 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-analytical Industrial Cooling System Model for Reinforcement Learning
Jul 26, 2022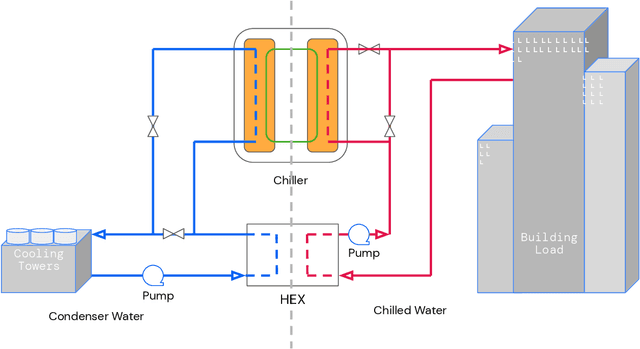
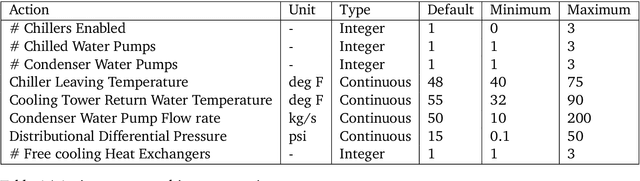
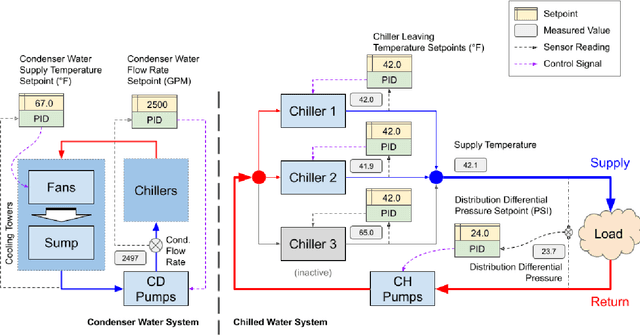
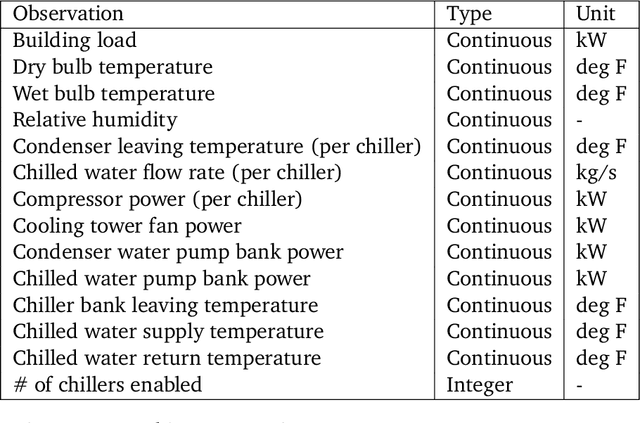
We present a hybrid industrial cooling system model that embeds analytical solutions within a multi-physics simulation. This model is designed for reinforcement learning (RL) applications and balances simplicity with simulation fidelity and interpretability. The model's fidelity is evaluated against real world data from a large scale cooling system. This is followed by a case study illustrating how the model can be used for RL research. For this, we develop an industrial task suite that allows specifying different problem settings and levels of complexity, and use it to evaluate the performance of different RL algorithms.
Evaluating model-based planning and planner amortization for continuous control
Oct 07, 2021
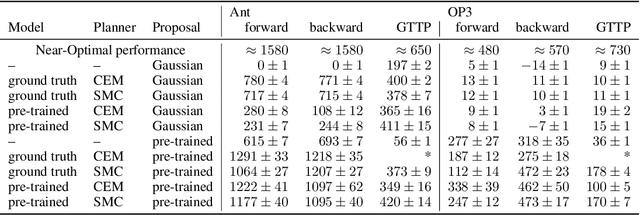
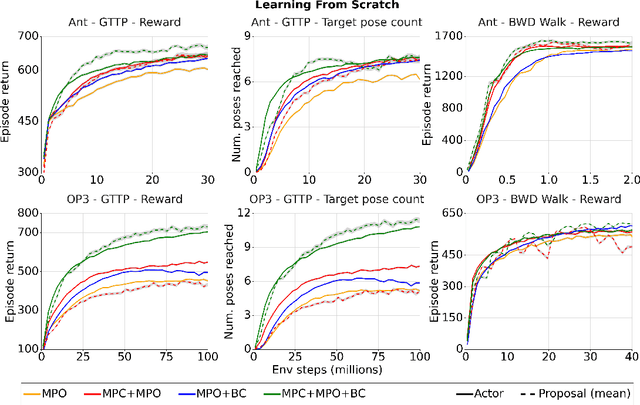
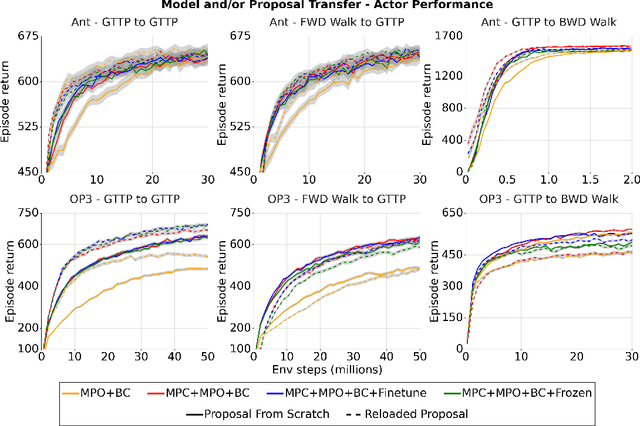
There is a widespread intuition that model-based control methods should be able to surpass the data efficiency of model-free approaches. In this paper we attempt to evaluate this intuition on various challenging locomotion tasks. We take a hybrid approach, combining model predictive control (MPC) with a learned model and model-free policy learning; the learned policy serves as a proposal for MPC. We find that well-tuned model-free agents are strong baselines even for high DoF control problems but MPC with learned proposals and models (trained on the fly or transferred from related tasks) can significantly improve performance and data efficiency in hard multi-task/multi-goal settings. Finally, we show that it is possible to distil a model-based planner into a policy that amortizes the planning computation without any loss of performance. Videos of agents performing different tasks can be seen at https://sites.google.com/view/mbrl-amortization/home.
Learning Dynamics Models for Model Predictive Agents
Sep 29, 2021
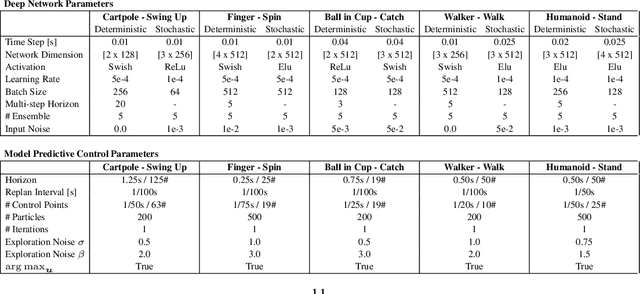
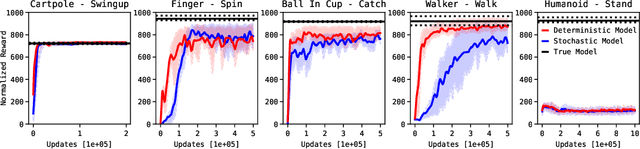
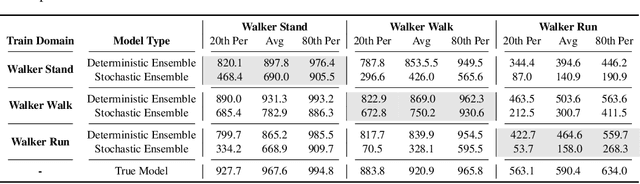
Model-Based Reinforcement Learning involves learning a \textit{dynamics model} from data, and then using this model to optimise behaviour, most often with an online \textit{planner}. Much of the recent research along these lines presents a particular set of design choices, involving problem definition, model learning and planning. Given the multiple contributions, it is difficult to evaluate the effects of each. This paper sets out to disambiguate the role of different design choices for learning dynamics models, by comparing their performance to planning with a ground-truth model -- the simulator. First, we collect a rich dataset from the training sequence of a model-free agent on 5 domains of the DeepMind Control Suite. Second, we train feed-forward dynamics models in a supervised fashion, and evaluate planner performance while varying and analysing different model design choices, including ensembling, stochasticity, multi-step training and timestep size. Besides the quantitative analysis, we describe a set of qualitative findings, rules of thumb, and future research directions for planning with learned dynamics models. Videos of the results are available at https://sites.google.com/view/learning-better-models.
Using Unity to Help Solve Intelligence
Nov 18, 2020
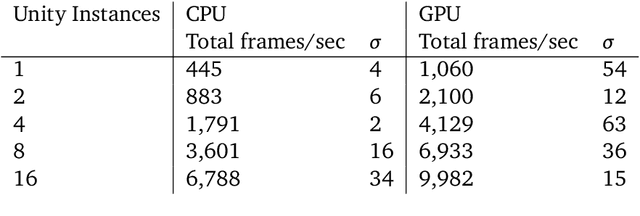
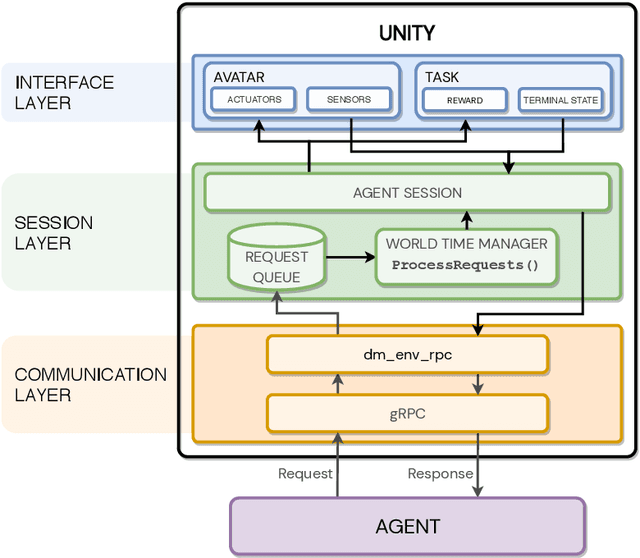

In the pursuit of artificial general intelligence, our most significant measurement of progress is an agent's ability to achieve goals in a wide range of environments. Existing platforms for constructing such environments are typically constrained by the technologies they are founded on, and are therefore only able to provide a subset of scenarios necessary to evaluate progress. To overcome these shortcomings, we present our use of Unity, a widely recognized and comprehensive game engine, to create more diverse, complex, virtual simulations. We describe the concepts and components developed to simplify the authoring of these environments, intended for use predominantly in the field of reinforcement learning. We also introduce a practical approach to packaging and re-distributing environments in a way that attempts to improve the robustness and reproducibility of experiment results. To illustrate the versatility of our use of Unity compared to other solutions, we highlight environments already created using our approach from published papers. We hope that others can draw inspiration from how we adapted Unity to our needs, and anticipate increasingly varied and complex environments to emerge from our approach as familiarity grows.
Augmenting learning using symmetry in a biologically-inspired domain
Oct 01, 2019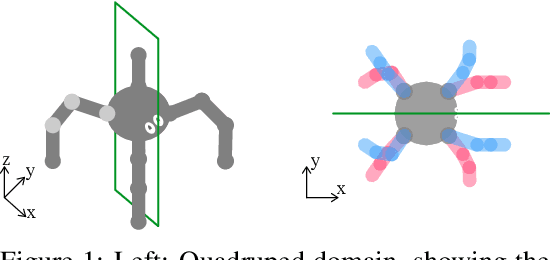
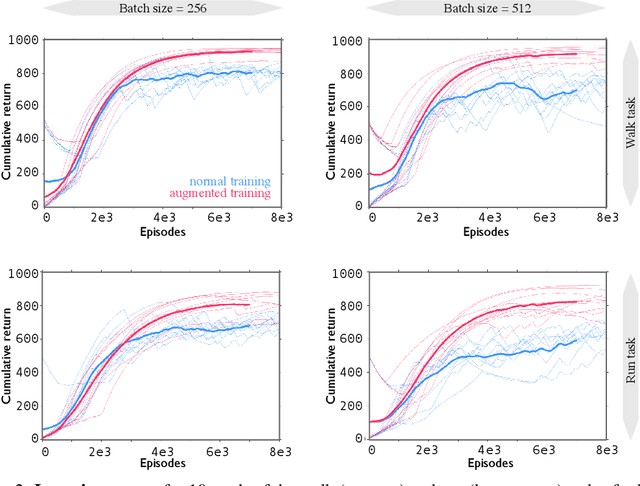
Invariances to translation, rotation and other spatial transformations are a hallmark of the laws of motion, and have widespread use in the natural sciences to reduce the dimensionality of systems of equations. In supervised learning, such as in image classification tasks, rotation, translation and scale invariances are used to augment training datasets. In this work, we use data augmentation in a similar way, exploiting symmetry in the quadruped domain of the DeepMind control suite (Tassa et al. 2018) to add to the trajectories experienced by the actor in the actor-critic algorithm of Abdolmaleki et al. (2018). In a data-limited regime, the agent using a set of experiences augmented through symmetry is able to learn faster. Our approach can be used to inject knowledge of invariances in the domain and task to augment learning in robots, and more generally, to speed up learning in realistic robotics applications.