 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChoose Your Agent: Tradeoffs in Adopting AI Advisors, Coaches, and Delegates in Multi-Party Negotiation
Feb 13, 2026As AI usage becomes more prevalent in social contexts, understanding agent-user interaction is critical to designing systems that improve both individual and group outcomes. We present an online behavioral experiment (N = 243) in which participants play three multi-turn bargaining games in groups of three. Each game, presented in randomized order, grants access to a single LLM assistance modality: proactive recommendations from an Advisor, reactive feedback from a Coach, or autonomous execution by a Delegate; all modalities are powered by an underlying LLM that achieves superhuman performance in an all-agent environment. On each turn, participants privately decide whether to act manually or use the AI modality available in that game. Despite preferring the Advisor modality, participants achieve the highest mean individual gains with the Delegate, demonstrating a preference-performance misalignment. Moreover, delegation generates positive externalities; even non-adopting users in access-to-delegate treatment groups benefit by receiving higher-quality offers. Mechanism analysis reveals that the Delegate agent acts as a market maker, injecting rational, Pareto-improving proposals that restructure the trading environment. Our research reveals a gap between agent capabilities and realized group welfare. While autonomous agents can exhibit super-human strategic performance, their impact on realized welfare gains can be constrained by interfaces, user perceptions, and adoption barriers. Assistance modalities should be designed as mechanisms with endogenous participation; adoption-compatible interaction rules are a prerequisite to improving human welfare with automated assistance.
To Mask or to Mirror: Human-AI Alignment in Collective Reasoning
Oct 02, 2025As large language models (LLMs) are increasingly used to model and augment collective decision-making, it is critical to examine their alignment with human social reasoning. We present an empirical framework for assessing collective alignment, in contrast to prior work on the individual level. Using the Lost at Sea social psychology task, we conduct a large-scale online experiment (N=748), randomly assigning groups to leader elections with either visible demographic attributes (e.g. name, gender) or pseudonymous aliases. We then simulate matched LLM groups conditioned on the human data, benchmarking Gemini 2.5, GPT 4.1, Claude Haiku 3.5, and Gemma 3. LLM behaviors diverge: some mirror human biases; others mask these biases and attempt to compensate for them. We empirically demonstrate that human-AI alignment in collective reasoning depends on context, cues, and model-specific inductive biases. Understanding how LLMs align with collective human behavior is critical to advancing socially-aligned AI, and demands dynamic benchmarks that capture the complexities of collective reasoning.
Understanding Economic Tradeoffs Between Human and AI Agents in Bargaining Games
Sep 11, 2025



Coordination tasks traditionally performed by humans are increasingly being delegated to autonomous agents. As this pattern progresses, it becomes critical to evaluate not only these agents' performance but also the processes through which they negotiate in dynamic, multi-agent environments. Furthermore, different agents exhibit distinct advantages: traditional statistical agents, such as Bayesian models, may excel under well-specified conditions, whereas large language models (LLMs) can generalize across contexts. In this work, we compare humans (N = 216), LLMs (GPT-4o, Gemini 1.5 Pro), and Bayesian agents in a dynamic negotiation setting that enables direct, identical-condition comparisons across populations, capturing both outcomes and behavioral dynamics. Bayesian agents extract the highest surplus through aggressive optimization, at the cost of frequent trade rejections. Humans and LLMs can achieve similar overall surplus, but through distinct behaviors: LLMs favor conservative, concessionary trades with few rejections, while humans employ more strategic, risk-taking, and fairness-oriented behaviors. Thus, we find that performance parity -- a common benchmark in agent evaluation -- can conceal fundamental differences in process and alignment, which are critical for practical deployment in real-world coordination tasks.
The Evolution of LLM Adoption in Industry Data Curation Practices
Dec 20, 2024



As large language models (LLMs) grow increasingly adept at processing unstructured text data, they offer new opportunities to enhance data curation workflows. This paper explores the evolution of LLM adoption among practitioners at a large technology company, evaluating the impact of LLMs in data curation tasks through participants' perceptions, integration strategies, and reported usage scenarios. Through a series of surveys, interviews, and user studies, we provide a timely snapshot of how organizations are navigating a pivotal moment in LLM evolution. In Q2 2023, we conducted a survey to assess LLM adoption in industry for development tasks (N=84), and facilitated expert interviews to assess evolving data needs (N=10) in Q3 2023. In Q2 2024, we explored practitioners' current and anticipated LLM usage through a user study involving two LLM-based prototypes (N=12). While each study addressed distinct research goals, they revealed a broader narrative about evolving LLM usage in aggregate. We discovered an emerging shift in data understanding from heuristic-first, bottom-up approaches to insights-first, top-down workflows supported by LLMs. Furthermore, to respond to a more complex data landscape, data practitioners now supplement traditional subject-expert-created 'golden datasets' with LLM-generated 'silver' datasets and rigorously validated 'super golden' datasets curated by diverse experts. This research sheds light on the transformative role of LLMs in large-scale analysis of unstructured data and highlights opportunities for further tool development.
The Moral Turing Test: Evaluating Human-LLM Alignment in Moral Decision-Making
Oct 09, 2024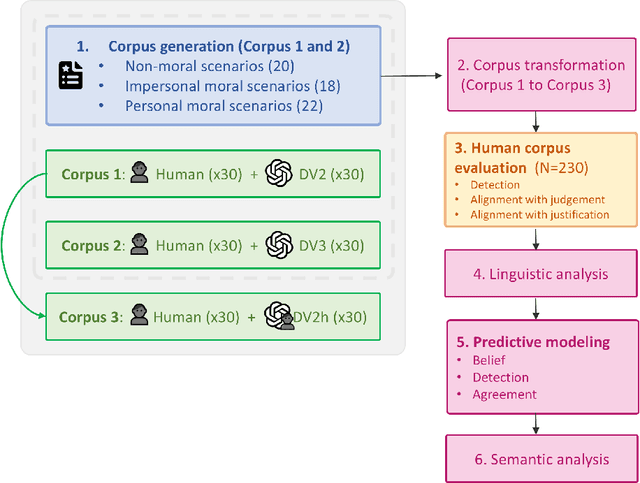
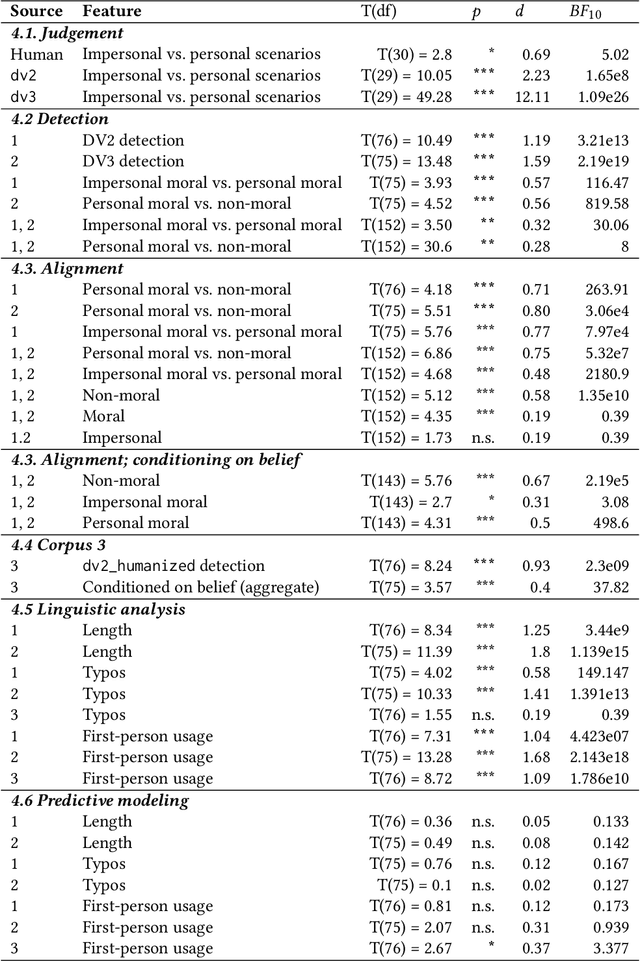
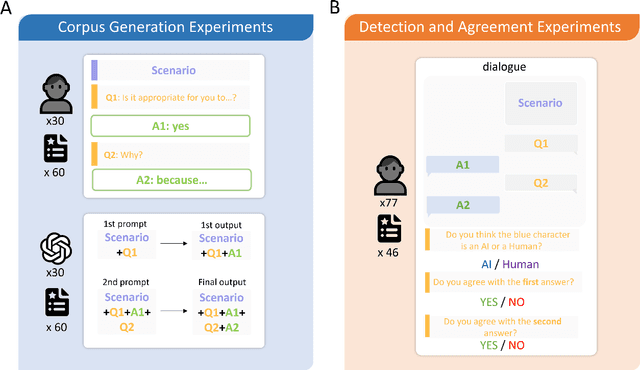
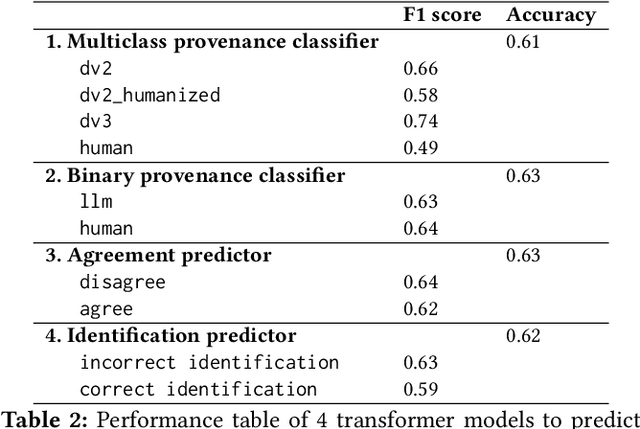
As large language models (LLMs) become increasingly integrated into society, their alignment with human morals is crucial. To better understand this alignment, we created a large corpus of human- and LLM-generated responses to various moral scenarios. We found a misalignment between human and LLM moral assessments; although both LLMs and humans tended to reject morally complex utilitarian dilemmas, LLMs were more sensitive to personal framing. We then conducted a quantitative user study involving 230 participants (N=230), who evaluated these responses by determining whether they were AI-generated and assessed their agreement with the responses. Human evaluators preferred LLMs' assessments in moral scenarios, though a systematic anti-AI bias was observed: participants were less likely to agree with judgments they believed to be machine-generated. Statistical and NLP-based analyses revealed subtle linguistic differences in responses, influencing detection and agreement. Overall, our findings highlight the complexities of human-AI perception in morally charged decision-making.
Automatic Histograms: Leveraging Language Models for Text Dataset Exploration
Feb 21, 2024Making sense of unstructured text datasets is perennially difficult, yet increasingly relevant with Large Language Models. Data workers often rely on dataset summaries, especially distributions of various derived features. Some features, like toxicity or topics, are relevant to many datasets, but many interesting features are domain specific: instruments and genres for a music dataset, or diseases and symptoms for a medical dataset. Accordingly, data workers often run custom analyses for each dataset, which is cumbersome and difficult. We present AutoHistograms, a visualization tool leveragingLLMs. AutoHistograms automatically identifies relevant features, visualizes them with histograms, and allows the user to interactively query the dataset for categories of entities and create new histograms. In a user study with 10 data workers (n=10), we observe that participants can quickly identify insights and explore the data using AutoHistograms, and conceptualize a broad range of applicable use cases. Together, this tool and user study contributeto the growing field of LLM-assisted sensemaking tools.
Understanding the Dataset Practitioners Behind Large Language Model Development
Feb 21, 2024

As large language models (LLMs) become more advanced and impactful, it is increasingly important to scrutinize the data that they rely upon and produce. What is it to be a dataset practitioner doing this work? We approach this in two parts: first, we define the role of "dataset practitioner" by performing a retrospective analysis on the responsibilities of teams contributing to LLM development at Google. Then, we conduct semi-structured interviews with a cross-section of these practitioners (N=10). We find that data quality is the top priority. To evaluate data quality, practitioners either rely on their own intuition or write custom evaluation logic. There is a lack of consensus across practitioners on what quality is and how to evaluate it. We discuss potential reasons for this phenomenon and opportunities for alignment.
Controlling Commercial Cooling Systems Using Reinforcement Learning
Nov 11, 2022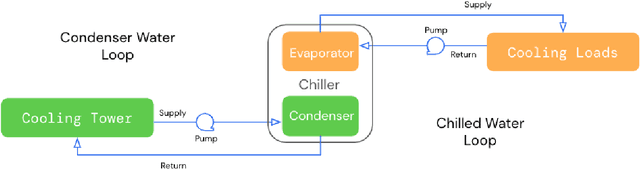
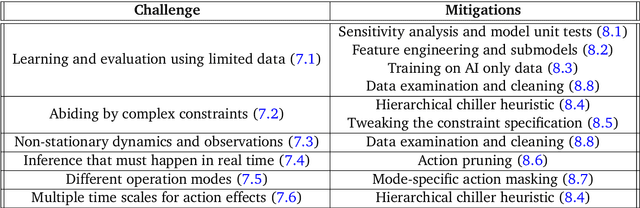
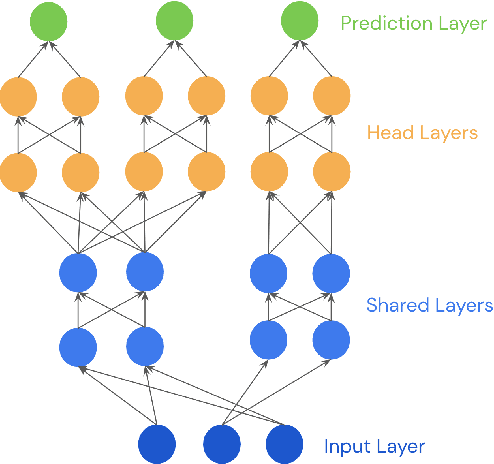
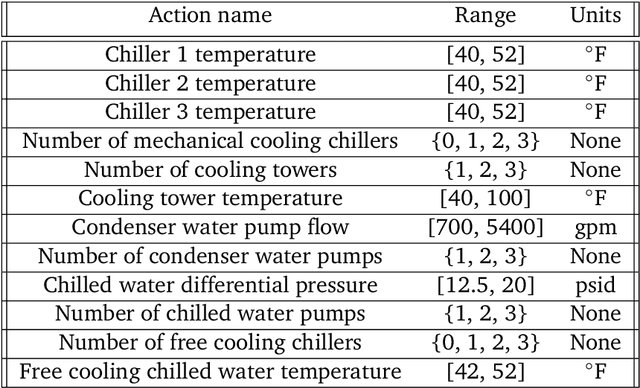
This paper is a technical overview of DeepMind and Google's recent work on reinforcement learning for controlling commercial cooling systems. Building on expertise that began with cooling Google's data centers more efficiently, we recently conducted live experiments on two real-world facilities in partnership with Trane Technologies, a building management system provider. These live experiments had a variety of challenges in areas such as evaluation, learning from offline data, and constraint satisfaction. Our paper describes these challenges in the hope that awareness of them will benefit future applied RL work. We also describe the way we adapted our RL system to deal with these challenges, resulting in energy savings of approximately 9% and 13% respectively at the two live experiment sites.
Semi-analytical Industrial Cooling System Model for Reinforcement Learning
Jul 26, 2022
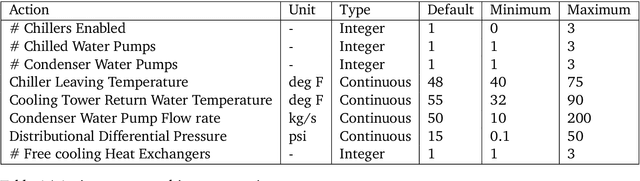
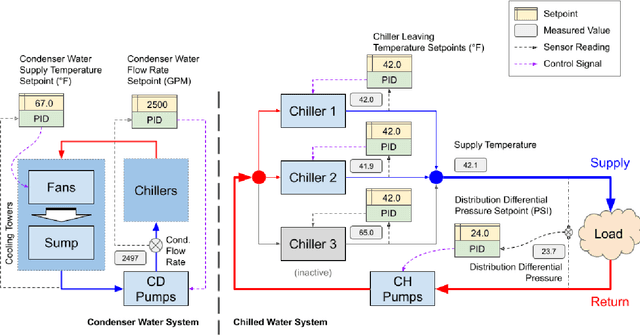
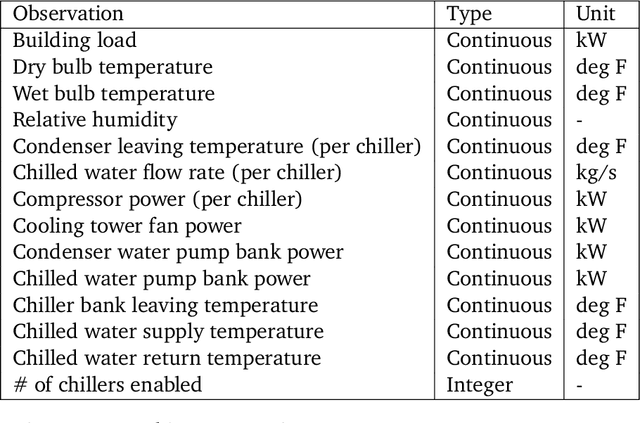
We present a hybrid industrial cooling system model that embeds analytical solutions within a multi-physics simulation. This model is designed for reinforcement learning (RL) applications and balances simplicity with simulation fidelity and interpretability. The model's fidelity is evaluated against real world data from a large scale cooling system. This is followed by a case study illustrating how the model can be used for RL research. For this, we develop an industrial task suite that allows specifying different problem settings and levels of complexity, and use it to evaluate the performance of different RL algorithms.