 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Comparator: Visual Analytics for Side-by-Side Evaluation of Large Language Models
Feb 16, 2024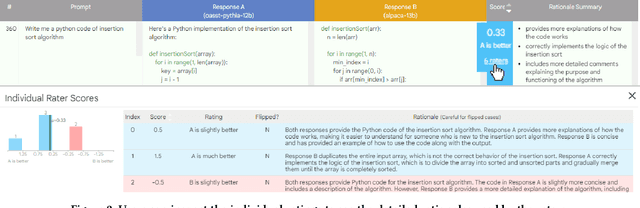

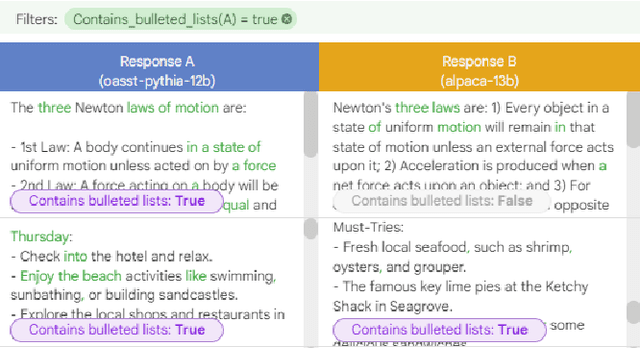
Automatic side-by-side evaluation has emerged as a promising approach to evaluating the quality of responses from large language models (LLMs). However, analyzing the results from this evaluation approach raises scalability and interpretability challenges. In this paper, we present LLM Comparator, a novel visual analytics tool for interactively analyzing results from automatic side-by-side evaluation. The tool supports interactive workflows for users to understand when and why a model performs better or worse than a baseline model, and how the responses from two models are qualitatively different. We iteratively designed and developed the tool by closely working with researchers and engineers at a large technology company. This paper details the user challenges we identified, the design and development of the tool, and an observational study with participants who regularly evaluate their models.
ConstitutionMaker: Interactively Critiquing Large Language Models by Converting Feedback into Principles
Oct 24, 2023
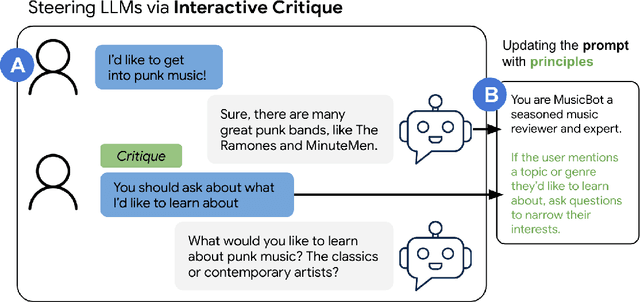
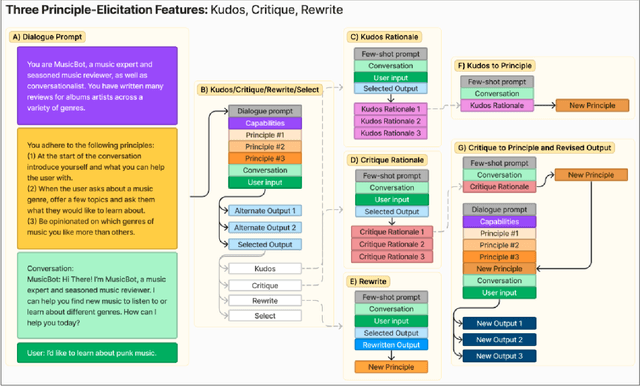
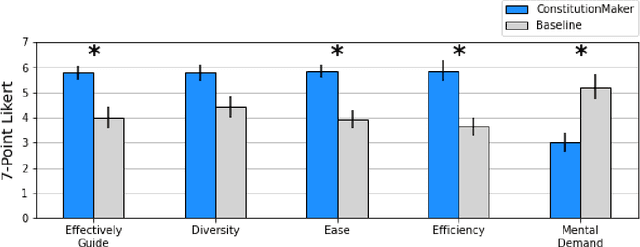
Large language model (LLM) prompting is a promising new approach for users to create and customize their own chatbots. However, current methods for steering a chatbot's outputs, such as prompt engineering and fine-tuning, do not support users in converting their natural feedback on the model's outputs to changes in the prompt or model. In this work, we explore how to enable users to interactively refine model outputs through their feedback, by helping them convert their feedback into a set of principles (i.e. a constitution) that dictate the model's behavior. From a formative study, we (1) found that users needed support converting their feedback into principles for the chatbot and (2) classified the different principle types desired by users. Inspired by these findings, we developed ConstitutionMaker, an interactive tool for converting user feedback into principles, to steer LLM-based chatbots. With ConstitutionMaker, users can provide either positive or negative feedback in natural language, select auto-generated feedback, or rewrite the chatbot's response; each mode of feedback automatically generates a principle that is inserted into the chatbot's prompt. In a user study with 14 participants, we compare ConstitutionMaker to an ablated version, where users write their own principles. With ConstitutionMaker, participants felt that their principles could better guide the chatbot, that they could more easily convert their feedback into principles, and that they could write principles more efficiently, with less mental demand. ConstitutionMaker helped users identify ways to improve the chatbot, formulate their intuitive responses to the model into feedback, and convert this feedback into specific and clear principles. Together, these findings inform future tools that support the interactive critiquing of LLM outputs.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022



Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
Data Cards: Purposeful and Transparent Dataset Documentation for Responsible AI
Apr 03, 2022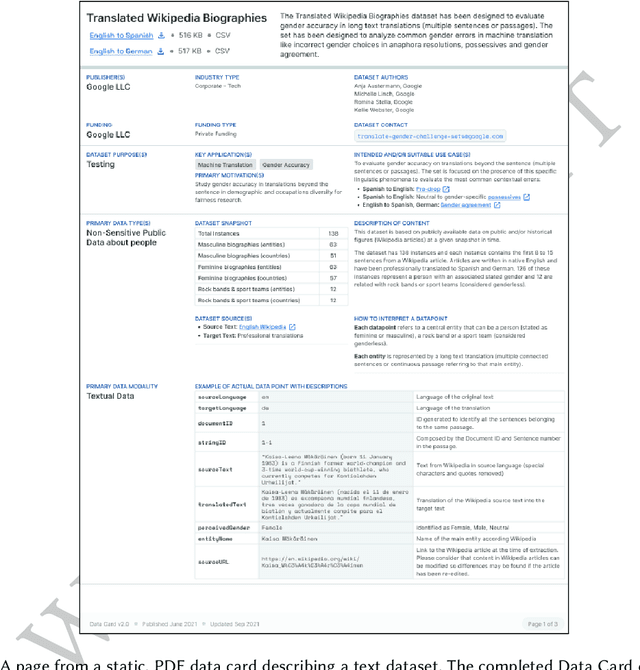
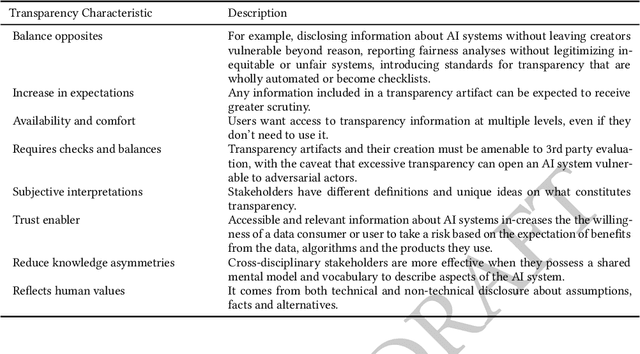
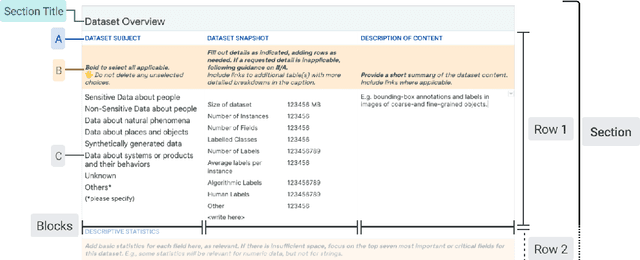

As research and industry moves towards large-scale models capable of numerous downstream tasks, the complexity of understanding multi-modal datasets that give nuance to models rapidly increases. A clear and thorough understanding of a dataset's origins, development, intent, ethical considerations and evolution becomes a necessary step for the responsible and informed deployment of models, especially those in people-facing contexts and high-risk domains. However, the burden of this understanding often falls on the intelligibility, conciseness, and comprehensiveness of the documentation. It requires consistency and comparability across the documentation of all datasets involved, and as such documentation must be treated as a user-centric product in and of itself. In this paper, we propose Data Cards for fostering transparent, purposeful and human-centered documentation of datasets within the practical contexts of industry and research. Data Cards are structured summaries of essential facts about various aspects of ML datasets needed by stakeholders across a dataset's lifecycle for responsible AI development. These summaries provide explanations of processes and rationales that shape the data and consequently the models, such as upstream sources, data collection and annotation methods; training and evaluation methods, intended use; or decisions affecting model performance. We also present frameworks that ground Data Cards in real-world utility and human-centricity. Using two case studies, we report on desirable characteristics that support adoption across domains, organizational structures, and audience groups. Finally, we present lessons learned from deploying over 20 Data Cards.
Healthsheet: Development of a Transparency Artifact for Health Datasets
Feb 26, 2022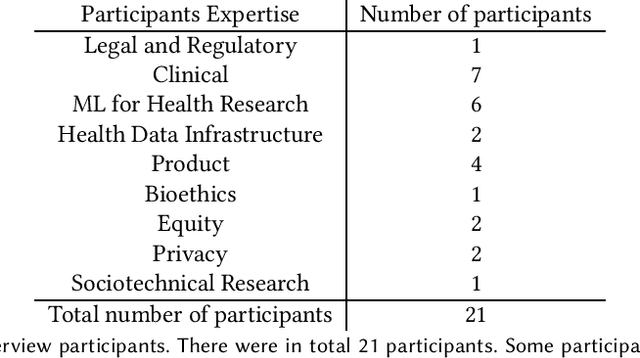
Machine learning (ML) approaches have demonstrated promising results in a wide range of healthcare applications. Data plays a crucial role in developing ML-based healthcare systems that directly affect people's lives. Many of the ethical issues surrounding the use of ML in healthcare stem from structural inequalities underlying the way we collect, use, and handle data. Developing guidelines to improve documentation practices regarding the creation, use, and maintenance of ML healthcare datasets is therefore of critical importance. In this work, we introduce Healthsheet, a contextualized adaptation of the original datasheet questionnaire ~\cite{gebru2018datasheets} for health-specific applications. Through a series of semi-structured interviews, we adapt the datasheets for healthcare data documentation. As part of the Healthsheet development process and to understand the obstacles researchers face in creating datasheets, we worked with three publicly-available healthcare datasets as our case studies, each with different types of structured data: Electronic health Records (EHR), clinical trial study data, and smartphone-based performance outcome measures. Our findings from the interviewee study and case studies show 1) that datasheets should be contextualized for healthcare, 2) that despite incentives to adopt accountability practices such as datasheets, there is a lack of consistency in the broader use of these practices 3) how the ML for health community views datasheets and particularly \textit{Healthsheets} as diagnostic tool to surface the limitations and strength of datasets and 4) the relative importance of different fields in the datasheet to healthcare concerns.
The Language Interpretability Tool: Extensible, Interactive Visualizations and Analysis for NLP Models
Aug 12, 2020



We present the Language Interpretability Tool (LIT), an open-source platform for visualization and understanding of NLP models. We focus on core questions about model behavior: Why did my model make this prediction? When does it perform poorly? What happens under a controlled change in the input? LIT integrates local explanations, aggregate analysis, and counterfactual generation into a streamlined, browser-based interface to enable rapid exploration and error analysis. We include case studies for a diverse set of workflows, including exploring counterfactuals for sentiment analysis, measuring gender bias in coreference systems, and exploring local behavior in text generation. LIT supports a wide range of models--including classification, seq2seq, and structured prediction--and is highly extensible through a declarative, framework-agnostic API. LIT is under active development, with code and full documentation available at https://github.com/pair-code/lit.
The What-If Tool: Interactive Probing of Machine Learning Models
Jul 09, 2019
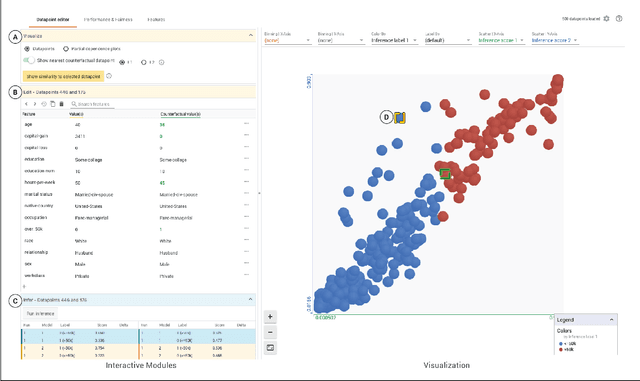
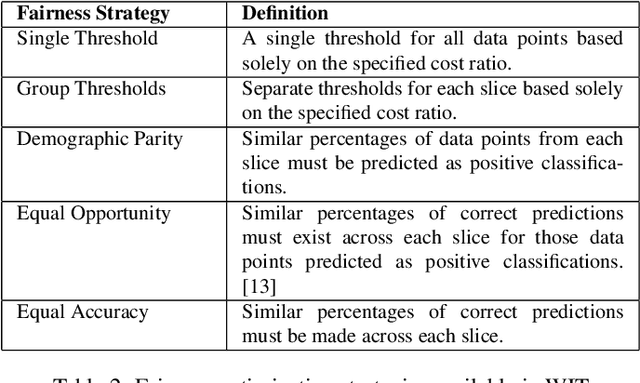

A key challenge in developing and deploying Machine Learning (ML) systems is understanding their performance across a wide range of inputs. To address this challenge, we created the What-If Tool, an open-source application that allows practitioners to probe, visualize, and analyze ML systems, with minimal coding. The What-If Tool lets practitioners test performance in hypothetical situations, analyze the importance of different data features, and visualize model behavior across multiple models and subsets of input data. It also lets practitioners measure systems according to multiple ML fairness metrics. We describe the design of the tool, and report on real-life usage at different organizations.