 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Agents as Digital Representatives in Collective Decision-Making
Feb 13, 2025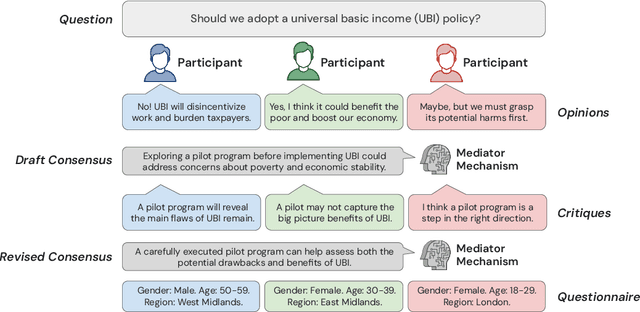

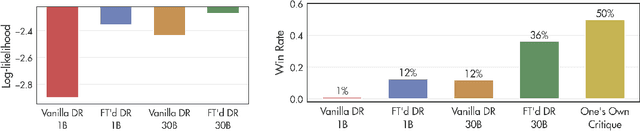
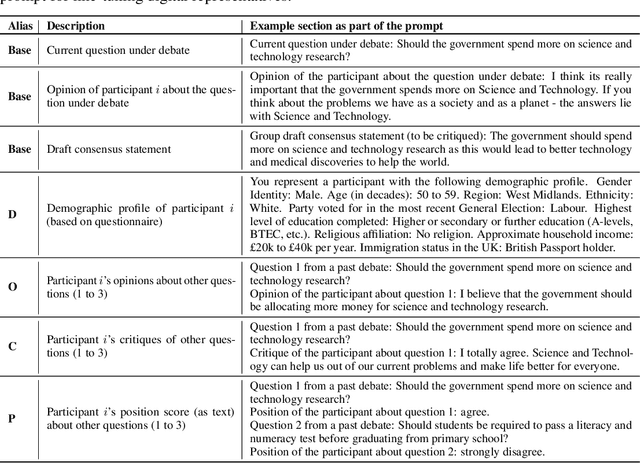
Consider the process of collective decision-making, in which a group of individuals interactively select a preferred outcome from among a universe of alternatives. In this context, "representation" is the activity of making an individual's preferences present in the process via participation by a proxy agent -- i.e. their "representative". To this end, learned models of human behavior have the potential to fill this role, with practical implications for multi-agent scenario studies and mechanism design. In this work, we investigate the possibility of training \textit{language agents} to behave in the capacity of representatives of human agents, appropriately expressing the preferences of those individuals whom they stand for. First, we formalize the setting of \textit{collective decision-making} -- as the episodic process of interaction between a group of agents and a decision mechanism. On this basis, we then formalize the problem of \textit{digital representation} -- as the simulation of an agent's behavior to yield equivalent outcomes from the mechanism. Finally, we conduct an empirical case study in the setting of \textit{consensus-finding} among diverse humans, and demonstrate the feasibility of fine-tuning large language models to act as digital representatives.
Using deep reinforcement learning to promote sustainable human behaviour on a common pool resource problem
Apr 23, 2024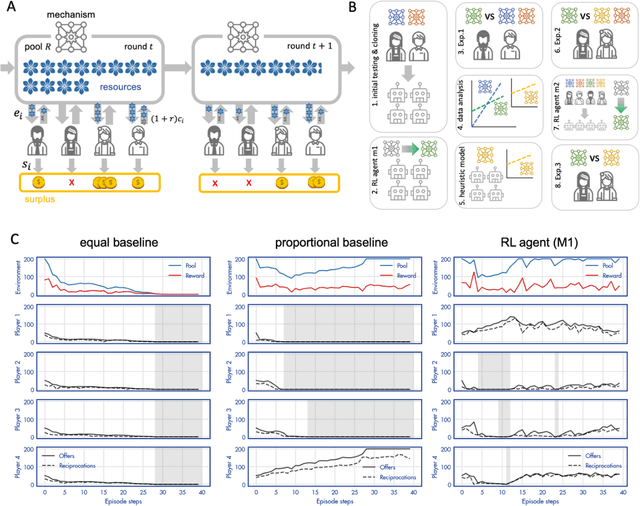
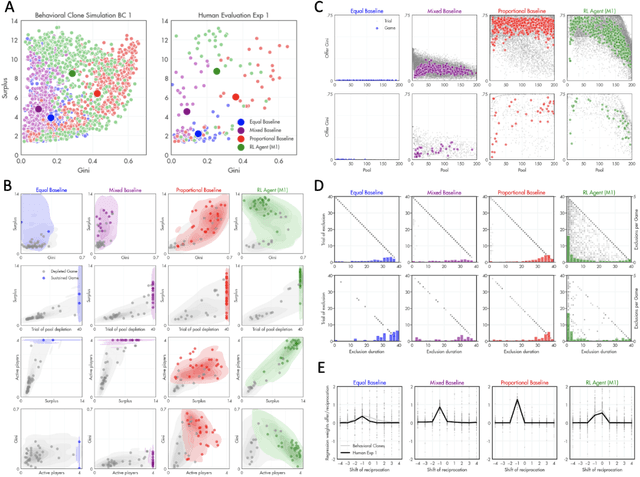
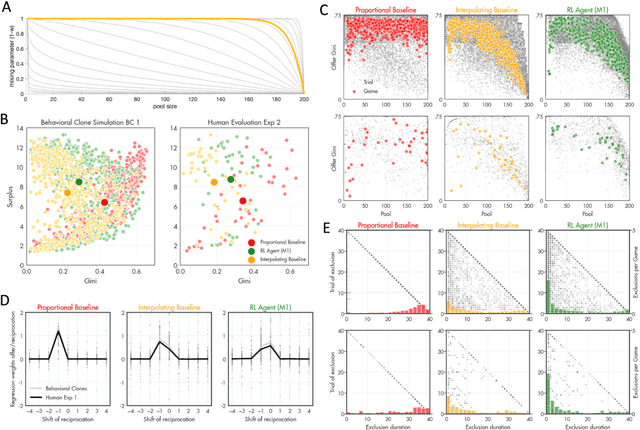
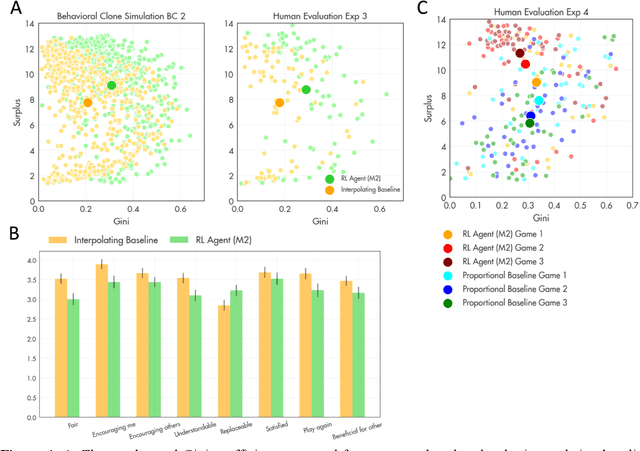
A canonical social dilemma arises when finite resources are allocated to a group of people, who can choose to either reciprocate with interest, or keep the proceeds for themselves. What resource allocation mechanisms will encourage levels of reciprocation that sustain the commons? Here, in an iterated multiplayer trust game, we use deep reinforcement learning (RL) to design an allocation mechanism that endogenously promotes sustainable contributions from human participants to a common pool resource. We first trained neural networks to behave like human players, creating a stimulated economy that allowed us to study how different mechanisms influenced the dynamics of receipt and reciprocation. We then used RL to train a social planner to maximise aggregate return to players. The social planner discovered a redistributive policy that led to a large surplus and an inclusive economy, in which players made roughly equal gains. The RL agent increased human surplus over baseline mechanisms based on unrestricted welfare or conditional cooperation, by conditioning its generosity on available resources and temporarily sanctioning defectors by allocating fewer resources to them. Examining the AI policy allowed us to develop an explainable mechanism that performed similarly and was more popular among players. Deep reinforcement learning can be used to discover mechanisms that promote sustainable human behaviour.
Rethinking Teacher-Student Curriculum Learning through the Cooperative Mechanics of Experience
Apr 03, 2024Teacher-Student Curriculum Learning (TSCL) is a curriculum learning framework that draws inspiration from human cultural transmission and learning. It involves a teacher algorithm shaping the learning process of a learner algorithm by exposing it to controlled experiences. Despite its success, understanding the conditions under which TSCL is effective remains challenging. In this paper, we propose a data-centric perspective to analyze the underlying mechanics of the teacher-student interactions in TSCL. We leverage cooperative game theory to describe how the composition of the set of experiences presented by the teacher to the learner, as well as their order, influences the performance of the curriculum that is found by TSCL approaches. To do so, we demonstrate that for every TSCL problem, there exists an equivalent cooperative game, and several key components of the TSCL framework can be reinterpreted using game-theoretic principles. Through experiments covering supervised learning, reinforcement learning, and classical games, we estimate the cooperative values of experiences and use value-proportional curriculum mechanisms to construct curricula, even in cases where TSCL struggles. The framework and experimental setup we present in this work represent a novel foundation for a deeper exploration of TSCL, shedding light on its underlying mechanisms and providing insights into its broader applicability in machine learning.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
Scaling Opponent Shaping to High Dimensional Games
Dec 19, 2023



In multi-agent settings with mixed incentives, methods developed for zero-sum games have been shown to lead to detrimental outcomes. To address this issue, opponent shaping (OS) methods explicitly learn to influence the learning dynamics of co-players and empirically lead to improved individual and collective outcomes. However, OS methods have only been evaluated in low-dimensional environments due to the challenges associated with estimating higher-order derivatives or scaling model-free meta-learning. Alternative methods that scale to more complex settings either converge to undesirable solutions or rely on unrealistic assumptions about the environment or co-players. In this paper, we successfully scale an OS-based approach to general-sum games with temporally-extended actions and long-time horizons for the first time. After analysing the representations of the meta-state and history used by previous algorithms, we propose a simplified version called Shaper. We show empirically that Shaper leads to improved individual and collective outcomes in a range of challenging settings from literature. We further formalize a technique previously implicit in the literature, and analyse its contribution to opponent shaping. We show empirically that this technique is helpful for the functioning of prior methods in certain environments. Lastly, we show that previous environments, such as the CoinGame, are inadequate for analysing temporally-extended general-sum interactions.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Turbocharging Solution Concepts: Solving NEs, CEs and CCEs with Neural Equilibrium Solvers
Oct 17, 2022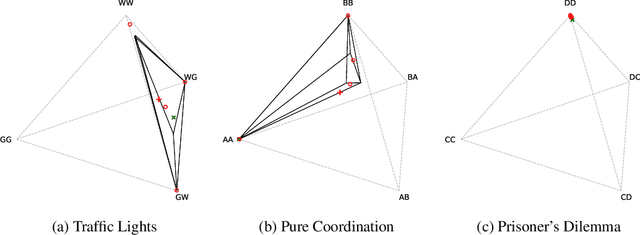
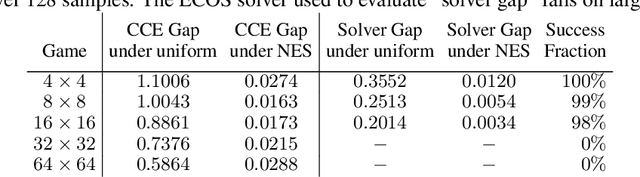

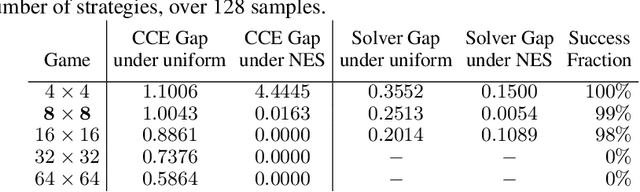
Solution concepts such as Nash Equilibria, Correlated Equilibria, and Coarse Correlated Equilibria are useful components for many multiagent machine learning algorithms. Unfortunately, solving a normal-form game could take prohibitive or non-deterministic time to converge, and could fail. We introduce the Neural Equilibrium Solver which utilizes a special equivariant neural network architecture to approximately solve the space of all games of fixed shape, buying speed and determinism. We define a flexible equilibrium selection framework, that is capable of uniquely selecting an equilibrium that minimizes relative entropy, or maximizes welfare. The network is trained without needing to generate any supervised training data. We show remarkable zero-shot generalization to larger games. We argue that such a network is a powerful component for many possible multiagent algorithms.
Developing, Evaluating and Scaling Learning Agents in Multi-Agent Environments
Sep 22, 2022The Game Theory & Multi-Agent team at DeepMind studies several aspects of multi-agent learning ranging from computing approximations to fundamental concepts in game theory to simulating social dilemmas in rich spatial environments and training 3-d humanoids in difficult team coordination tasks. A signature aim of our group is to use the resources and expertise made available to us at DeepMind in deep reinforcement learning to explore multi-agent systems in complex environments and use these benchmarks to advance our understanding. Here, we summarise the recent work of our team and present a taxonomy that we feel highlights many important open challenges in multi-agent research.
The Good Shepherd: An Oracle Agent for Mechanism Design
Feb 21, 2022

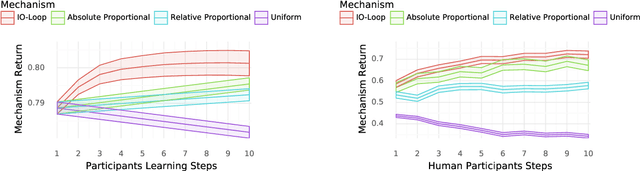
From social networks to traffic routing, artificial learning agents are playing a central role in modern institutions. We must therefore understand how to leverage these systems to foster outcomes and behaviors that align with our own values and aspirations. While multiagent learning has received considerable attention in recent years, artificial agents have been primarily evaluated when interacting with fixed, non-learning co-players. While this evaluation scheme has merit, it fails to capture the dynamics faced by institutions that must deal with adaptive and continually learning constituents. Here we address this limitation, and construct agents ("mechanisms") that perform well when evaluated over the learning trajectory of their adaptive co-players ("participants"). The algorithm we propose consists of two nested learning loops: an inner loop where participants learn to best respond to fixed mechanisms; and an outer loop where the mechanism agent updates its policy based on experience. We report the performance of our mechanism agents when paired with both artificial learning agents and humans as co-players. Our results show that our mechanisms are able to shepherd the participants strategies towards favorable outcomes, indicating a path for modern institutions to effectively and automatically influence the strategies and behaviors of their constituents.
HCMD-zero: Learning Value Aligned Mechanisms from Data
Feb 21, 2022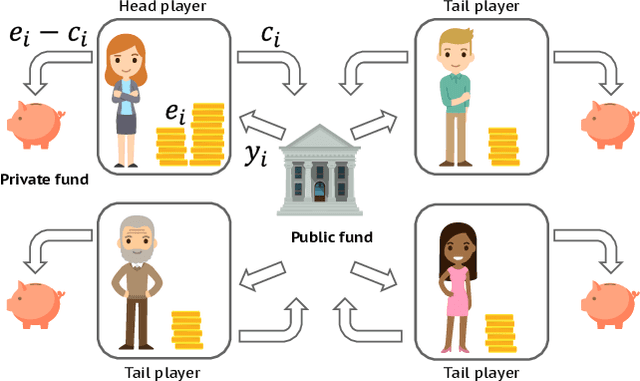

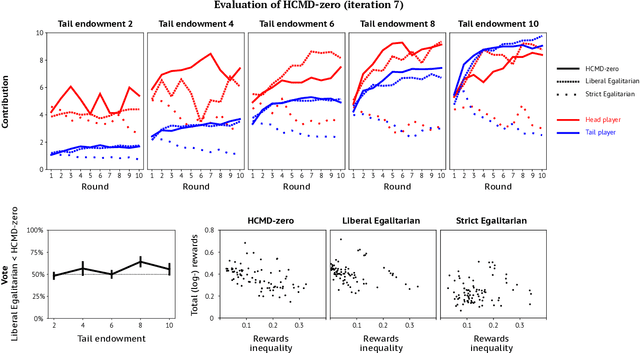
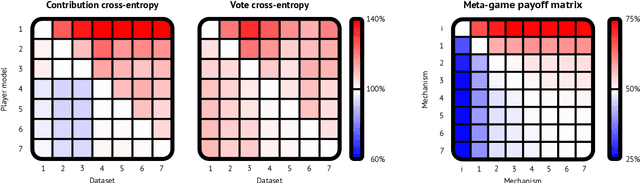
Artificial learning agents are mediating a larger and larger number of interactions among humans, firms, and organizations, and the intersection between mechanism design and machine learning has been heavily investigated in recent years. However, mechanism design methods make strong assumptions on how participants behave (e.g. rationality), or on the kind of knowledge designers have access to a priori (e.g. access to strong baseline mechanisms). Here we introduce HCMD-zero, a general purpose method to construct mechanism agents. HCMD-zero learns by mediating interactions among participants, while remaining engaged in an electoral contest with copies of itself, thereby accessing direct feedback from participants. Our results on the Public Investment Game, a stylized resource allocation game that highlights the tension between productivity, equality and the temptation to free-ride, show that HCMD-zero produces competitive mechanism agents that are consistently preferred by human participants over baseline alternatives, and does so automatically, without requiring human knowledge, and by using human data sparingly and effectively Our detailed analysis shows HCMD-zero elicits consistent improvements over the course of training, and that it results in a mechanism with an interpretable and intuitive policy.