 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-Augmented Reinforcement Learning
Mar 09, 2022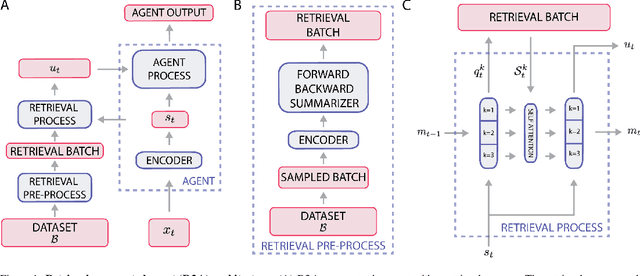

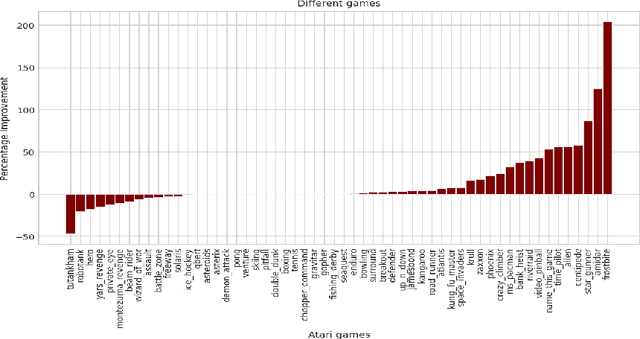
Most deep reinforcement learning (RL) algorithms distill experience into parametric behavior policies or value functions via gradient updates. While effective, this approach has several disadvantages: (1) it is computationally expensive, (2) it can take many updates to integrate experiences into the parametric model, (3) experiences that are not fully integrated do not appropriately influence the agent's behavior, and (4) behavior is limited by the capacity of the model. In this paper we explore an alternative paradigm in which we train a network to map a dataset of past experiences to optimal behavior. Specifically, we augment an RL agent with a retrieval process (parameterized as a neural network) that has direct access to a dataset of experiences. This dataset can come from the agent's past experiences, expert demonstrations, or any other relevant source. The retrieval process is trained to retrieve information from the dataset that may be useful in the current context, to help the agent achieve its goal faster and more efficiently. We integrate our method into two different RL agents: an offline DQN agent and an online R2D2 agent. In offline multi-task problems, we show that the retrieval-augmented DQN agent avoids task interference and learns faster than the baseline DQN agent. On Atari, we show that retrieval-augmented R2D2 learns significantly faster than the baseline R2D2 agent and achieves higher scores. We run extensive ablations to measure the contributions of the components of our proposed method.
Evaluating model-based planning and planner amortization for continuous control
Oct 07, 2021
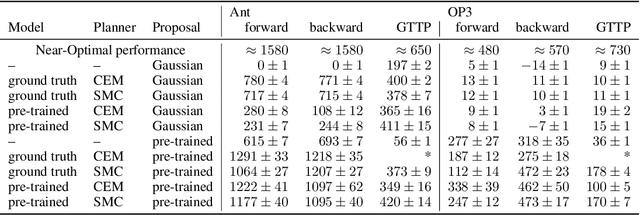
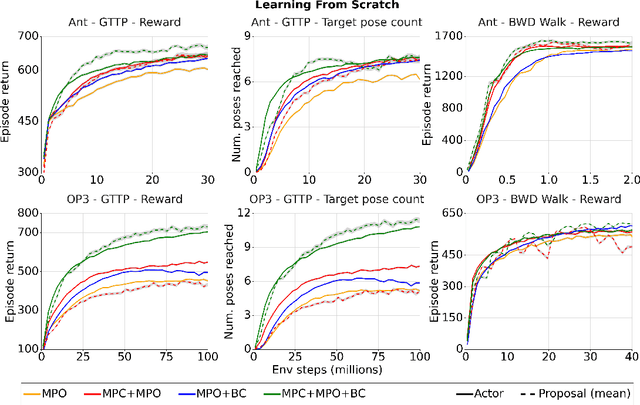
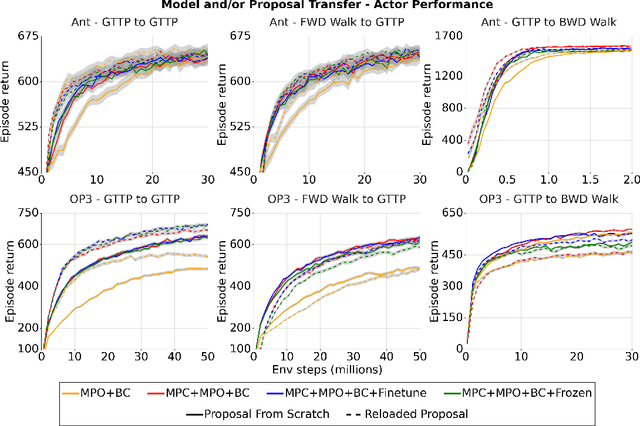
There is a widespread intuition that model-based control methods should be able to surpass the data efficiency of model-free approaches. In this paper we attempt to evaluate this intuition on various challenging locomotion tasks. We take a hybrid approach, combining model predictive control (MPC) with a learned model and model-free policy learning; the learned policy serves as a proposal for MPC. We find that well-tuned model-free agents are strong baselines even for high DoF control problems but MPC with learned proposals and models (trained on the fly or transferred from related tasks) can significantly improve performance and data efficiency in hard multi-task/multi-goal settings. Finally, we show that it is possible to distil a model-based planner into a policy that amortizes the planning computation without any loss of performance. Videos of agents performing different tasks can be seen at https://sites.google.com/view/mbrl-amortization/home.
Beyond Tabula-Rasa: a Modular Reinforcement Learning Approach for Physically Embedded 3D Sokoban
Oct 03, 2020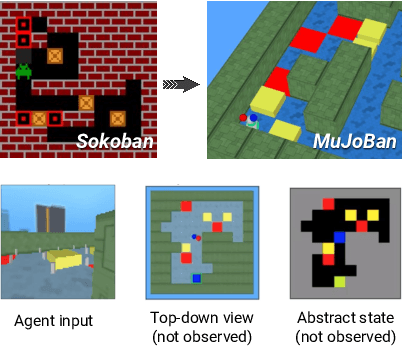
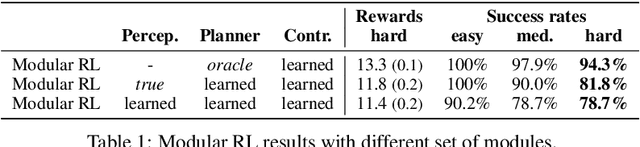

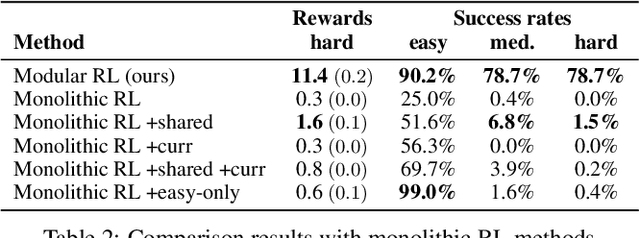
Intelligent robots need to achieve abstract objectives using concrete, spatiotemporally complex sensory information and motor control. Tabula rasa deep reinforcement learning (RL) has tackled demanding tasks in terms of either visual, abstract, or physical reasoning, but solving these jointly remains a formidable challenge. One recent, unsolved benchmark task that integrates these challenges is Mujoban, where a robot needs to arrange 3D warehouses generated from 2D Sokoban puzzles. We explore whether integrated tasks like Mujoban can be solved by composing RL modules together in a sense-plan-act hierarchy, where modules have well-defined roles similarly to classic robot architectures. Unlike classic architectures that are typically model-based, we use only model-free modules trained with RL or supervised learning. We find that our modular RL approach dramatically outperforms the state-of-the-art monolithic RL agent on Mujoban. Further, learned modules can be reused when, e.g., using a different robot platform to solve the same task. Together our results give strong evidence for the importance of research into modular RL designs. Project website: https://sites.google.com/view/modular-rl/
Physically Embedded Planning Problems: New Challenges for Reinforcement Learning
Sep 11, 2020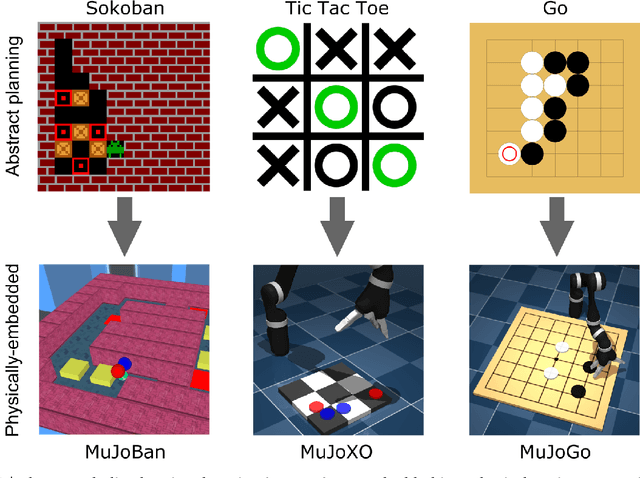


Recent work in deep reinforcement learning (RL) has produced algorithms capable of mastering challenging games such as Go, chess, or shogi. In these works the RL agent directly observes the natural state of the game and controls that state directly with its actions. However, when humans play such games, they do not just reason about the moves but also interact with their physical environment. They understand the state of the game by looking at the physical board in front of them and modify it by manipulating pieces using touch and fine-grained motor control. Mastering complicated physical systems with abstract goals is a central challenge for artificial intelligence, but it remains out of reach for existing RL algorithms. To encourage progress towards this goal we introduce a set of physically embedded planning problems and make them publicly available. We embed challenging symbolic tasks (Sokoban, tic-tac-toe, and Go) in a physics engine to produce a set of tasks that require perception, reasoning, and motor control over long time horizons. Although existing RL algorithms can tackle the symbolic versions of these tasks, we find that they struggle to master even the simplest of their physically embedded counterparts. As a first step towards characterizing the space of solution to these tasks, we introduce a strong baseline that uses a pre-trained expert game player to provide hints in the abstract space to an RL agent's policy while training it on the full sensorimotor control task. The resulting agent solves many of the tasks, underlining the need for methods that bridge the gap between abstract planning and embodied control.
An investigation of model-free planning
Jan 11, 2019
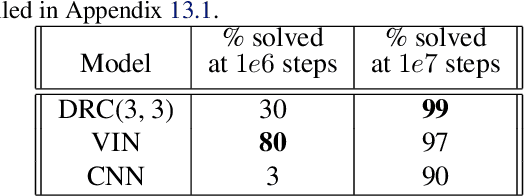
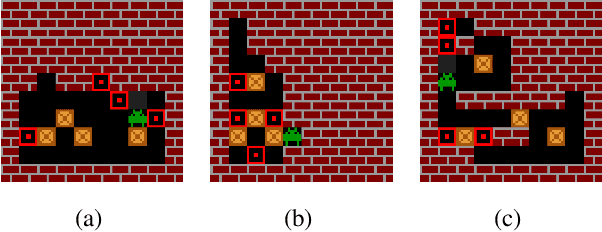
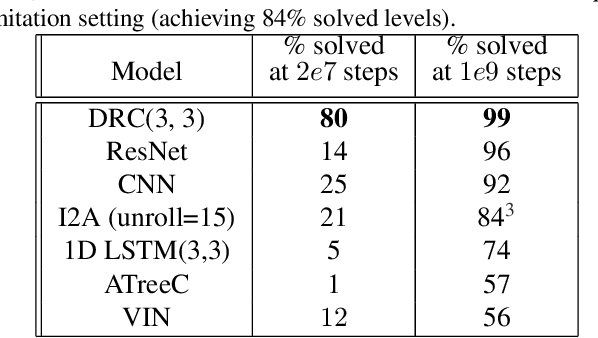
The field of reinforcement learning (RL) is facing increasingly challenging domains with combinatorial complexity. For an RL agent to address these challenges, it is essential that it can plan effectively. Prior work has typically utilized an explicit model of the environment, combined with a specific planning algorithm (such as tree search). More recently, a new family of methods have been proposed that learn how to plan, by providing the structure for planning via an inductive bias in the function approximator (such as a tree structured neural network), trained end-to-end by a model-free RL algorithm. In this paper, we go even further, and demonstrate empirically that an entirely model-free approach, without special structure beyond standard neural network components such as convolutional networks and LSTMs, can learn to exhibit many of the characteristics typically associated with a model-based planner. We measure our agent's effectiveness at planning in terms of its ability to generalize across a combinatorial and irreversible state space, its data efficiency, and its ability to utilize additional thinking time. We find that our agent has many of the characteristics that one might expect to find in a planning algorithm. Furthermore, it exceeds the state-of-the-art in challenging combinatorial domains such as Sokoban and outperforms other model-free approaches that utilize strong inductive biases toward planning.
Optimizing Agent Behavior over Long Time Scales by Transporting Value
Oct 15, 2018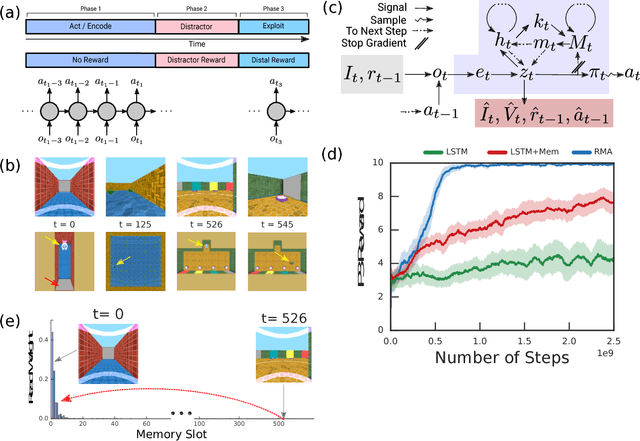
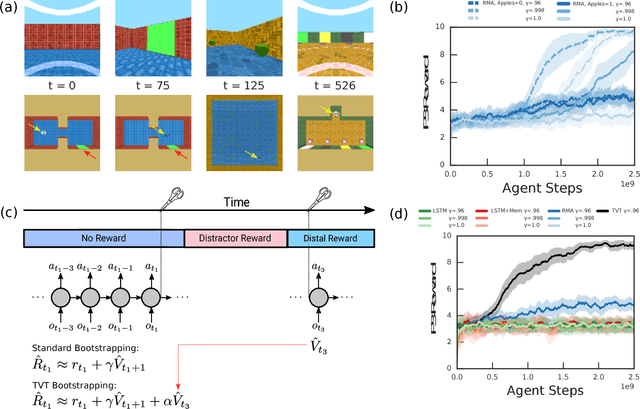
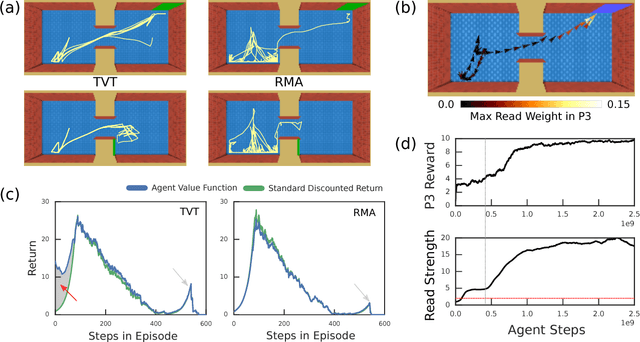
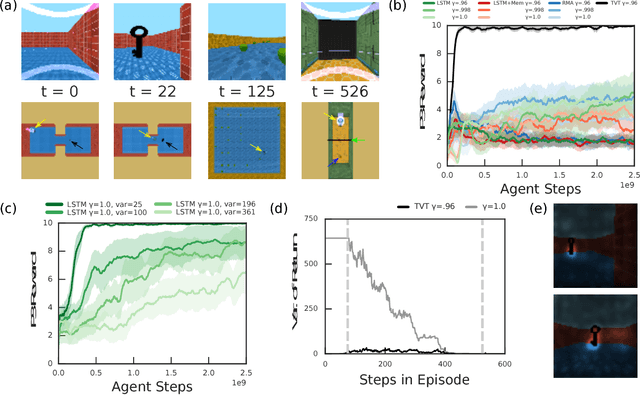
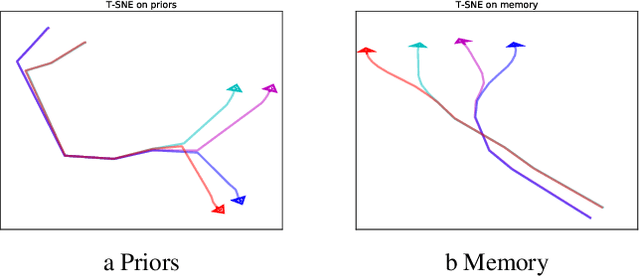
Humans spend a remarkable fraction of waking life engaged in acts of "mental time travel". We dwell on our actions in the past and experience satisfaction or regret. More than merely autobiographical storytelling, we use these event recollections to change how we will act in similar scenarios in the future. This process endows us with a computationally important ability to link actions and consequences across long spans of time, which figures prominently in addressing the problem of long-term temporal credit assignment; in artificial intelligence (AI) this is the question of how to evaluate the utility of the actions within a long-duration behavioral sequence leading to success or failure in a task. Existing approaches to shorter-term credit assignment in AI cannot solve tasks with long delays between actions and consequences. Here, we introduce a new paradigm for reinforcement learning where agents use recall of specific memories to credit actions from the past, allowing them to solve problems that are intractable for existing algorithms. This paradigm broadens the scope of problems that can be investigated in AI and offers a mechanistic account of behaviors that may inspire computational models in neuroscience, psychology, and behavioral economics.
Probing Physics Knowledge Using Tools from Developmental Psychology
Apr 03, 2018


In order to build agents with a rich understanding of their environment, one key objective is to endow them with a grasp of intuitive physics; an ability to reason about three-dimensional objects, their dynamic interactions, and responses to forces. While some work on this problem has taken the approach of building in components such as ready-made physics engines, other research aims to extract general physical concepts directly from sensory data. In the latter case, one challenge that arises is evaluating the learning system. Research on intuitive physics knowledge in children has long employed a violation of expectations (VOE) method to assess children's mastery of specific physical concepts. We take the novel step of applying this method to artificial learning systems. In addition to introducing the VOE technique, we describe a set of probe datasets inspired by classic test stimuli from developmental psychology. We test a baseline deep learning system on this battery, as well as on a physics learning dataset ("IntPhys") recently posed by another research group. Our results show how the VOE technique may provide a useful tool for tracking physics knowledge in future research.
Unsupervised Predictive Memory in a Goal-Directed Agent
Mar 28, 2018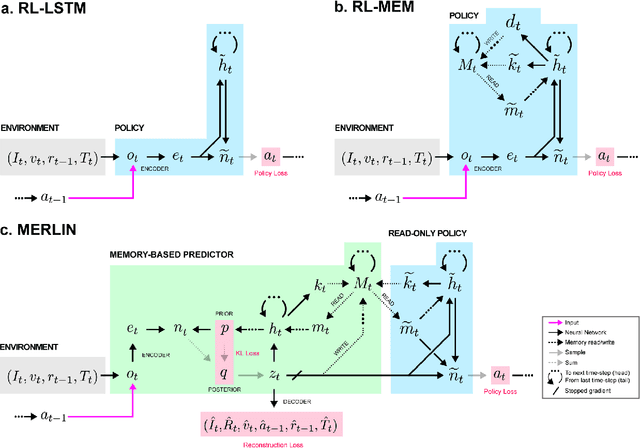
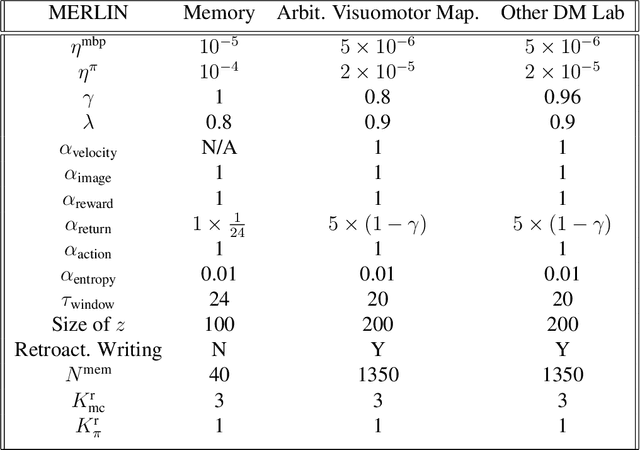
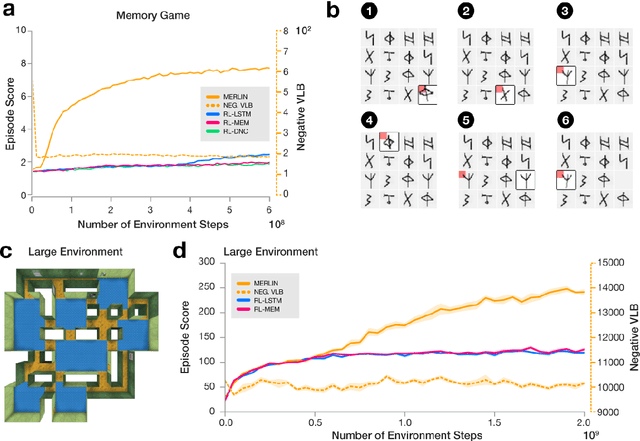

Animals execute goal-directed behaviours despite the limited range and scope of their sensors. To cope, they explore environments and store memories maintaining estimates of important information that is not presently available. Recently, progress has been made with artificial intelligence (AI) agents that learn to perform tasks from sensory input, even at a human level, by merging reinforcement learning (RL) algorithms with deep neural networks, and the excitement surrounding these results has led to the pursuit of related ideas as explanations of non-human animal learning. However, we demonstrate that contemporary RL algorithms struggle to solve simple tasks when enough information is concealed from the sensors of the agent, a property called "partial observability". An obvious requirement for handling partially observed tasks is access to extensive memory, but we show memory is not enough; it is critical that the right information be stored in the right format. We develop a model, the Memory, RL, and Inference Network (MERLIN), in which memory formation is guided by a process of predictive modeling. MERLIN facilitates the solution of tasks in 3D virtual reality environments for which partial observability is severe and memories must be maintained over long durations. Our model demonstrates a single learning agent architecture that can solve canonical behavioural tasks in psychology and neurobiology without strong simplifying assumptions about the dimensionality of sensory input or the duration of experiences.
Generalizable Features From Unsupervised Learning
Dec 12, 2016


Humans learn a predictive model of the world and use this model to reason about future events and the consequences of actions. In contrast to most machine predictors, we exhibit an impressive ability to generalize to unseen scenarios and reason intelligently in these settings. One important aspect of this ability is physical intuition(Lake et al., 2016). In this work, we explore the potential of unsupervised learning to find features that promote better generalization to settings outside the supervised training distribution. Our task is predicting the stability of towers of square blocks. We demonstrate that an unsupervised model, trained to predict future frames of a video sequence of stable and unstable block configurations, can yield features that support extrapolating stability prediction to blocks configurations outside the training set distribution
Asynchronous Methods for Deep Reinforcement Learning
Jun 16, 2016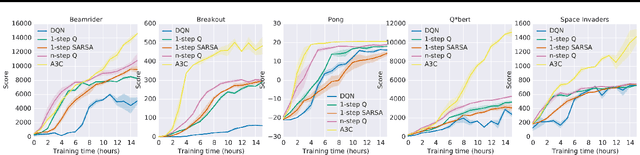
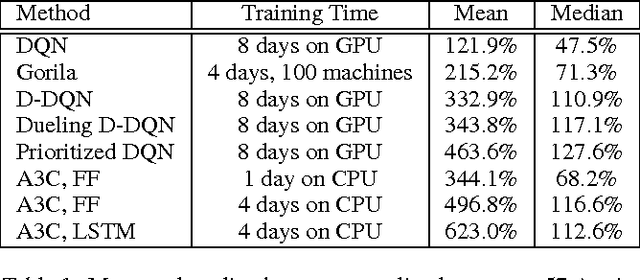
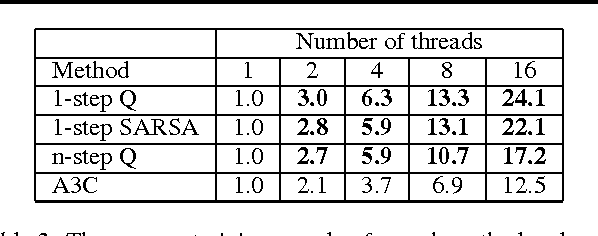
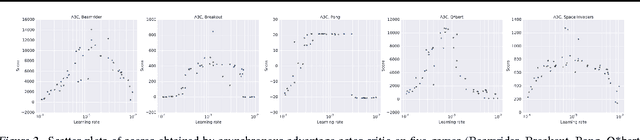
We propose a conceptually simple and lightweight framework for deep reinforcement learning that uses asynchronous gradient descent for optimization of deep neural network controllers. We present asynchronous variants of four standard reinforcement learning algorithms and show that parallel actor-learners have a stabilizing effect on training allowing all four methods to successfully train neural network controllers. The best performing method, an asynchronous variant of actor-critic, surpasses the current state-of-the-art on the Atari domain while training for half the time on a single multi-core CPU instead of a GPU. Furthermore, we show that asynchronous actor-critic succeeds on a wide variety of continuous motor control problems as well as on a new task of navigating random 3D mazes using a visual input.