 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChoose Your Agent: Tradeoffs in Adopting AI Advisors, Coaches, and Delegates in Multi-Party Negotiation
Feb 13, 2026As AI usage becomes more prevalent in social contexts, understanding agent-user interaction is critical to designing systems that improve both individual and group outcomes. We present an online behavioral experiment (N = 243) in which participants play three multi-turn bargaining games in groups of three. Each game, presented in randomized order, grants access to a single LLM assistance modality: proactive recommendations from an Advisor, reactive feedback from a Coach, or autonomous execution by a Delegate; all modalities are powered by an underlying LLM that achieves superhuman performance in an all-agent environment. On each turn, participants privately decide whether to act manually or use the AI modality available in that game. Despite preferring the Advisor modality, participants achieve the highest mean individual gains with the Delegate, demonstrating a preference-performance misalignment. Moreover, delegation generates positive externalities; even non-adopting users in access-to-delegate treatment groups benefit by receiving higher-quality offers. Mechanism analysis reveals that the Delegate agent acts as a market maker, injecting rational, Pareto-improving proposals that restructure the trading environment. Our research reveals a gap between agent capabilities and realized group welfare. While autonomous agents can exhibit super-human strategic performance, their impact on realized welfare gains can be constrained by interfaces, user perceptions, and adoption barriers. Assistance modalities should be designed as mechanisms with endogenous participation; adoption-compatible interaction rules are a prerequisite to improving human welfare with automated assistance.
To Mask or to Mirror: Human-AI Alignment in Collective Reasoning
Oct 02, 2025As large language models (LLMs) are increasingly used to model and augment collective decision-making, it is critical to examine their alignment with human social reasoning. We present an empirical framework for assessing collective alignment, in contrast to prior work on the individual level. Using the Lost at Sea social psychology task, we conduct a large-scale online experiment (N=748), randomly assigning groups to leader elections with either visible demographic attributes (e.g. name, gender) or pseudonymous aliases. We then simulate matched LLM groups conditioned on the human data, benchmarking Gemini 2.5, GPT 4.1, Claude Haiku 3.5, and Gemma 3. LLM behaviors diverge: some mirror human biases; others mask these biases and attempt to compensate for them. We empirically demonstrate that human-AI alignment in collective reasoning depends on context, cues, and model-specific inductive biases. Understanding how LLMs align with collective human behavior is critical to advancing socially-aligned AI, and demands dynamic benchmarks that capture the complexities of collective reasoning.
Understanding Economic Tradeoffs Between Human and AI Agents in Bargaining Games
Sep 11, 2025



Coordination tasks traditionally performed by humans are increasingly being delegated to autonomous agents. As this pattern progresses, it becomes critical to evaluate not only these agents' performance but also the processes through which they negotiate in dynamic, multi-agent environments. Furthermore, different agents exhibit distinct advantages: traditional statistical agents, such as Bayesian models, may excel under well-specified conditions, whereas large language models (LLMs) can generalize across contexts. In this work, we compare humans (N = 216), LLMs (GPT-4o, Gemini 1.5 Pro), and Bayesian agents in a dynamic negotiation setting that enables direct, identical-condition comparisons across populations, capturing both outcomes and behavioral dynamics. Bayesian agents extract the highest surplus through aggressive optimization, at the cost of frequent trade rejections. Humans and LLMs can achieve similar overall surplus, but through distinct behaviors: LLMs favor conservative, concessionary trades with few rejections, while humans employ more strategic, risk-taking, and fairness-oriented behaviors. Thus, we find that performance parity -- a common benchmark in agent evaluation -- can conceal fundamental differences in process and alignment, which are critical for practical deployment in real-world coordination tasks.
Gensors: Authoring Personalized Visual Sensors with Multimodal Foundation Models and Reasoning
Jan 27, 2025
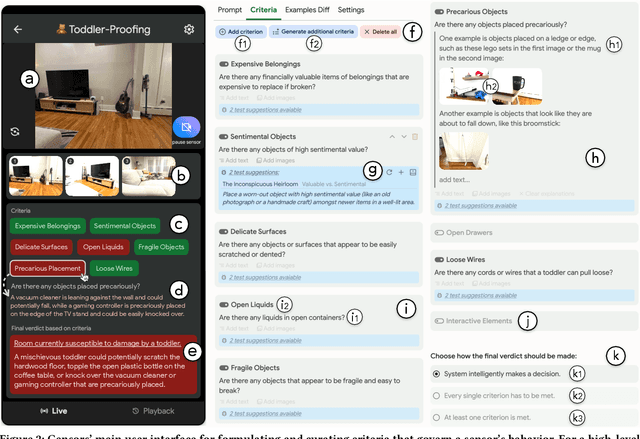
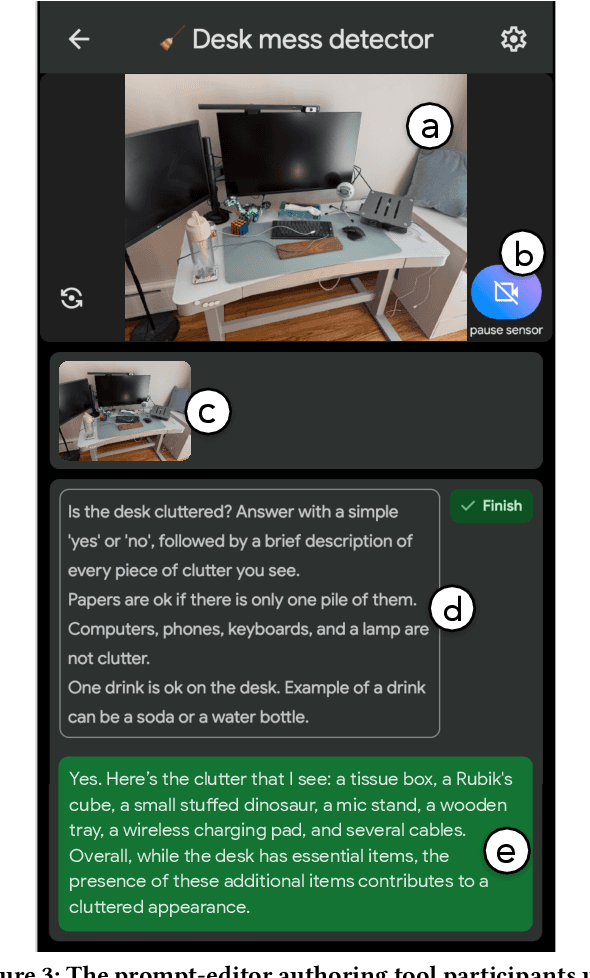
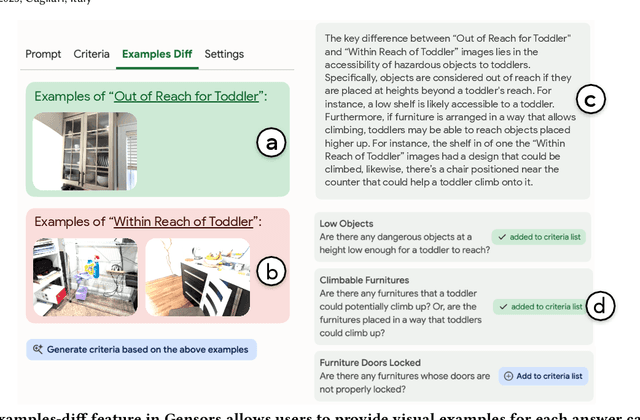
Multimodal large language models (MLLMs), with their expansive world knowledge and reasoning capabilities, present a unique opportunity for end-users to create personalized AI sensors capable of reasoning about complex situations. A user could describe a desired sensing task in natural language (e.g., "alert if my toddler is getting into mischief"), with the MLLM analyzing the camera feed and responding within seconds. In a formative study, we found that users saw substantial value in defining their own sensors, yet struggled to articulate their unique personal requirements and debug the sensors through prompting alone. To address these challenges, we developed Gensors, a system that empowers users to define customized sensors supported by the reasoning capabilities of MLLMs. Gensors 1) assists users in eliciting requirements through both automatically-generated and manually created sensor criteria, 2) facilitates debugging by allowing users to isolate and test individual criteria in parallel, 3) suggests additional criteria based on user-provided images, and 4) proposes test cases to help users "stress test" sensors on potentially unforeseen scenarios. In a user study, participants reported significantly greater sense of control, understanding, and ease of communication when defining sensors using Gensors. Beyond addressing model limitations, Gensors supported users in debugging, eliciting requirements, and expressing unique personal requirements to the sensor through criteria-based reasoning; it also helped uncover users' "blind spots" by exposing overlooked criteria and revealing unanticipated failure modes. Finally, we discuss how unique characteristics of MLLMs--such as hallucinations and inconsistent responses--can impact the sensor-creation process. These findings contribute to the design of future intelligent sensing systems that are intuitive and customizable by everyday users.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022



Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.