 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Creative Writing with an AI-Powered Writing Assistant: Perspectives from Professional Writers
Nov 09, 2022Recent developments in natural language generation (NLG) using neural language models have brought us closer than ever to the goal of building AI-powered creative writing tools. However, most prior work on human-AI collaboration in the creative writing domain has evaluated new systems with amateur writers, typically in contrived user studies of limited scope. In this work, we commissioned 13 professional, published writers from a diverse set of creative writing backgrounds to craft stories using Wordcraft, a text editor with built-in AI-powered writing assistance tools. Using interviews and participant journals, we discuss the potential of NLG to have significant impact in the creative writing domain--especially with respect to brainstorming, generation of story details, world-building, and research assistance. Experienced writers, more so than amateurs, typically have well-developed systems and methodologies for writing, as well as distinctive voices and target audiences. Our work highlights the challenges in building for these writers; NLG technologies struggle to preserve style and authorial voice, and they lack deep understanding of story contents. In order for AI-powered writing assistants to realize their full potential, it is essential that they take into account the diverse goals and expertise of human writers.
The Case for a Single Model that can Both Generate Continuations and Fill in the Blank
Jun 09, 2022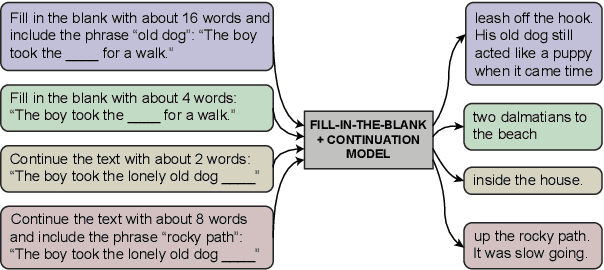

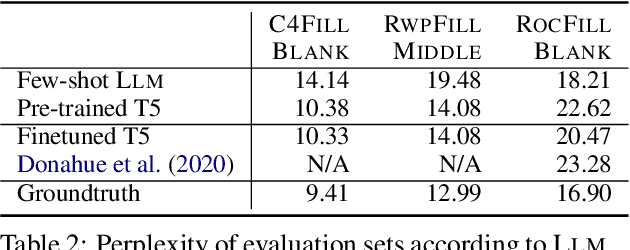
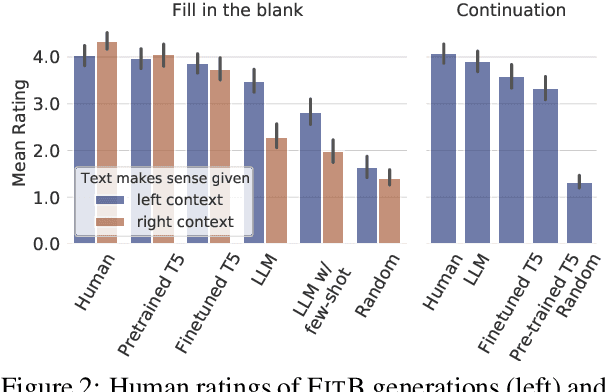
The task of inserting text into a specified position in a passage, known as fill in the blank (FitB), is useful for a variety of applications where writers interact with a natural language generation (NLG) system to craft text. While previous work has tackled this problem with models trained specifically to do the fill-in-the-blank task, a more useful model is one that can effectively perform _both_ FitB and continuation. In this work, we evaluate the feasibility of using a single model to do both tasks. We show that models pre-trained with a FitB-style objective are capable of both tasks, while models pre-trained for continuation are not. Finally, we show how FitB models can be easily finetuned to allow for fine-grained control over the length and word choice of the generation.
SynthBio: A Case Study in Human-AI Collaborative Curation of Text Datasets
Nov 11, 2021
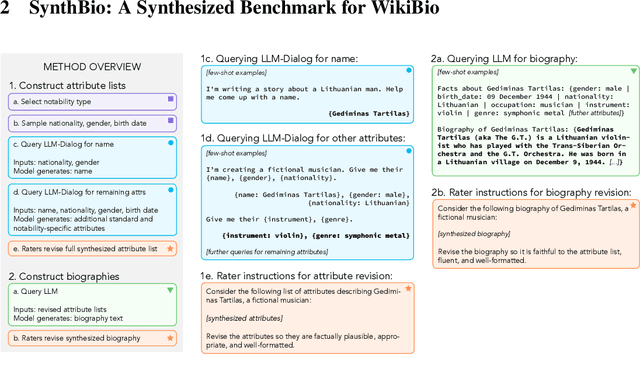

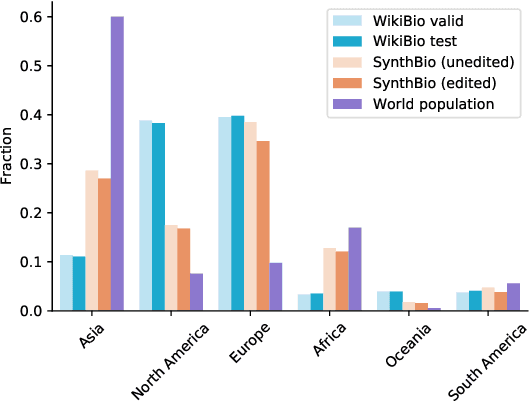
NLP researchers need more, higher-quality text datasets. Human-labeled datasets are expensive to collect, while datasets collected via automatic retrieval from the web such as WikiBio are noisy and can include undesired biases. Moreover, data sourced from the web is often included in datasets used to pretrain models, leading to inadvertent cross-contamination of training and test sets. In this work we introduce a novel method for efficient dataset curation: we use a large language model to provide seed generations to human raters, thereby changing dataset authoring from a writing task to an editing task. We use our method to curate SynthBio - a new evaluation set for WikiBio - composed of structured attribute lists describing fictional individuals, mapped to natural language biographies. We show that our dataset of fictional biographies is less noisy than WikiBio, and also more balanced with respect to gender and nationality.
A Recipe For Arbitrary Text Style Transfer with Large Language Models
Sep 16, 2021

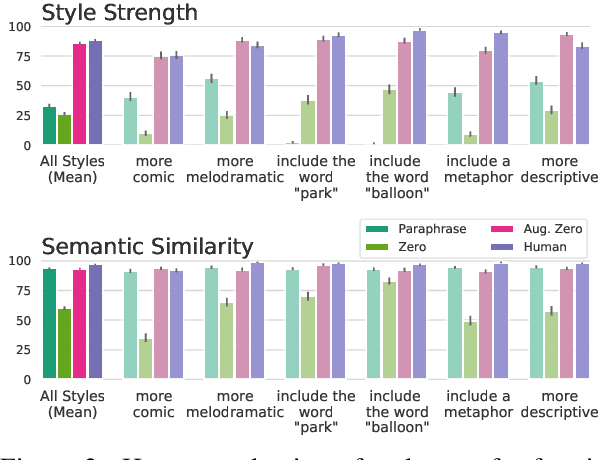
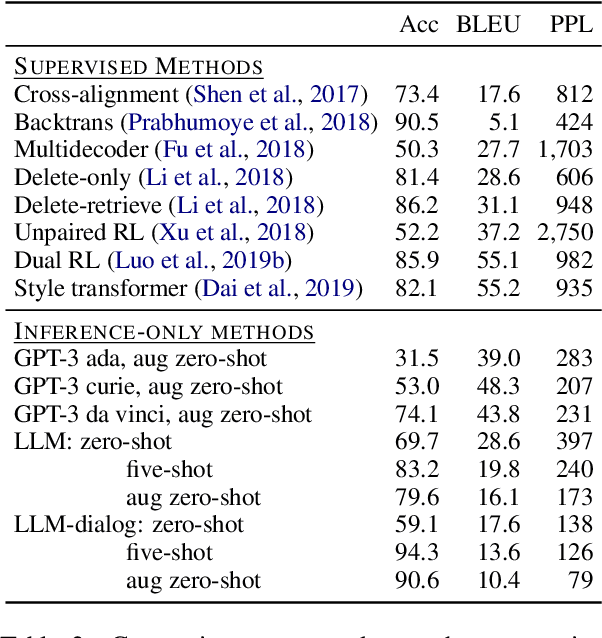
In this paper, we leverage large language models (LMs) to perform zero-shot text style transfer. We present a prompting method that we call augmented zero-shot learning, which frames style transfer as a sentence rewriting task and requires only a natural language instruction, without model fine-tuning or exemplars in the target style. Augmented zero-shot learning is simple and demonstrates promising results not just on standard style transfer tasks such as sentiment, but also on arbitrary transformations such as "make this melodramatic" or "insert a metaphor."
Wordcraft: a Human-AI Collaborative Editor for Story Writing
Jul 15, 2021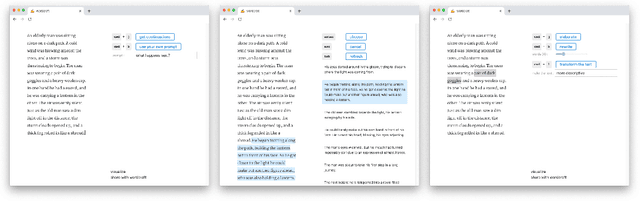


As neural language models grow in effectiveness, they are increasingly being applied in real-world settings. However these applications tend to be limited in the modes of interaction they support. In this extended abstract, we propose Wordcraft, an AI-assisted editor for story writing in which a writer and a dialog system collaborate to write a story. Our novel interface uses few-shot learning and the natural affordances of conversation to support a variety of interactions. Our editor provides a sandbox for writers to probe the boundaries of transformer-based language models and paves the way for future human-in-the-loop training pipelines and novel evaluation methods.
An Interpretability Illusion for BERT
Apr 14, 2021


We describe an "interpretability illusion" that arises when analyzing the BERT model. Activations of individual neurons in the network may spuriously appear to encode a single, simple concept, when in fact they are encoding something far more complex. The same effect holds for linear combinations of activations. We trace the source of this illusion to geometric properties of BERT's embedding space as well as the fact that common text corpora represent only narrow slices of possible English sentences. We provide a taxonomy of model-learned concepts and discuss methodological implications for interpretability research, especially the importance of testing hypotheses on multiple data sets.
The Language Interpretability Tool: Extensible, Interactive Visualizations and Analysis for NLP Models
Aug 12, 2020



We present the Language Interpretability Tool (LIT), an open-source platform for visualization and understanding of NLP models. We focus on core questions about model behavior: Why did my model make this prediction? When does it perform poorly? What happens under a controlled change in the input? LIT integrates local explanations, aggregate analysis, and counterfactual generation into a streamlined, browser-based interface to enable rapid exploration and error analysis. We include case studies for a diverse set of workflows, including exploring counterfactuals for sentiment analysis, measuring gender bias in coreference systems, and exploring local behavior in text generation. LIT supports a wide range of models--including classification, seq2seq, and structured prediction--and is highly extensible through a declarative, framework-agnostic API. LIT is under active development, with code and full documentation available at https://github.com/pair-code/lit.
Visualizing and Measuring the Geometry of BERT
Jun 06, 2019
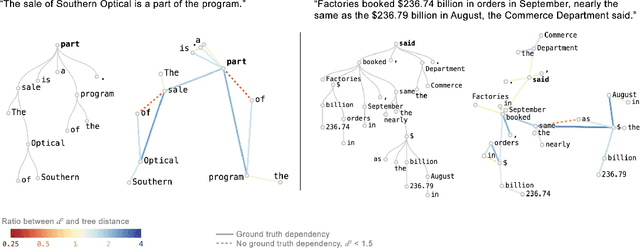
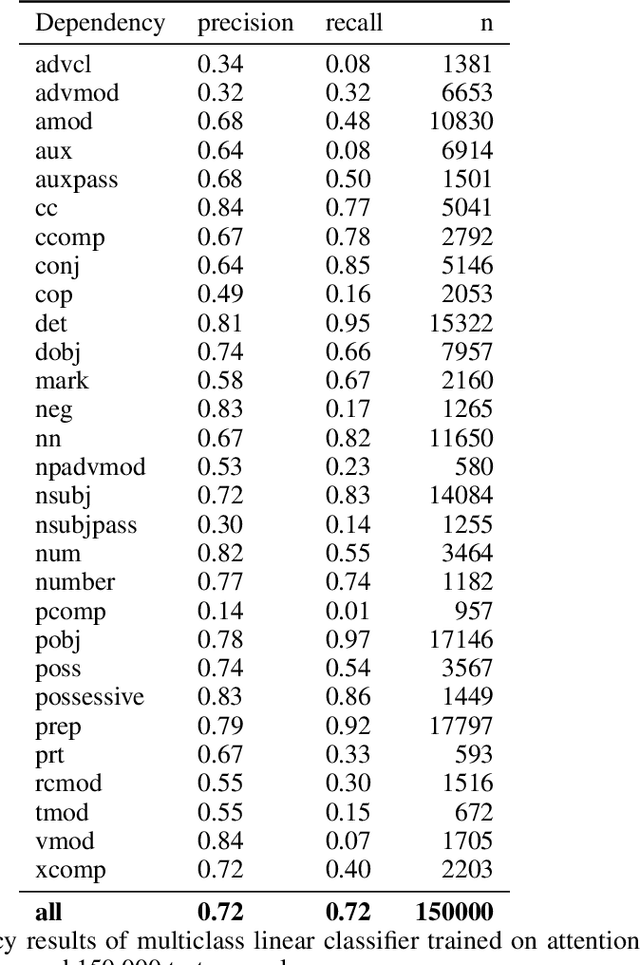
Transformer architectures show significant promise for natural language processing. Given that a single pretrained model can be fine-tuned to perform well on many different tasks, these networks appear to extract generally useful linguistic features. A natural question is how such networks represent this information internally. This paper describes qualitative and quantitative investigations of one particularly effective model, BERT. At a high level, linguistic features seem to be represented in separate semantic and syntactic subspaces. We find evidence of a fine-grained geometric representation of word senses. We also present empirical descriptions of syntactic representations in both attention matrices and individual word embeddings, as well as a mathematical argument to explain the geometry of these representations.