 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Influence and Fact Tracing for Large Language Model Pretraining
Oct 22, 2024Training data attribution (TDA) methods aim to attribute model outputs back to specific training examples, and the application of these methods to large language model (LLM) outputs could significantly advance model transparency and data curation. However, it has been challenging to date to apply these methods to the full scale of LLM pretraining. In this paper, we refine existing gradient-based methods to work effectively at scale, allowing us to retrieve influential examples for an 8B-parameter language model from a pretraining corpus of over 160B tokens with no need for subsampling or pre-filtering. Our method combines several techniques, including optimizer state correction, a task-specific Hessian approximation, and normalized encodings, which we find to be critical for performance at scale. In quantitative evaluations on a fact tracing task, our method performs best at identifying examples that influence model predictions, but classical, model-agnostic retrieval methods such as BM25 still perform better at finding passages which explicitly contain relevant facts. These results demonstrate a misalignment between factual attribution and causal influence. With increasing model size and training tokens, we find that influence more closely aligns with attribution. Finally, we examine different types of examples identified as influential by our method, finding that while many directly entail a particular fact, others support the same output by reinforcing priors on relation types, common entities, and names.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Self-Influence Guided Data Reweighting for Language Model Pre-training
Nov 02, 2023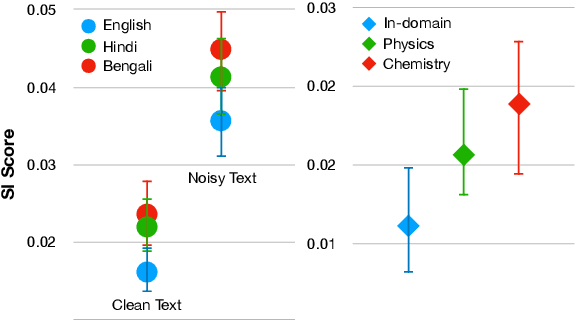
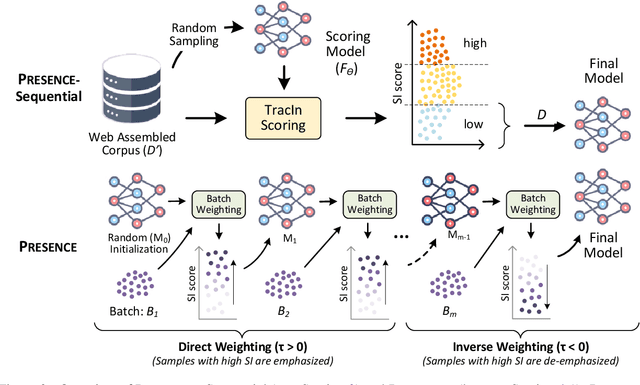
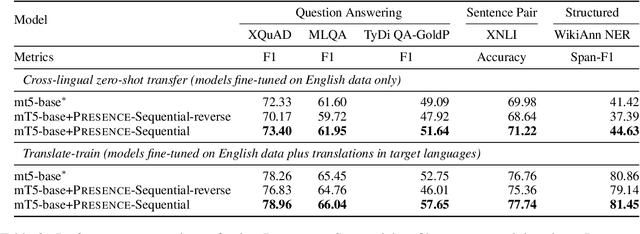
Language Models (LMs) pre-trained with self-supervision on large text corpora have become the default starting point for developing models for various NLP tasks. Once the pre-training corpus has been assembled, all data samples in the corpus are treated with equal importance during LM pre-training. However, due to varying levels of relevance and quality of data, equal importance to all the data samples may not be the optimal choice. While data reweighting has been explored in the context of task-specific supervised learning and LM fine-tuning, model-driven reweighting for pre-training data has not been explored. We fill this important gap and propose PRESENCE, a method for jointly reweighting samples by leveraging self-influence (SI) scores as an indicator of sample importance and pre-training. PRESENCE promotes novelty and stability for model pre-training. Through extensive analysis spanning multiple model sizes, datasets, and tasks, we present PRESENCE as an important first step in the research direction of sample reweighting for pre-training language models.
Simfluence: Modeling the Influence of Individual Training Examples by Simulating Training Runs
Mar 14, 2023Training data attribution (TDA) methods offer to trace a model's prediction on any given example back to specific influential training examples. Existing approaches do so by assigning a scalar influence score to each training example, under a simplifying assumption that influence is additive. But in reality, we observe that training examples interact in highly non-additive ways due to factors such as inter-example redundancy, training order, and curriculum learning effects. To study such interactions, we propose Simfluence, a new paradigm for TDA where the goal is not to produce a single influence score per example, but instead a training run simulator: the user asks, ``If my model had trained on example $z_1$, then $z_2$, ..., then $z_n$, how would it behave on $z_{test}$?''; the simulator should then output a simulated training run, which is a time series predicting the loss on $z_{test}$ at every step of the simulated run. This enables users to answer counterfactual questions about what their model would have learned under different training curricula, and to directly see where in training that learning would occur. We present a simulator, Simfluence-Linear, that captures non-additive interactions and is often able to predict the spiky trajectory of individual example losses with surprising fidelity. Furthermore, we show that existing TDA methods such as TracIn and influence functions can be viewed as special cases of Simfluence-Linear. This enables us to directly compare methods in terms of their simulation accuracy, subsuming several prior TDA approaches to evaluation. In experiments on large language model (LLM) fine-tuning, we show that our method predicts loss trajectories with much higher accuracy than existing TDA methods (doubling Spearman's correlation and reducing mean-squared error by 75%) across several tasks, models, and training methods.
Towards Agile Text Classifiers for Everyone
Feb 13, 2023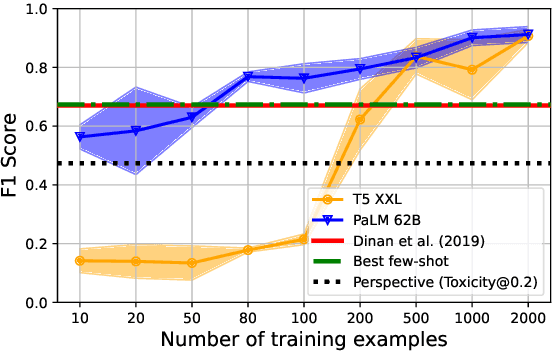
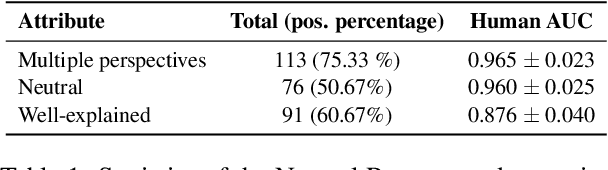
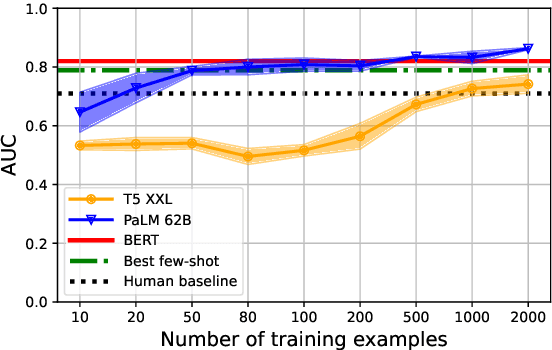
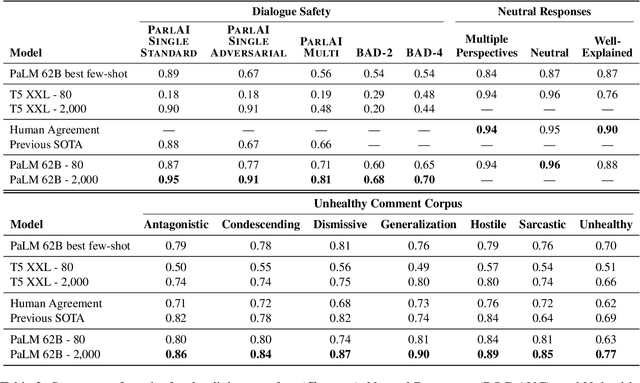
Text-based safety classifiers are widely used for content moderation and increasingly to tune generative language model behavior - a topic of growing concern for the safety of digital assistants and chatbots. However, different policies require different classifiers, and safety policies themselves improve from iteration and adaptation. This paper introduces and evaluates methods for agile text classification, whereby classifiers are trained using small, targeted datasets that can be quickly developed for a particular policy. Experimenting with 7 datasets from three safety-related domains, comprising 15 annotation schemes, led to our key finding: prompt-tuning large language models, like PaLM 62B, with a labeled dataset of as few as 80 examples can achieve state-of-the-art performance. We argue that this enables a paradigm shift for text classification, especially for models supporting safer online discourse. Instead of collecting millions of examples to attempt to create universal safety classifiers over months or years, classifiers could be tuned using small datasets, created by individuals or small organizations, tailored for specific use cases, and iterated on and adapted in the time-span of a day.
Gradient-Based Automated Iterative Recovery for Parameter-Efficient Tuning
Feb 13, 2023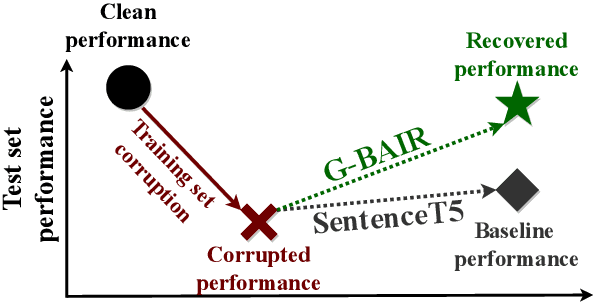

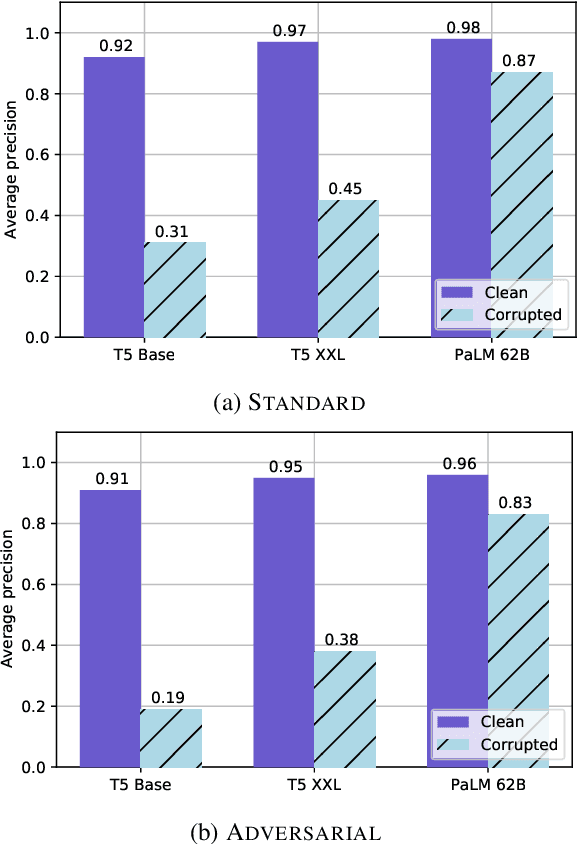
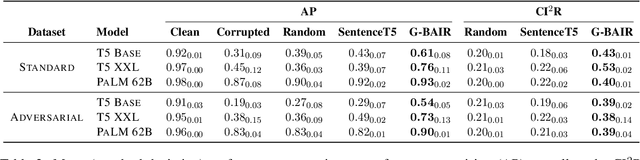
Pretrained large language models (LLMs) are able to solve a wide variety of tasks through transfer learning. Various explainability methods have been developed to investigate their decision making process. TracIn (Pruthi et al., 2020) is one such gradient-based method which explains model inferences based on the influence of training examples. In this paper, we explore the use of TracIn to improve model performance in the parameter-efficient tuning (PET) setting. We develop conversational safety classifiers via the prompt-tuning PET method and show how the unique characteristics of the PET regime enable TracIn to identify the cause for certain misclassifications by LLMs. We develop a new methodology for using gradient-based explainability techniques to improve model performance, G-BAIR: gradient-based automated iterative recovery. We show that G-BAIR can recover LLM performance on benchmarks after manually corrupting training labels. This suggests that influence methods like TracIn can be used to automatically perform data cleaning, and introduces the potential for interactive debugging and relabeling for PET-based transfer learning methods.
Tracing Knowledge in Language Models Back to the Training Data
May 24, 2022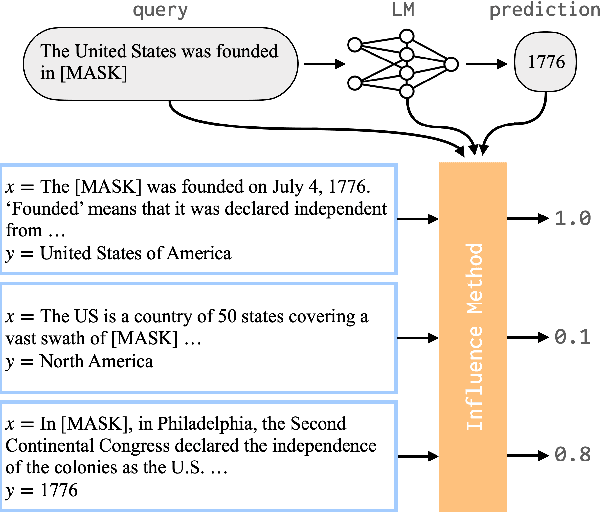
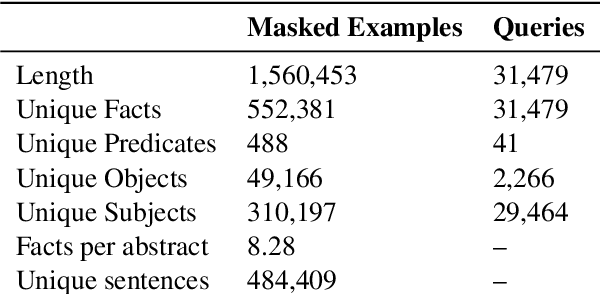
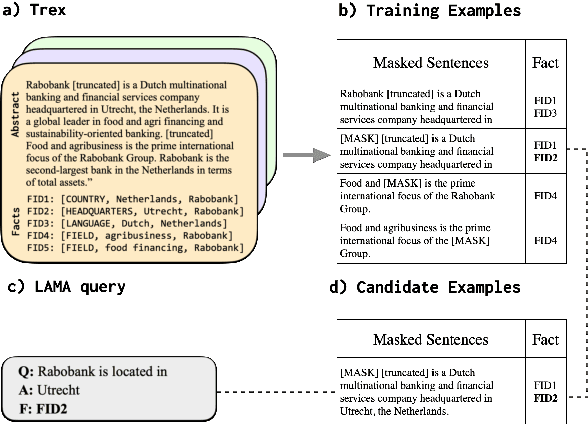
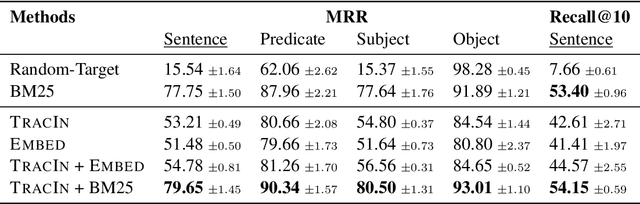
Neural language models (LMs) have been shown to memorize a great deal of factual knowledge. But when an LM generates an assertion, it is often difficult to determine where it learned this information and whether it is true. In this paper, we introduce a new benchmark for fact tracing: tracing language models' assertions back to the training examples that provided evidence for those predictions. Prior work has suggested that dataset-level influence methods might offer an effective framework for tracing predictions back to training data. However, such methods have not been evaluated for fact tracing, and researchers primarily have studied them through qualitative analysis or as a data cleaning technique for classification/regression tasks. We present the first experiments that evaluate influence methods for fact tracing, using well-understood information retrieval (IR) metrics. We compare two popular families of influence methods -- gradient-based and embedding-based -- and show that neither can fact-trace reliably; indeed, both methods fail to outperform an IR baseline (BM25) that does not even access the LM. We explore why this occurs (e.g., gradient saturation) and demonstrate that existing influence methods must be improved significantly before they can reliably attribute factual predictions in LMs.
IMACS: Image Model Attribution Comparison Summaries
Jan 26, 2022



Developing a suitable Deep Neural Network (DNN) often requires significant iteration, where different model versions are evaluated and compared. While metrics such as accuracy are a powerful means to succinctly describe a model's performance across a dataset or to directly compare model versions, practitioners often wish to gain a deeper understanding of the factors that influence a model's predictions. Interpretability techniques such as gradient-based methods and local approximations can be used to examine small sets of inputs in fine detail, but it can be hard to determine if results from small sets generalize across a dataset. We introduce IMACS, a method that combines gradient-based model attributions with aggregation and visualization techniques to summarize differences in attributions between two DNN image models. More specifically, IMACS extracts salient input features from an evaluation dataset, clusters them based on similarity, then visualizes differences in model attributions for similar input features. In this work, we introduce a framework for aggregating, summarizing, and comparing the attribution information for two models across a dataset; present visualizations that highlight differences between 2 image classification models; and show how our technique can uncover behavioral differences caused by domain shift between two models trained on satellite images.
Guided Integrated Gradients: An Adaptive Path Method for Removing Noise
Jun 17, 2021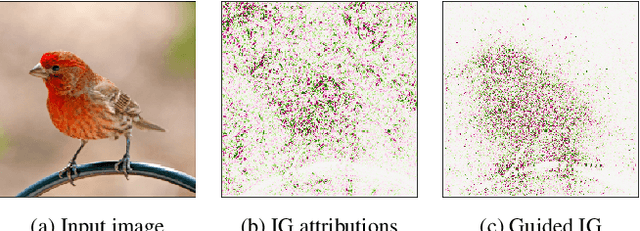
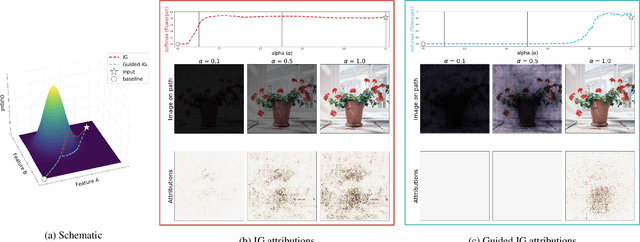
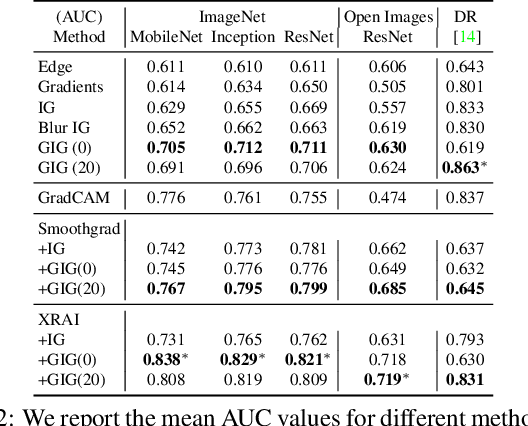
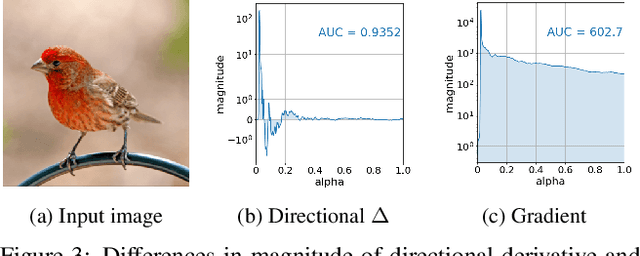
Integrated Gradients (IG) is a commonly used feature attribution method for deep neural networks. While IG has many desirable properties, the method often produces spurious/noisy pixel attributions in regions that are not related to the predicted class when applied to visual models. While this has been previously noted, most existing solutions are aimed at addressing the symptoms by explicitly reducing the noise in the resulting attributions. In this work, we show that one of the causes of the problem is the accumulation of noise along the IG path. To minimize the effect of this source of noise, we propose adapting the attribution path itself -- conditioning the path not just on the image but also on the model being explained. We introduce Adaptive Path Methods (APMs) as a generalization of path methods, and Guided IG as a specific instance of an APM. Empirically, Guided IG creates saliency maps better aligned with the model's prediction and the input image that is being explained. We show through qualitative and quantitative experiments that Guided IG outperforms other, related methods in nearly every experiment.
* 13 pages, 11 figures, for implementation sources see https://github.com/PAIR-code/saliency