 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Floor Plan Design with LLMs via Reinforcement Learning with Verifiable Rewards
May 13, 2026An AI system for professional floor plan design must precisely control room dimensions and areas while respecting the desired connectivity between rooms and maintaining functional and aesthetic quality. Existing generative approaches focus primarily on respecting the requested connectivity between rooms, but do not support generating floor plans that respect numerical constraints. We introduce a text-based floor plan generation approach that fine-tunes a large language model (LLM) on real plans and then applies reinforcement learning with verifiable rewards (RLVR) to improve adherence to topological and numerical constraints while discouraging invalid or overlapping outputs. Furthermore, we design a set of constraint adherence metrics to systematically measure how generated floor plans align with user-defined constraints. Our model generates floor plans that satisfy user-defined connectivity and numerical constraints and outperforms existing methods on Realism, Compatibility, and Diversity metrics. Across all tasks, our approach achieves at least a 94% relative reduction in Compatibility compared with existing methods. Our results demonstrate that LLMs can effectively handle constraints in this setting, suggesting broader applications for text-based generative modeling.
DStruct2Design: Data and Benchmarks for Data Structure Driven Generative Floor Plan Design
Jul 22, 2024



Text conditioned generative models for images have yielded impressive results. Text conditioned floorplan generation as a special type of raster image generation task also received particular attention. However there are many use cases in floorpla generation where numerical properties of the generated result are more important than the aesthetics. For instance, one might want to specify sizes for certain rooms in a floorplan and compare the generated floorplan with given specifications Current approaches, datasets and commonly used evaluations do not support these kinds of constraints. As such, an attractive strategy is to generate an intermediate data structure that contains numerical properties of a floorplan which can be used to generate the final floorplan image. To explore this setting we (1) construct a new dataset for this data-structure to data-structure formulation of floorplan generation using two popular image based floorplan datasets RPLAN and ProcTHOR-10k, and provide the tools to convert further procedurally generated ProcTHOR floorplan data into our format. (2) We explore the task of floorplan generation given a partial or complete set of constraints and we design a series of metrics and benchmarks to enable evaluating how well samples generated from models respect the constraints. (3) We create multiple baselines by finetuning a large language model (LLM), Llama3, and demonstrate the feasibility of using floorplan data structure conditioned LLMs for the problem of floorplan generation respecting numerical constraints. We hope that our new datasets and benchmarks will encourage further research on different ways to improve the performance of LLMs and other generative modelling techniques for generating designs where quantitative constraints are only partially specified, but must be respected.
CtRL-Sim: Reactive and Controllable Driving Agents with Offline Reinforcement Learning
Mar 29, 2024



Evaluating autonomous vehicle stacks (AVs) in simulation typically involves replaying driving logs from real-world recorded traffic. However, agents replayed from offline data do not react to the actions of the AV, and their behaviour cannot be easily controlled to simulate counterfactual scenarios. Existing approaches have attempted to address these shortcomings by proposing methods that rely on heuristics or learned generative models of real-world data but these approaches either lack realism or necessitate costly iterative sampling procedures to control the generated behaviours. In this work, we take an alternative approach and propose CtRL-Sim, a method that leverages return-conditioned offline reinforcement learning within a physics-enhanced Nocturne simulator to efficiently generate reactive and controllable traffic agents. Specifically, we process real-world driving data through the Nocturne simulator to generate a diverse offline reinforcement learning dataset, annotated with various reward terms. With this dataset, we train a return-conditioned multi-agent behaviour model that allows for fine-grained manipulation of agent behaviours by modifying the desired returns for the various reward components. This capability enables the generation of a wide range of driving behaviours beyond the scope of the initial dataset, including those representing adversarial behaviours. We demonstrate that CtRL-Sim can efficiently generate diverse and realistic safety-critical scenarios while providing fine-grained control over agent behaviours. Further, we show that fine-tuning our model on simulated safety-critical scenarios generated by our model enhances this controllability.
Visual Question Answering From Another Perspective: CLEVR Mental Rotation Tests
Dec 03, 2022



Different types of mental rotation tests have been used extensively in psychology to understand human visual reasoning and perception. Understanding what an object or visual scene would look like from another viewpoint is a challenging problem that is made even harder if it must be performed from a single image. We explore a controlled setting whereby questions are posed about the properties of a scene if that scene was observed from another viewpoint. To do this we have created a new version of the CLEVR dataset that we call CLEVR Mental Rotation Tests (CLEVR-MRT). Using CLEVR-MRT we examine standard methods, show how they fall short, then explore novel neural architectures that involve inferring volumetric representations of a scene. These volumes can be manipulated via camera-conditioned transformations to answer the question. We examine the efficacy of different model variants through rigorous ablations and demonstrate the efficacy of volumetric representations.
The Sandbox Environment for Generalizable Agent Research (SEGAR)
Mar 19, 2022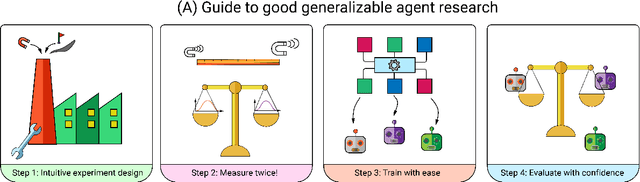
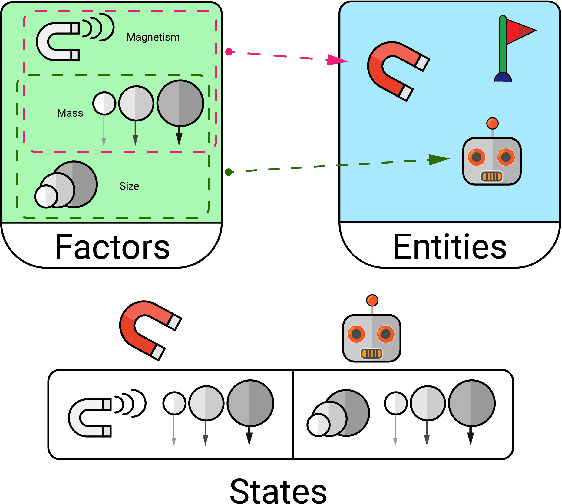
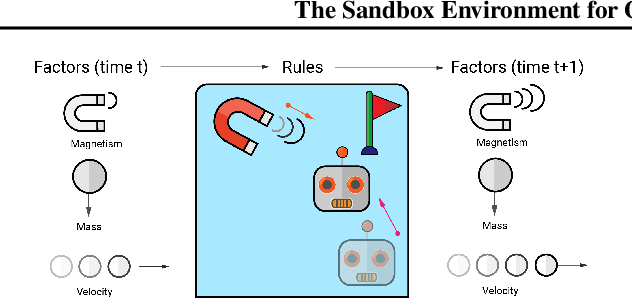
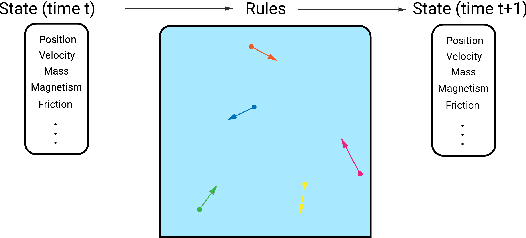
A broad challenge of research on generalization for sequential decision-making tasks in interactive environments is designing benchmarks that clearly landmark progress. While there has been notable headway, current benchmarks either do not provide suitable exposure nor intuitive control of the underlying factors, are not easy-to-implement, customizable, or extensible, or are computationally expensive to run. We built the Sandbox Environment for Generalizable Agent Research (SEGAR) with all of these things in mind. SEGAR improves the ease and accountability of generalization research in RL, as generalization objectives can be easy designed by specifying task distributions, which in turns allows the researcher to measure the nature of the generalization objective. We present an overview of SEGAR and how it contributes to these goals, as well as experiments that demonstrate a few types of research questions SEGAR can help answer.
Kubric: A scalable dataset generator
Mar 07, 2022

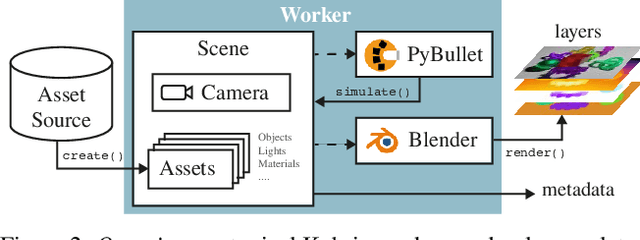
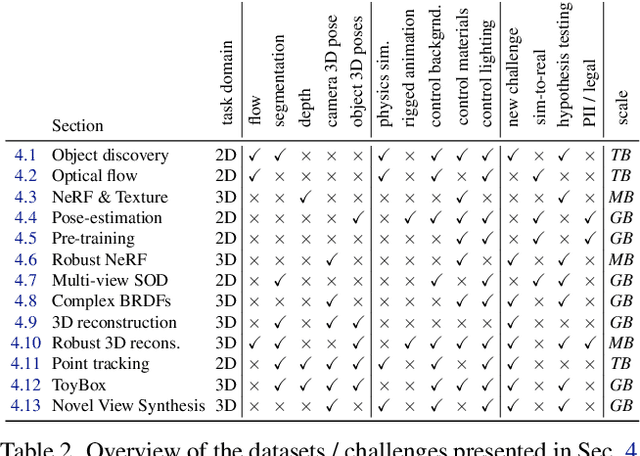
Data is the driving force of machine learning, with the amount and quality of training data often being more important for the performance of a system than architecture and training details. But collecting, processing and annotating real data at scale is difficult, expensive, and frequently raises additional privacy, fairness and legal concerns. Synthetic data is a powerful tool with the potential to address these shortcomings: 1) it is cheap 2) supports rich ground-truth annotations 3) offers full control over data and 4) can circumvent or mitigate problems regarding bias, privacy and licensing. Unfortunately, software tools for effective data generation are less mature than those for architecture design and training, which leads to fragmented generation efforts. To address these problems we introduce Kubric, an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes, with rich annotations, and seamlessly scales to large jobs distributed over thousands of machines, and generating TBs of data. We demonstrate the effectiveness of Kubric by presenting a series of 13 different generated datasets for tasks ranging from studying 3D NeRF models to optical flow estimation. We release Kubric, the used assets, all of the generation code, as well as the rendered datasets for reuse and modification.
GrowSpace: Learning How to Shape Plants
Oct 15, 2021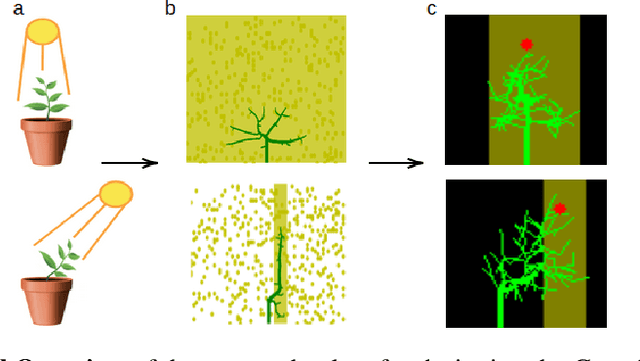
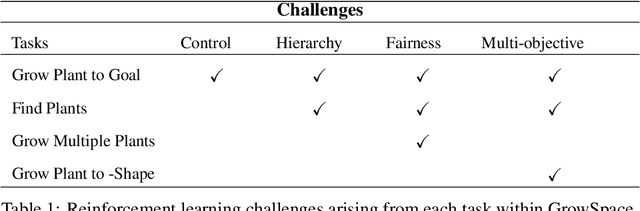
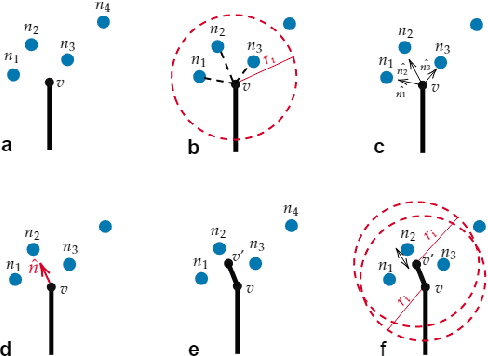
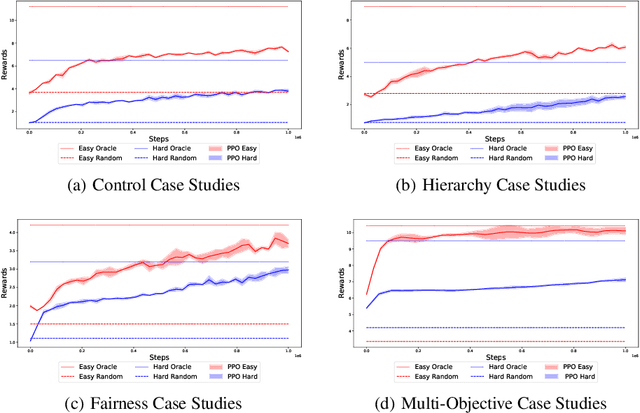
Plants are dynamic systems that are integral to our existence and survival. Plants face environment changes and adapt over time to their surrounding conditions. We argue that plant responses to an environmental stimulus are a good example of a real-world problem that can be approached within a reinforcement learning (RL)framework. With the objective of controlling a plant by moving the light source, we propose GrowSpace, as a new RL benchmark. The back-end of the simulator is implemented using the Space Colonisation Algorithm, a plant growing model based on competition for space. Compared to video game RL environments, this simulator addresses a real-world problem and serves as a test bed to visualize plant growth and movement in a faster way than physical experiments. GrowSpace is composed of a suite of challenges that tackle several problems such as control, multi-stage learning,fairness and multi-objective learning. We provide agent baselines alongside case studies to demonstrate the difficulty of the proposed benchmark.
Sequoia: A Software Framework to Unify Continual Learning Research
Aug 03, 2021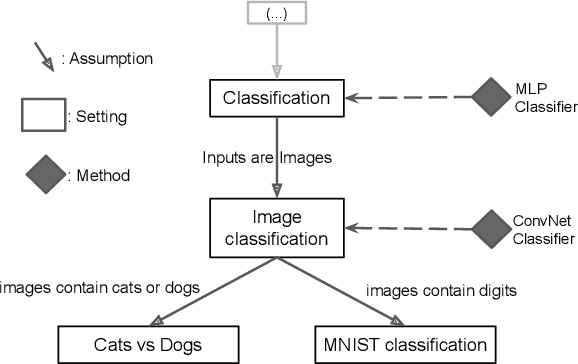
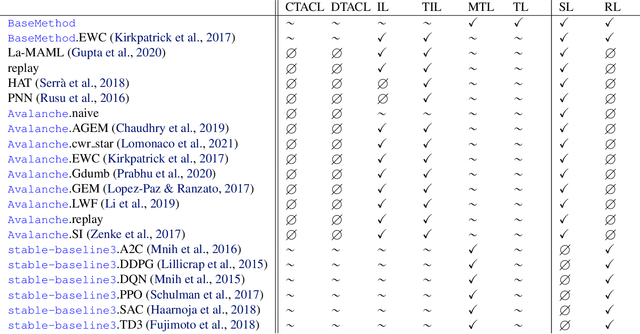
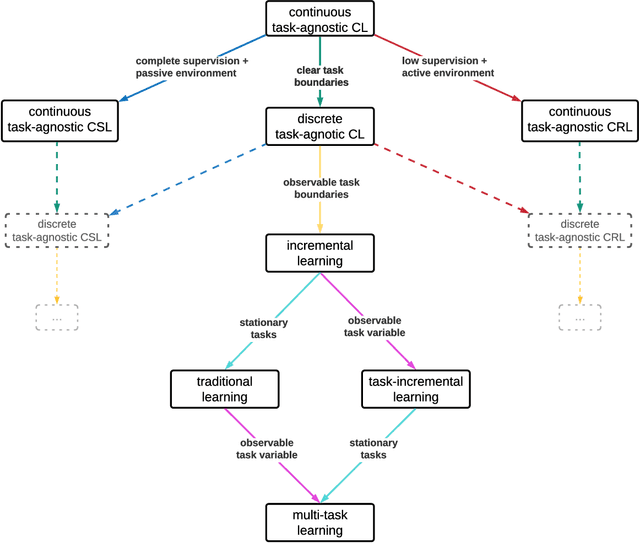
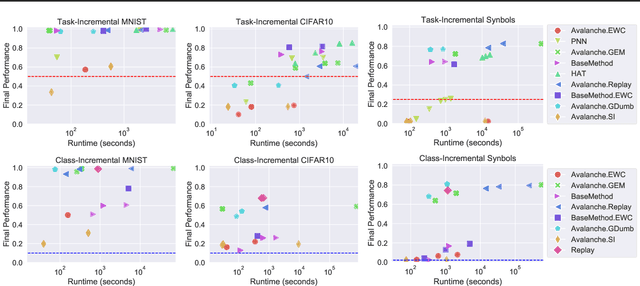
The field of Continual Learning (CL) seeks to develop algorithms that accumulate knowledge and skills over time through interaction with non-stationary environments and data distributions. Measuring progress in CL can be difficult because a plethora of evaluation procedures (ettings) and algorithmic solutions (methods) have emerged, each with their own potentially disjoint set of assumptions about the CL problem. In this work, we view each setting as a set of assumptions. We then create a tree-shaped hierarchy of the research settings in CL, in which more general settings become the parents of those with more restrictive assumptions. This makes it possible to use inheritance to share and reuse research, as developing a method for a given setting also makes it directly applicable onto any of its children. We instantiate this idea as a publicly available software framework called Sequoia, which features a variety of settings from both the Continual Supervised Learning (CSL) and Continual Reinforcement Learning (CRL) domains. Sequoia also includes a growing suite of methods which are easy to extend and customize, in addition to more specialized methods from third-party libraries. We hope that this new paradigm and its first implementation can serve as a foundation for the unification and acceleration of research in CL. You can help us grow the tree by visiting www.github.com/lebrice/Sequoia.
gradSim: Differentiable simulation for system identification and visuomotor control
Apr 06, 2021
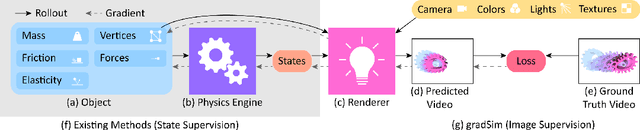
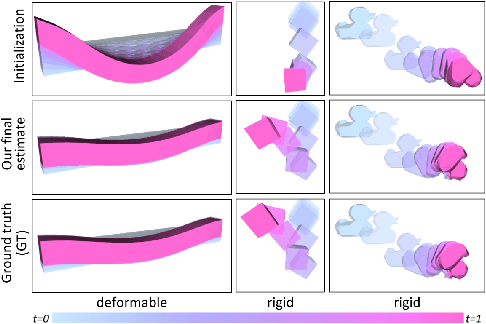

We consider the problem of estimating an object's physical properties such as mass, friction, and elasticity directly from video sequences. Such a system identification problem is fundamentally ill-posed due to the loss of information during image formation. Current solutions require precise 3D labels which are labor-intensive to gather, and infeasible to create for many systems such as deformable solids or cloth. We present gradSim, a framework that overcomes the dependence on 3D supervision by leveraging differentiable multiphysics simulation and differentiable rendering to jointly model the evolution of scene dynamics and image formation. This novel combination enables backpropagation from pixels in a video sequence through to the underlying physical attributes that generated them. Moreover, our unified computation graph -- spanning from the dynamics and through the rendering process -- enables learning in challenging visuomotor control tasks, without relying on state-based (3D) supervision, while obtaining performance competitive to or better than techniques that rely on precise 3D labels.
Touch-based Curiosity for Sparse-Reward Tasks
Apr 01, 2021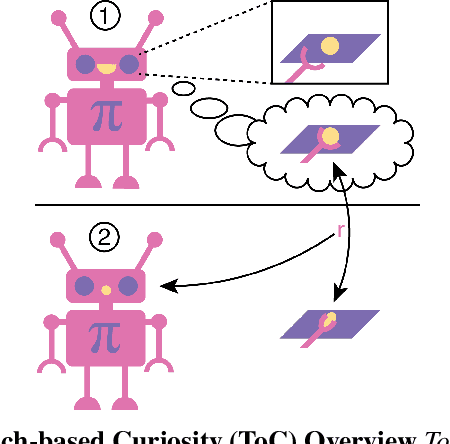
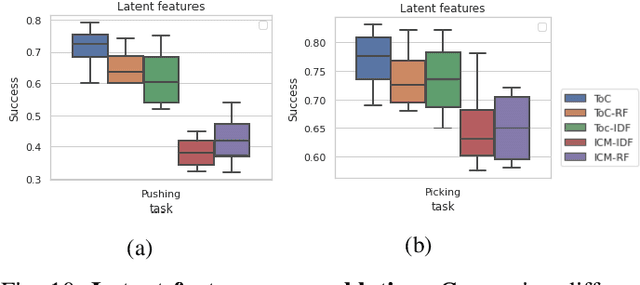
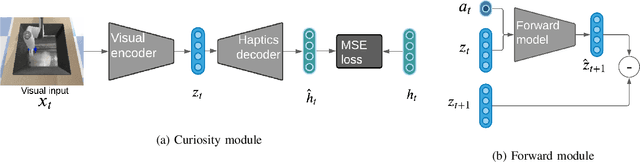
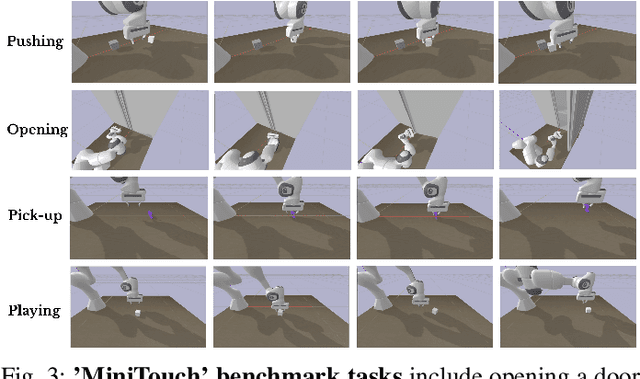
Robots in many real-world settings have access to force/torque sensors in their gripper and tactile sensing is often necessary in tasks that involve contact-rich motion. In this work, we leverage surprise from mismatches in touch feedback to guide exploration in hard sparse-reward reinforcement learning tasks. Our approach, Touch-based Curiosity (ToC), learns what visible objects interactions are supposed to "feel" like. We encourage exploration by rewarding interactions where the expectation and the experience don't match. In our proposed method, an initial task-independent exploration phase is followed by an on-task learning phase, in which the original interactions are relabeled with on-task rewards. We test our approach on a range of touch-intensive robot arm tasks (e.g. pushing objects, opening doors), which we also release as part of this work. Across multiple experiments in a simulated setting, we demonstrate that our method is able to learn these difficult tasks through sparse reward and curiosity alone. We compare our cross-modal approach to single-modality (touch- or vision-only) approaches as well as other curiosity-based methods and find that our method performs better and is more sample-efficient.