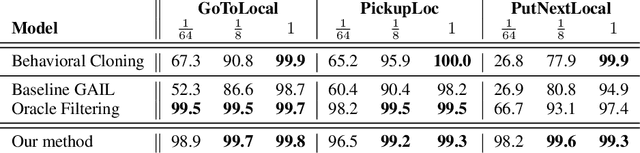
In adversarial imitation learning, a discriminator is trained to differentiate agent episodes from expert demonstrations representing the desired behavior. However, as the trained policy learns to be more successful, the negative examples (the ones produced by the agent) become increasingly similar to expert ones. Despite the fact that the task is successfully accomplished in some of the agent's trajectories, the discriminator is trained to output low values for them. We hypothesize that this inconsistent training signal for the discriminator can impede its learning, and consequently leads to worse overall performance of the agent. We show experimental evidence for this hypothesis and that the 'False Negatives' (i.e. successful agent episodes) significantly hinder adversarial imitation learning, which is the first contribution of this paper. Then, we propose a method to alleviate the impact of false negatives and test it on the BabyAI environment. This method consistently improves sample efficiency over the baselines by at least an order of magnitude.
Option-critic in cooperative multi-agent systems
Jan 06, 2020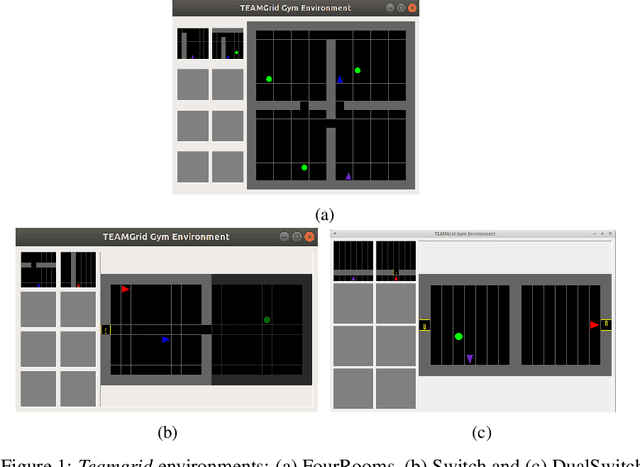
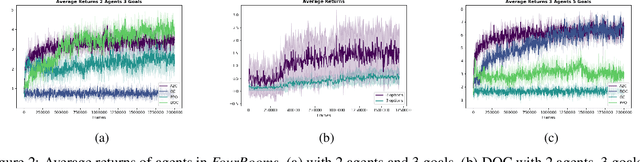
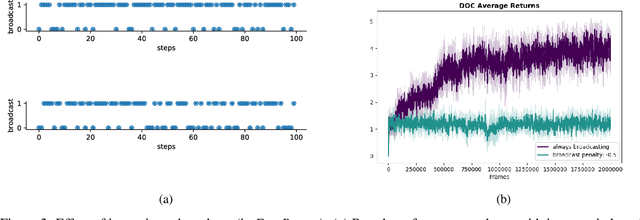
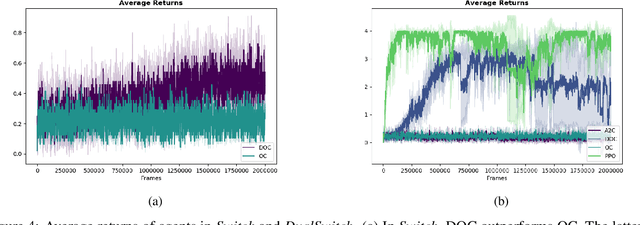
In this paper, we investigate learning temporal abstractions in cooperative multi-agent systems using the options framework (Sutton et al, 1999) and provide a model-free algorithm for this problem. First, we address the planning problem for the decentralized POMDP represented by the multi-agent system, by introducing a common information approach. We use common beliefs and broadcasting to solve an equivalent centralized POMDP problem. Then, we propose the Distributed Option Critic (DOC) algorithm, motivated by the work of Bacon et al (2017) in the single-agent setting. Our approach uses centralized option evaluation and decentralized intra-option improvement. We analyze theoretically the asymptotic convergence of DOC and validate its performance in grid-world environments, where we implement DOC using a deep neural network. Our experiments show that DOC performs competitively with state-of-the-art algorithms and that it is scalable when the number of agents increases.
Options of Interest: Temporal Abstraction with Interest Functions
Jan 01, 2020



Temporal abstraction refers to the ability of an agent to use behaviours of controllers which act for a limited, variable amount of time. The options framework describes such behaviours as consisting of a subset of states in which they can initiate, an internal policy and a stochastic termination condition. However, much of the subsequent work on option discovery has ignored the initiation set, because of difficulty in learning it from data. We provide a generalization of initiation sets suitable for general function approximation, by defining an interest function associated with an option. We derive a gradient-based learning algorithm for interest functions, leading to a new interest-option-critic architecture. We investigate how interest functions can be leveraged to learn interpretable and reusable temporal abstractions. We demonstrate the efficacy of the proposed approach through quantitative and qualitative results, in both discrete and continuous environments.
Automated curriculum generation for Policy Gradients from Demonstrations
Dec 01, 2019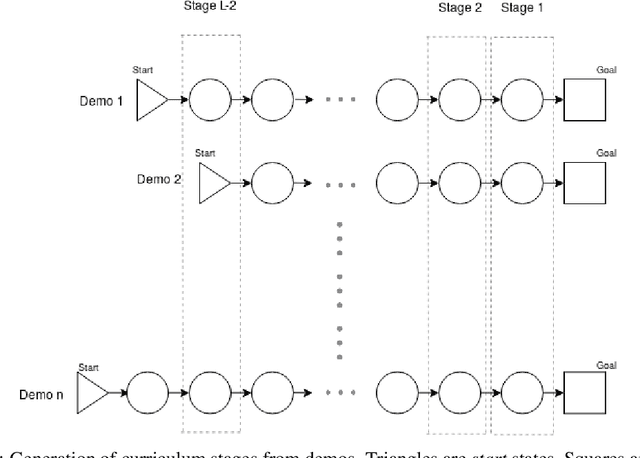

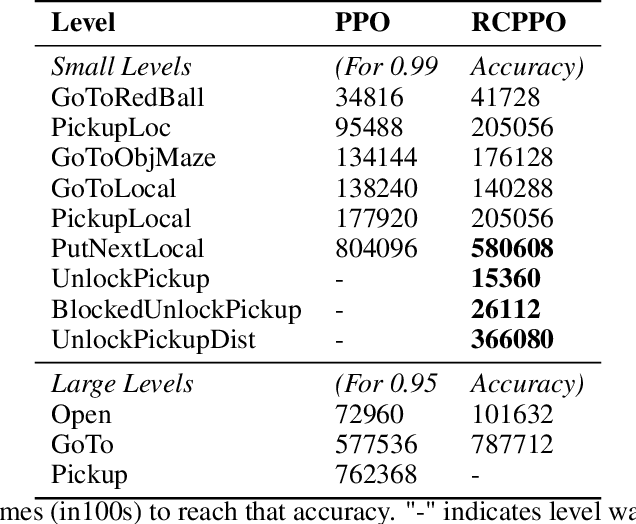
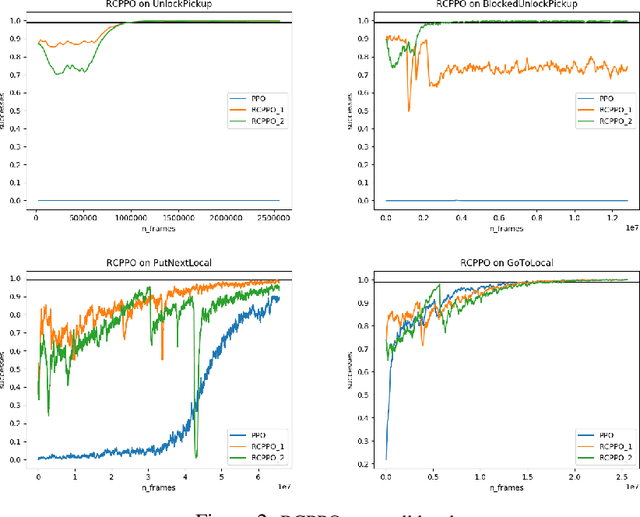
In this paper, we present a technique that improves the process of training an agent (using RL) for instruction following. We develop a training curriculum that uses a nominal number of expert demonstrations and trains the agent in a manner that draws parallels from one of the ways in which humans learn to perform complex tasks, i.e by starting from the goal and working backwards. We test our method on the BabyAI platform and show an improvement in sample efficiency for some of its tasks compared to a PPO (proximal policy optimization) baseline.
Robo-PlaNet: Learning to Poke in a Day
Nov 19, 2019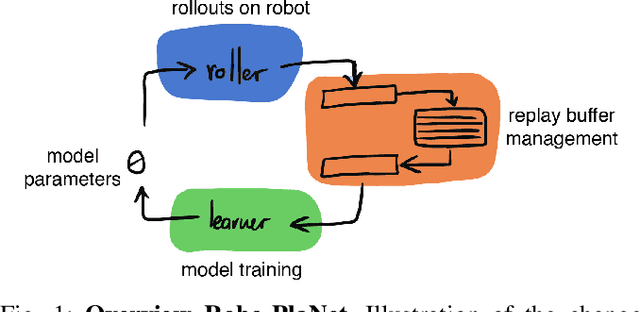

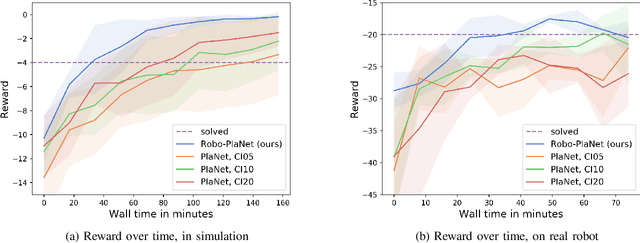
Recently, the Deep Planning Network (PlaNet) approach was introduced as a model-based reinforcement learning method that learns environment dynamics directly from pixel observations. This architecture is useful for learning tasks in which either the agent does not have access to meaningful states (like position/velocity of robotic joints) or where the observed states significantly deviate from the physical state of the agent (which is commonly the case in low-cost robots in the form of backlash or noisy joint readings). PlaNet, by design, interleaves phases of training the dynamics model with phases of collecting more data on the target environment, leading to long training times. In this work, we introduce Robo-PlaNet, an asynchronous version of PlaNet. This algorithm consistently reaches higher performance in the same amount of time, which we demonstrate in both a simulated and a real robotic experiment.
BabyAI: First Steps Towards Grounded Language Learning With a Human In the Loop
Oct 27, 2018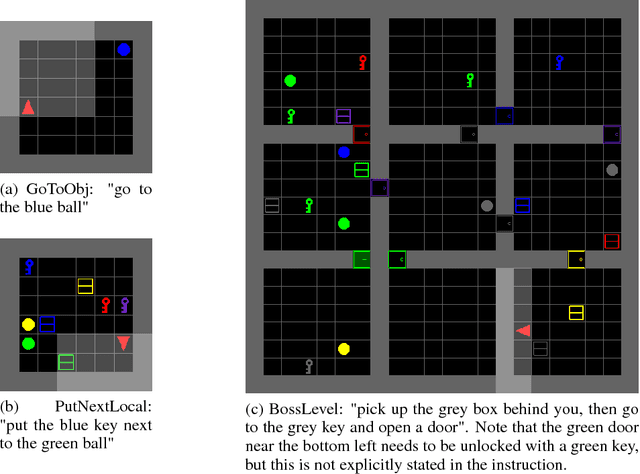
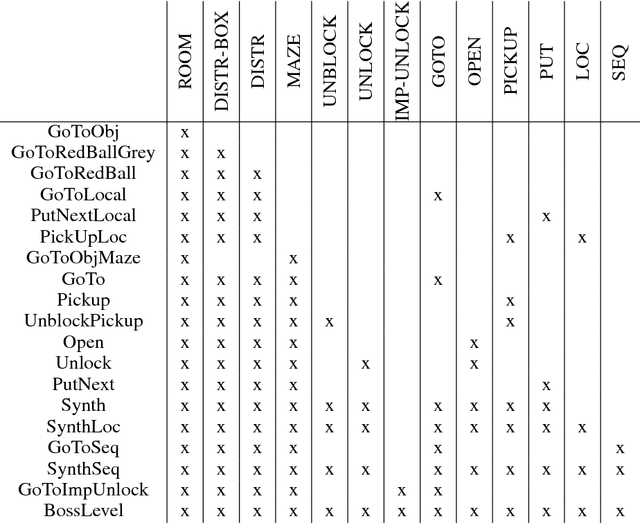
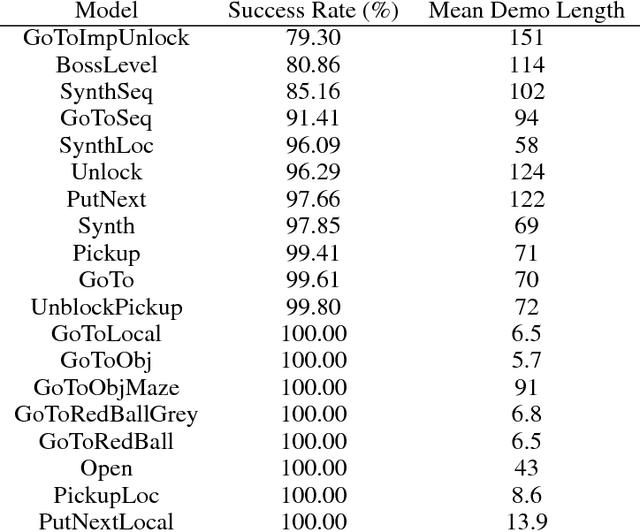

Allowing humans to interactively train artificial agents to understand language instructions is desirable for both practical and scientific reasons, but given the poor data efficiency of the current learning methods, this goal may require substantial research efforts. Here, we introduce the BabyAI research platform to support investigations towards including humans in the loop for grounded language learning. The BabyAI platform comprises an extensible suite of 19 levels of increasing difficulty. The levels gradually lead the agent towards acquiring a combinatorially rich synthetic language which is a proper subset of English. The platform also provides a heuristic expert agent for the purpose of simulating a human teacher. We report baseline results and estimate the amount of human involvement that would be required to train a neural network-based agent on some of the BabyAI levels. We put forward strong evidence that current deep learning methods are not yet sufficiently sample efficient when it comes to learning a language with compositional properties.