 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHCMD-zero: Learning Value Aligned Mechanisms from Data
Feb 21, 2022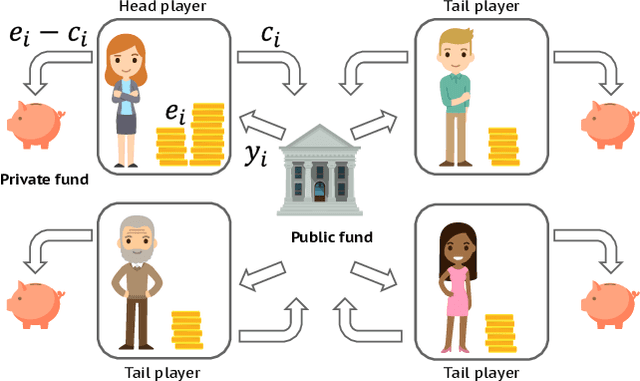

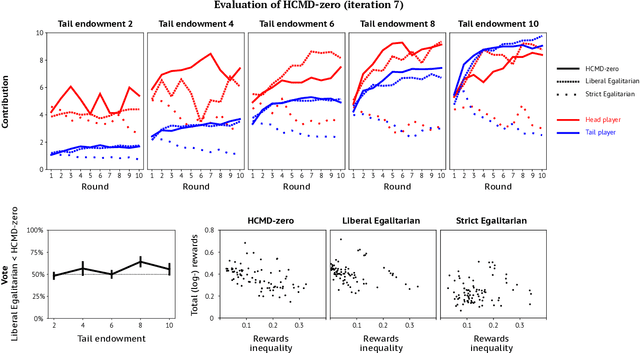
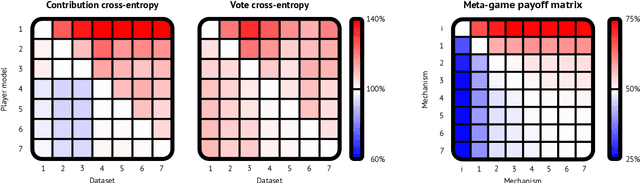
Artificial learning agents are mediating a larger and larger number of interactions among humans, firms, and organizations, and the intersection between mechanism design and machine learning has been heavily investigated in recent years. However, mechanism design methods make strong assumptions on how participants behave (e.g. rationality), or on the kind of knowledge designers have access to a priori (e.g. access to strong baseline mechanisms). Here we introduce HCMD-zero, a general purpose method to construct mechanism agents. HCMD-zero learns by mediating interactions among participants, while remaining engaged in an electoral contest with copies of itself, thereby accessing direct feedback from participants. Our results on the Public Investment Game, a stylized resource allocation game that highlights the tension between productivity, equality and the temptation to free-ride, show that HCMD-zero produces competitive mechanism agents that are consistently preferred by human participants over baseline alternatives, and does so automatically, without requiring human knowledge, and by using human data sparingly and effectively Our detailed analysis shows HCMD-zero elicits consistent improvements over the course of training, and that it results in a mechanism with an interpretable and intuitive policy.
Human-centered mechanism design with Democratic AI
Jan 27, 2022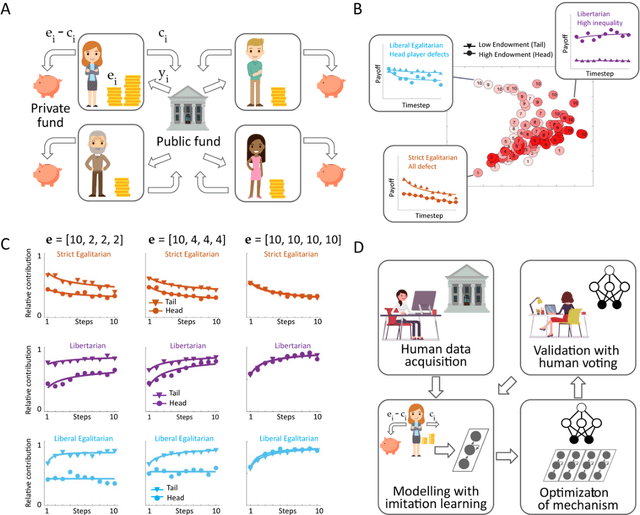
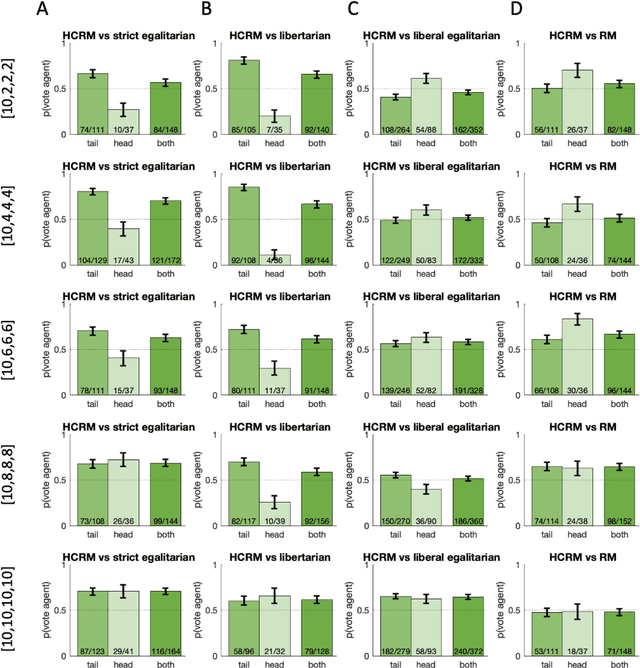
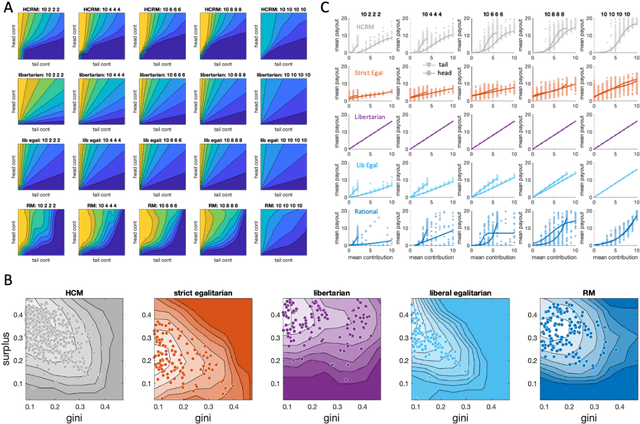
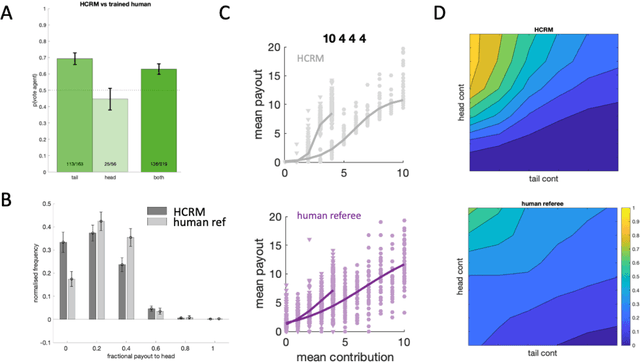
Building artificial intelligence (AI) that aligns with human values is an unsolved problem. Here, we developed a human-in-the-loop research pipeline called Democratic AI, in which reinforcement learning is used to design a social mechanism that humans prefer by majority. A large group of humans played an online investment game that involved deciding whether to keep a monetary endowment or to share it with others for collective benefit. Shared revenue was returned to players under two different redistribution mechanisms, one designed by the AI and the other by humans. The AI discovered a mechanism that redressed initial wealth imbalance, sanctioned free riders, and successfully won the majority vote. By optimizing for human preferences, Democratic AI may be a promising method for value-aligned policy innovation.
Probing Physics Knowledge Using Tools from Developmental Psychology
Apr 03, 2018


In order to build agents with a rich understanding of their environment, one key objective is to endow them with a grasp of intuitive physics; an ability to reason about three-dimensional objects, their dynamic interactions, and responses to forces. While some work on this problem has taken the approach of building in components such as ready-made physics engines, other research aims to extract general physical concepts directly from sensory data. In the latter case, one challenge that arises is evaluating the learning system. Research on intuitive physics knowledge in children has long employed a violation of expectations (VOE) method to assess children's mastery of specific physical concepts. We take the novel step of applying this method to artificial learning systems. In addition to introducing the VOE technique, we describe a set of probe datasets inspired by classic test stimuli from developmental psychology. We test a baseline deep learning system on this battery, as well as on a physics learning dataset ("IntPhys") recently posed by another research group. Our results show how the VOE technique may provide a useful tool for tracking physics knowledge in future research.
Structure Learning in Motor Control:A Deep Reinforcement Learning Model
Jul 13, 2017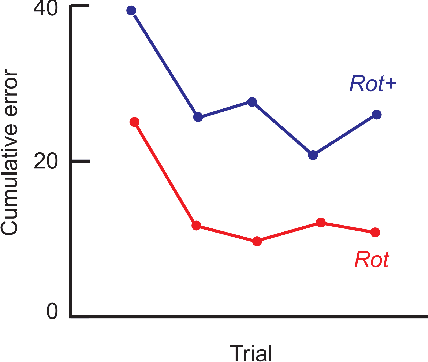
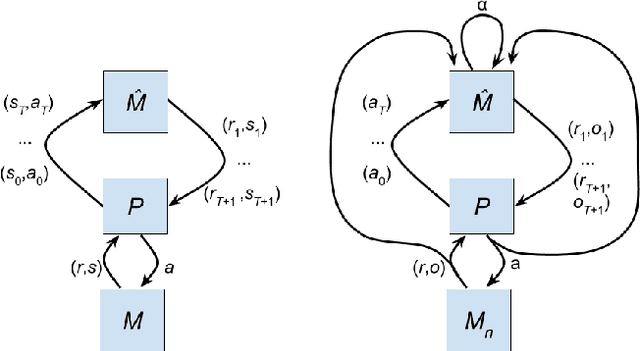
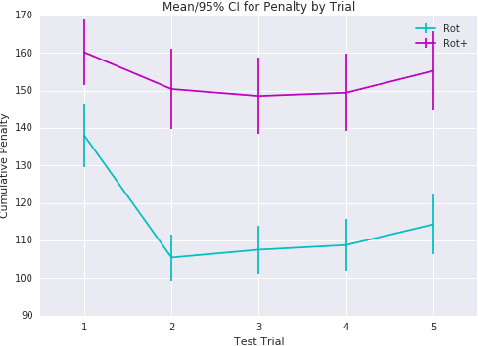
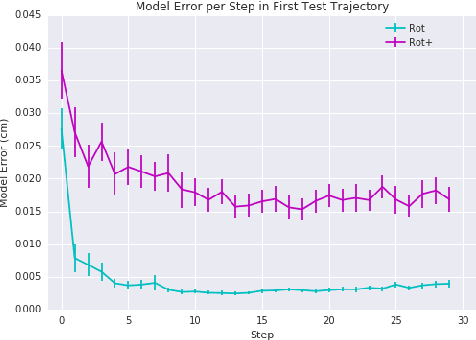
Motor adaptation displays a structure-learning effect: adaptation to a new perturbation occurs more quickly when the subject has prior exposure to perturbations with related structure. Although this `learning-to-learn' effect is well documented, its underlying computational mechanisms are poorly understood. We present a new model of motor structure learning, approaching it from the point of view of deep reinforcement learning. Previous work outside of motor control has shown how recurrent neural networks can account for learning-to-learn effects. We leverage this insight to address motor learning, by importing it into the setting of model-based reinforcement learning. We apply the resulting processing architecture to empirical findings from a landmark study of structure learning in target-directed reaching (Braun et al., 2009), and discuss its implications for a wider range of learning-to-learn phenomena.