Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interpretability Illusion for BERT
Paper and Code
Apr 14, 2021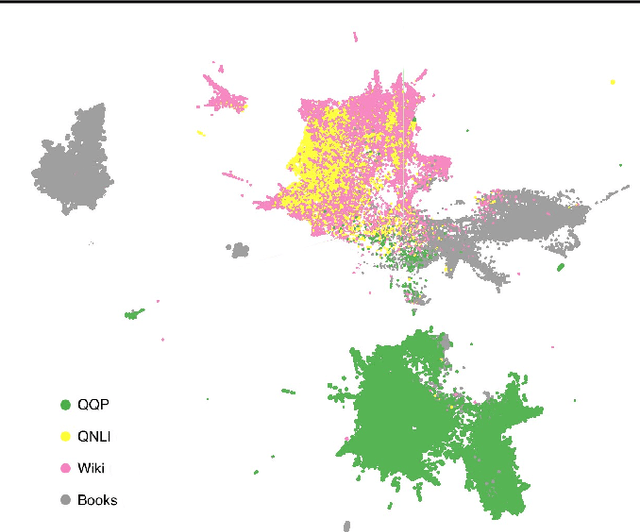


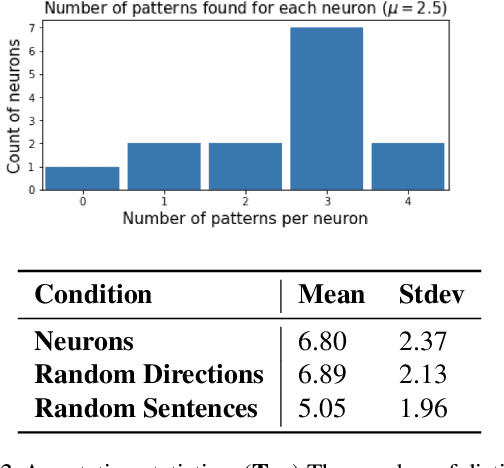
We describe an "interpretability illusion" that arises when analyzing the BERT model. Activations of individual neurons in the network may spuriously appear to encode a single, simple concept, when in fact they are encoding something far more complex. The same effect holds for linear combinations of activations. We trace the source of this illusion to geometric properties of BERT's embedding space as well as the fact that common text corpora represent only narrow slices of possible English sentences. We provide a taxonomy of model-learned concepts and discuss methodological implications for interpretability research, especially the importance of testing hypotheses on multiple data sets.
View paper on