 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Prompts Don't Say: Understanding and Managing Underspecification in LLM Prompts
May 19, 2025Building LLM-powered software requires developers to communicate their requirements through natural language, but developer prompts are frequently underspecified, failing to fully capture many user-important requirements. In this paper, we present an in-depth analysis of prompt underspecification, showing that while LLMs can often (41.1%) guess unspecified requirements by default, such behavior is less robust: Underspecified prompts are 2x more likely to regress over model or prompt changes, sometimes with accuracy drops by more than 20%. We then demonstrate that simply adding more requirements to a prompt does not reliably improve performance, due to LLMs' limited instruction-following capabilities and competing constraints, and standard prompt optimizers do not offer much help. To address this, we introduce novel requirements-aware prompt optimization mechanisms that can improve performance by 4.8% on average over baselines that naively specify everything in the prompt. Beyond prompt optimization, we envision that effectively managing prompt underspecification requires a broader process, including proactive requirements discovery, evaluation, and monitoring.
AI LEGO: Scaffolding Cross-Functional Collaboration in Industrial Responsible AI Practices during Early Design Stages
May 15, 2025Responsible AI (RAI) efforts increasingly emphasize the importance of addressing potential harms early in the AI development lifecycle through social-technical lenses. However, in cross-functional industry teams, this work is often stalled by a persistent knowledge handoff challenge: the difficulty of transferring high-level, early-stage technical design rationales from technical experts to non-technical or user-facing roles for ethical evaluation and harm identification. Through literature review and a co-design study with 8 practitioners, we unpack how this challenge manifests -- technical design choices are rarely handed off in ways that support meaningful engagement by non-technical roles; collaborative workflows lack shared, visual structures to support mutual understanding; and non-technical practitioners are left without scaffolds for systematic harm evaluation. Existing tools like JIRA or Google Docs, while useful for product tracking, are ill-suited for supporting joint harm identification across roles, often requiring significant extra effort to align understanding. To address this, we developed AI LEGO, a web-based prototype that supports cross-functional AI practitioners in effectively facilitating knowledge handoff and identifying harmful design choices in the early design stages. Technical roles use interactive blocks to draft development plans, while non-technical roles engage with those blocks through stage-specific checklists and LLM-driven persona simulations to surface potential harms. In a study with 18 cross-functional practitioners, AI LEGO increased the volume and likelihood of harms identified compared to baseline worksheets. Participants found that its modular structure and persona prompts made harm identification more accessible, fostering clearer and more collaborative RAI practices in early design.
Gensors: Authoring Personalized Visual Sensors with Multimodal Foundation Models and Reasoning
Jan 27, 2025
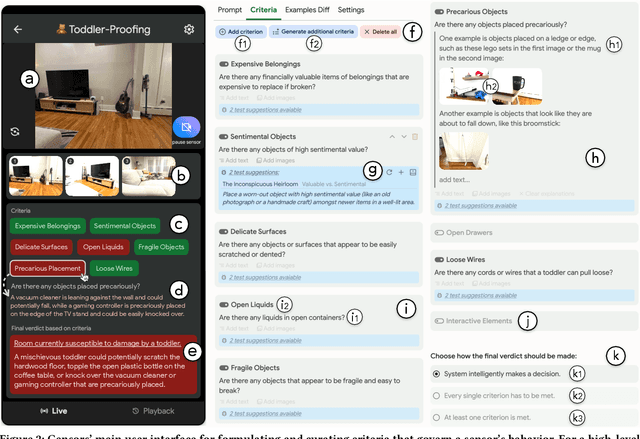
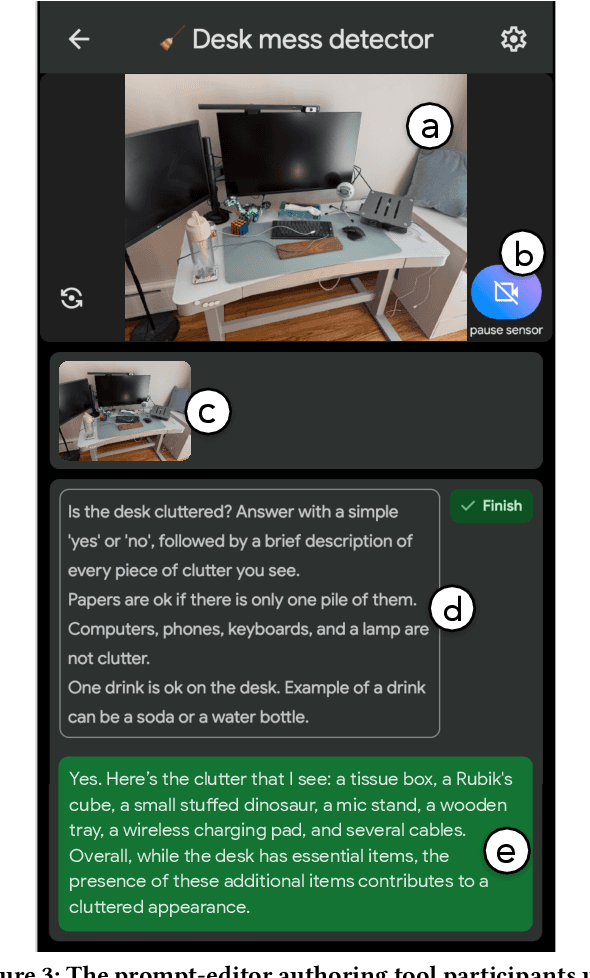
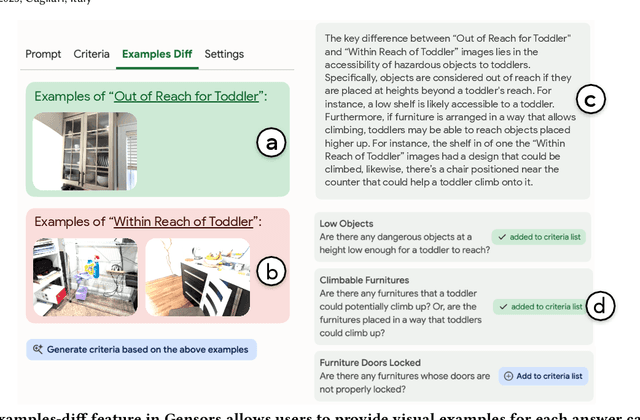
Multimodal large language models (MLLMs), with their expansive world knowledge and reasoning capabilities, present a unique opportunity for end-users to create personalized AI sensors capable of reasoning about complex situations. A user could describe a desired sensing task in natural language (e.g., "alert if my toddler is getting into mischief"), with the MLLM analyzing the camera feed and responding within seconds. In a formative study, we found that users saw substantial value in defining their own sensors, yet struggled to articulate their unique personal requirements and debug the sensors through prompting alone. To address these challenges, we developed Gensors, a system that empowers users to define customized sensors supported by the reasoning capabilities of MLLMs. Gensors 1) assists users in eliciting requirements through both automatically-generated and manually created sensor criteria, 2) facilitates debugging by allowing users to isolate and test individual criteria in parallel, 3) suggests additional criteria based on user-provided images, and 4) proposes test cases to help users "stress test" sensors on potentially unforeseen scenarios. In a user study, participants reported significantly greater sense of control, understanding, and ease of communication when defining sensors using Gensors. Beyond addressing model limitations, Gensors supported users in debugging, eliciting requirements, and expressing unique personal requirements to the sensor through criteria-based reasoning; it also helped uncover users' "blind spots" by exposing overlooked criteria and revealing unanticipated failure modes. Finally, we discuss how unique characteristics of MLLMs--such as hallucinations and inconsistent responses--can impact the sensor-creation process. These findings contribute to the design of future intelligent sensing systems that are intuitive and customizable by everyday users.
The Evolution of LLM Adoption in Industry Data Curation Practices
Dec 20, 2024



As large language models (LLMs) grow increasingly adept at processing unstructured text data, they offer new opportunities to enhance data curation workflows. This paper explores the evolution of LLM adoption among practitioners at a large technology company, evaluating the impact of LLMs in data curation tasks through participants' perceptions, integration strategies, and reported usage scenarios. Through a series of surveys, interviews, and user studies, we provide a timely snapshot of how organizations are navigating a pivotal moment in LLM evolution. In Q2 2023, we conducted a survey to assess LLM adoption in industry for development tasks (N=84), and facilitated expert interviews to assess evolving data needs (N=10) in Q3 2023. In Q2 2024, we explored practitioners' current and anticipated LLM usage through a user study involving two LLM-based prototypes (N=12). While each study addressed distinct research goals, they revealed a broader narrative about evolving LLM usage in aggregate. We discovered an emerging shift in data understanding from heuristic-first, bottom-up approaches to insights-first, top-down workflows supported by LLMs. Furthermore, to respond to a more complex data landscape, data practitioners now supplement traditional subject-expert-created 'golden datasets' with LLM-generated 'silver' datasets and rigorously validated 'super golden' datasets curated by diverse experts. This research sheds light on the transformative role of LLMs in large-scale analysis of unstructured data and highlights opportunities for further tool development.
LLM Comparator: Visual Analytics for Side-by-Side Evaluation of Large Language Models
Feb 16, 2024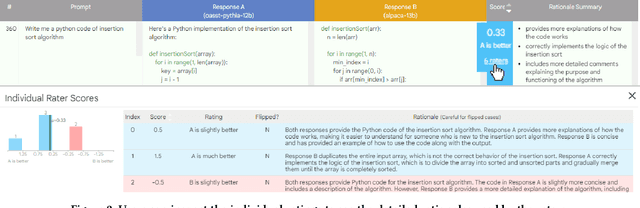

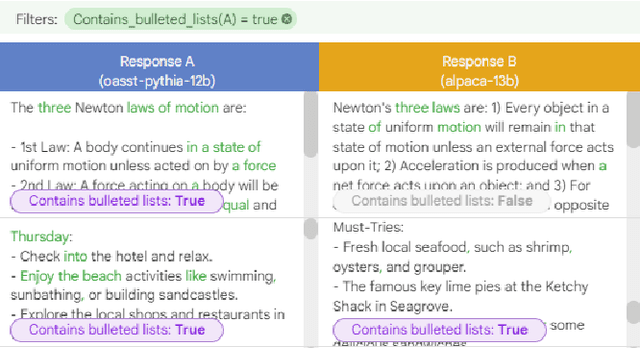
Automatic side-by-side evaluation has emerged as a promising approach to evaluating the quality of responses from large language models (LLMs). However, analyzing the results from this evaluation approach raises scalability and interpretability challenges. In this paper, we present LLM Comparator, a novel visual analytics tool for interactively analyzing results from automatic side-by-side evaluation. The tool supports interactive workflows for users to understand when and why a model performs better or worse than a baseline model, and how the responses from two models are qualitatively different. We iteratively designed and developed the tool by closely working with researchers and engineers at a large technology company. This paper details the user challenges we identified, the design and development of the tool, and an observational study with participants who regularly evaluate their models.
Selenite: Scaffolding Decision Making with Comprehensive Overviews Elicited from Large Language Models
Oct 03, 2023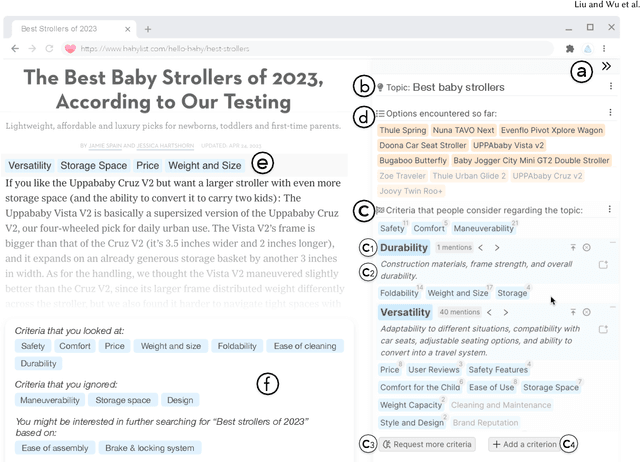



Decision-making in unfamiliar domains can be challenging, demanding considerable user effort to compare different options with respect to various criteria. Prior research and our formative study found that people would benefit from seeing an overview of the information space upfront, such as the criteria that others have previously found useful. However, existing sensemaking tools struggle with the "cold-start" problem -- it not only requires significant input from previous users to generate and share these overviews, but such overviews may also be biased and incomplete. In this work, we introduce a novel system, Selenite, which leverages LLMs as reasoning machines and knowledge retrievers to automatically produce a comprehensive overview of options and criteria to jumpstart users' sensemaking processes. Subsequently, Selenite also adapts as people use it, helping users find, read, and navigate unfamiliar information in a systematic yet personalized manner. Through three studies, we found that Selenite produced accurate and high-quality overviews reliably, significantly accelerated users' information processing, and effectively improved their overall comprehension and sensemaking experience.