 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHAPO: Sharpness-Aware Policy Optimization for Safe Exploration
Jun 08, 2026Safe exploration is a prerequisite for deploying reinforcement learning (RL) agents in safety-critical domains. In this paper, we approach safe exploration through the lens of epistemic uncertainty, where the actor's sensitivity to parameter perturbations serves as a practical proxy for regions of high uncertainty. We propose Sharpness-Aware Policy Optimization (SHAPO), a sharpness-aware policy update rule that evaluates gradients at perturbed parameters, making policy updates pessimistic with respect to the actor's epistemic uncertainty. Analytically we show that this adjustment implicitly reweighs policy gradients, amplifying the influence of rare unsafe actions while tempering contributions from already safe ones, thereby biasing learning toward conservative behavior in under-explored regions. Across several continuous-control tasks, our method consistently improves both safety and task performance over existing baselines, significantly expanding their Pareto frontiers.
PerceptTwin: Semantic Scene Reconstruction for Iterative LLM Planning and Verification
Jun 02, 2026Simulation environments are useful for both robot policy learning and planning verification and validation. Traditionally, the process of creating a simulation was onerous. Creating a bespoke simulation environment for each individual environment that a robot would operate in was simply infeasible. In this work, we introduce PerceptTwin, a fully automatic pipeline that constructs interactive simulations directly from semantic scene representations produced by a robot's perception stack. PerceptTwin combines open-vocabulary object maps with 3D asset generation, affordance prediction, and commonsense condition checking. These interactive simulations can be used to validate and refine plans before they are executed on the robot hardware. Borrowing from the AI alignment literature, we also introduce an LLM judge that verifies plan correctness and alignment with human preferences. Experiments show that PerceptTwin feedback allows LLM planners to refine plans, enhance safety, and resist harmful black-box prompting attacks. In our suite of tasks, PerceptTwin improves plan success by an average of approximately 39% for GPT5, GPT5Mini, and GPT5Nano planners. Additionally, PerceptTwin also improves human plan verification by up to 18% on average for plans that fail due to unfilled skill preconditions. Our results demonstrate the potential of open-vocabulary scene simulation from robot perception as a foundation for safer, more reliable robot planning.
Constrained Group Relative Policy Optimization
Feb 05, 2026While Group Relative Policy Optimization (GRPO) has emerged as a scalable framework for critic-free policy learning, extending it to settings with explicit behavioral constraints remains underexplored. We introduce Constrained GRPO, a Lagrangian-based extension of GRPO for constrained policy optimization. Constraints are specified via indicator cost functions, enabling direct optimization of violation rates through a Lagrangian relaxation. We show that a naive multi-component treatment in advantage estimation can break constrained learning: mismatched component-wise standard deviations distort the relative importance of the different objective terms, which in turn corrupts the Lagrangian signal and prevents meaningful constraint enforcement. We formally derive this effect to motivate our scalarized advantage construction that preserves the intended trade-off between reward and constraint terms. Experiments in a toy gridworld confirm the predicted optimization pathology and demonstrate that scalarizing advantages restores stable constraint control. In addition, we evaluate Constrained GRPO on robotics tasks, where it improves constraint satisfaction while increasing task success, establishing a simple and effective recipe for constrained policy optimization in embodied AI domains that increasingly rely on large multimodal foundation models.
Poutine: Vision-Language-Trajectory Pre-Training and Reinforcement Learning Post-Training Enable Robust End-to-End Autonomous Driving
Jun 12, 2025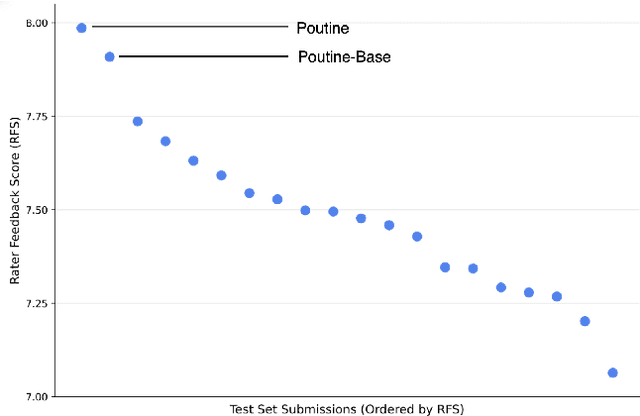



We present Poutine, a 3B-parameter vision-language model (VLM) tailored for end-to-end autonomous driving in long-tail driving scenarios. Poutine is trained in two stages. To obtain strong base driving capabilities, we train Poutine-Base in a self-supervised vision-language-trajectory (VLT) next-token prediction fashion on 83 hours of CoVLA nominal driving and 11 hours of Waymo long-tail driving. Accompanying language annotations are auto-generated with a 72B-parameter VLM. Poutine is obtained by fine-tuning Poutine-Base with Group Relative Policy Optimization (GRPO) using less than 500 preference-labeled frames from the Waymo validation set. We show that both VLT pretraining and RL fine-tuning are critical to attain strong driving performance in the long-tail. Poutine-Base achieves a rater-feedback score (RFS) of 8.12 on the validation set, nearly matching Waymo's expert ground-truth RFS. The final Poutine model achieves an RFS of 7.99 on the official Waymo test set, placing 1st in the 2025 Waymo Vision-Based End-to-End Driving Challenge by a significant margin. These results highlight the promise of scalable VLT pre-training and lightweight RL fine-tuning to enable robust and generalizable autonomy.
Scenario Dreamer: Vectorized Latent Diffusion for Generating Driving Simulation Environments
Mar 28, 2025



We introduce Scenario Dreamer, a fully data-driven generative simulator for autonomous vehicle planning that generates both the initial traffic scene - comprising a lane graph and agent bounding boxes - and closed-loop agent behaviours. Existing methods for generating driving simulation environments encode the initial traffic scene as a rasterized image and, as such, require parameter-heavy networks that perform unnecessary computation due to many empty pixels in the rasterized scene. Moreover, we find that existing methods that employ rule-based agent behaviours lack diversity and realism. Scenario Dreamer instead employs a novel vectorized latent diffusion model for initial scene generation that directly operates on the vectorized scene elements and an autoregressive Transformer for data-driven agent behaviour simulation. Scenario Dreamer additionally supports scene extrapolation via diffusion inpainting, enabling the generation of unbounded simulation environments. Extensive experiments show that Scenario Dreamer outperforms existing generative simulators in realism and efficiency: the vectorized scene-generation base model achieves superior generation quality with around 2x fewer parameters, 6x lower generation latency, and 10x fewer GPU training hours compared to the strongest baseline. We confirm its practical utility by showing that reinforcement learning planning agents are more challenged in Scenario Dreamer environments than traditional non-generative simulation environments, especially on long and adversarial driving environments.
OpenLex3D: A New Evaluation Benchmark for Open-Vocabulary 3D Scene Representations
Mar 25, 2025



3D scene understanding has been transformed by open-vocabulary language models that enable interaction via natural language. However, the evaluation of these representations is limited to closed-set semantics that do not capture the richness of language. This work presents OpenLex3D, a dedicated benchmark to evaluate 3D open-vocabulary scene representations. OpenLex3D provides entirely new label annotations for 23 scenes from Replica, ScanNet++, and HM3D, which capture real-world linguistic variability by introducing synonymical object categories and additional nuanced descriptions. By introducing an open-set 3D semantic segmentation task and an object retrieval task, we provide insights on feature precision, segmentation, and downstream capabilities. We evaluate various existing 3D open-vocabulary methods on OpenLex3D, showcasing failure cases, and avenues for improvement. The benchmark is publicly available at: https://openlex3d.github.io/.
Safety Representations for Safer Policy Learning
Feb 27, 2025



Reinforcement learning algorithms typically necessitate extensive exploration of the state space to find optimal policies. However, in safety-critical applications, the risks associated with such exploration can lead to catastrophic consequences. Existing safe exploration methods attempt to mitigate this by imposing constraints, which often result in overly conservative behaviours and inefficient learning. Heavy penalties for early constraint violations can trap agents in local optima, deterring exploration of risky yet high-reward regions of the state space. To address this, we introduce a method that explicitly learns state-conditioned safety representations. By augmenting the state features with these safety representations, our approach naturally encourages safer exploration without being excessively cautious, resulting in more efficient and safer policy learning in safety-critical scenarios. Empirical evaluations across diverse environments show that our method significantly improves task performance while reducing constraint violations during training, underscoring its effectiveness in balancing exploration with safety.
The Bare Necessities: Designing Simple, Effective Open-Vocabulary Scene Graphs
Dec 02, 20243D open-vocabulary scene graph methods are a promising map representation for embodied agents, however many current approaches are computationally expensive. In this paper, we reexamine the critical design choices established in previous works to optimize both efficiency and performance. We propose a general scene graph framework and conduct three studies that focus on image pre-processing, feature fusion, and feature selection. Our findings reveal that commonly used image pre-processing techniques provide minimal performance improvement while tripling computation (on a per object view basis). We also show that averaging feature labels across different views significantly degrades performance. We study alternative feature selection strategies that enhance performance without adding unnecessary computational costs. Based on our findings, we introduce a computationally balanced approach for 3D point cloud segmentation with per-object features. The approach matches state-of-the-art classification accuracy while achieving a threefold reduction in computation.
A Survey on Small-Scale Testbeds for Connected and Automated Vehicles and Robot Swarms
Aug 26, 2024



Connected and automated vehicles and robot swarms hold transformative potential for enhancing safety, efficiency, and sustainability in the transportation and manufacturing sectors. Extensive testing and validation of these technologies is crucial for their deployment in the real world. While simulations are essential for initial testing, they often have limitations in capturing the complex dynamics of real-world interactions. This limitation underscores the importance of small-scale testbeds. These testbeds provide a realistic, cost-effective, and controlled environment for testing and validating algorithms, acting as an essential intermediary between simulation and full-scale experiments. This work serves to facilitate researchers' efforts in identifying existing small-scale testbeds suitable for their experiments and provide insights for those who want to build their own. In addition, it delivers a comprehensive survey of the current landscape of these testbeds. We derive 62 characteristics of testbeds based on the well-known sense-plan-act paradigm and offer an online table comparing 22 small-scale testbeds based on these characteristics. The online table is hosted on our designated public webpage www.cpm-remote.de/testbeds, and we invite testbed creators and developers to contribute to it. We closely examine nine testbeds in this paper, demonstrating how the derived characteristics can be used to present testbeds. Furthermore, we discuss three ongoing challenges concerning small-scale testbeds that we identified, i.e., small-scale to full-scale transition, sustainability, and power and resource management.
The Harmonic Exponential Filter for Nonparametric Estimation on Motion Groups
Aug 01, 2024



Bayesian estimation is a vital tool in robotics as it allows systems to update the belief of the robot state using incomplete information from noisy sensors. To render the state estimation problem tractable, many systems assume that the motion and measurement noise, as well as the state distribution, are all unimodal and Gaussian. However, there are numerous scenarios and systems that do not comply with these assumptions. Existing non-parametric filters that are used to model multimodal distributions have drawbacks that limit their ability to represent a diverse set of distributions. In this paper, we introduce a novel approach to nonparametric Bayesian filtering to cope with multimodal distributions using harmonic exponential distributions. This approach leverages two key insights of harmonic exponential distributions: a) the product of two distributions can be expressed as the element-wise addition of their log-likelihood Fourier coefficients, and b) the convolution of two distributions can be efficiently computed as the tensor product of their Fourier coefficients. These observations enable the development of an efficient and exact solution to the Bayes filter up to the band limit of a Fourier transform. We demonstrate our filter's superior performance compared with established nonparametric filtering methods across a range of simulated and real-world localization tasks.