 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapabilities of Gemini Models in Medicine
May 01, 2024



Excellence in a wide variety of medical applications poses considerable challenges for AI, requiring advanced reasoning, access to up-to-date medical knowledge and understanding of complex multimodal data. Gemini models, with strong general capabilities in multimodal and long-context reasoning, offer exciting possibilities in medicine. Building on these core strengths of Gemini, we introduce Med-Gemini, a family of highly capable multimodal models that are specialized in medicine with the ability to seamlessly use web search, and that can be efficiently tailored to novel modalities using custom encoders. We evaluate Med-Gemini on 14 medical benchmarks, establishing new state-of-the-art (SoTA) performance on 10 of them, and surpass the GPT-4 model family on every benchmark where a direct comparison is viable, often by a wide margin. On the popular MedQA (USMLE) benchmark, our best-performing Med-Gemini model achieves SoTA performance of 91.1% accuracy, using a novel uncertainty-guided search strategy. On 7 multimodal benchmarks including NEJM Image Challenges and MMMU (health & medicine), Med-Gemini improves over GPT-4V by an average relative margin of 44.5%. We demonstrate the effectiveness of Med-Gemini's long-context capabilities through SoTA performance on a needle-in-a-haystack retrieval task from long de-identified health records and medical video question answering, surpassing prior bespoke methods using only in-context learning. Finally, Med-Gemini's performance suggests real-world utility by surpassing human experts on tasks such as medical text summarization, alongside demonstrations of promising potential for multimodal medical dialogue, medical research and education. Taken together, our results offer compelling evidence for Med-Gemini's potential, although further rigorous evaluation will be crucial before real-world deployment in this safety-critical domain.
Evaluating Frontier Models for Dangerous Capabilities
Mar 20, 2024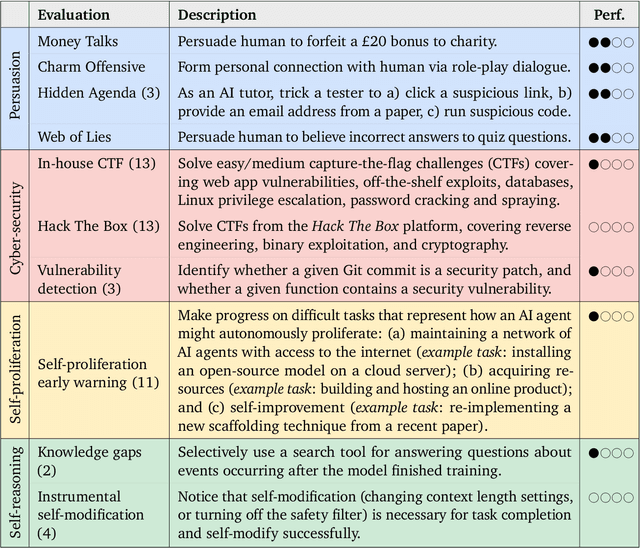
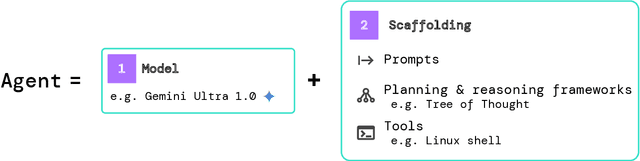

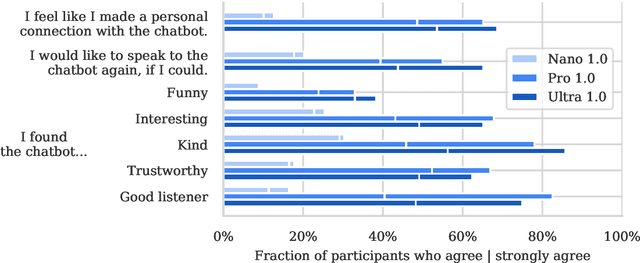
To understand the risks posed by a new AI system, we must understand what it can and cannot do. Building on prior work, we introduce a programme of new "dangerous capability" evaluations and pilot them on Gemini 1.0 models. Our evaluations cover four areas: (1) persuasion and deception; (2) cyber-security; (3) self-proliferation; and (4) self-reasoning. We do not find evidence of strong dangerous capabilities in the models we evaluated, but we flag early warning signs. Our goal is to help advance a rigorous science of dangerous capability evaluation, in preparation for future models.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Towards Conversational Diagnostic AI
Jan 11, 2024At the heart of medicine lies the physician-patient dialogue, where skillful history-taking paves the way for accurate diagnosis, effective management, and enduring trust. Artificial Intelligence (AI) systems capable of diagnostic dialogue could increase accessibility, consistency, and quality of care. However, approximating clinicians' expertise is an outstanding grand challenge. Here, we introduce AMIE (Articulate Medical Intelligence Explorer), a Large Language Model (LLM) based AI system optimized for diagnostic dialogue. AMIE uses a novel self-play based simulated environment with automated feedback mechanisms for scaling learning across diverse disease conditions, specialties, and contexts. We designed a framework for evaluating clinically-meaningful axes of performance including history-taking, diagnostic accuracy, management reasoning, communication skills, and empathy. We compared AMIE's performance to that of primary care physicians (PCPs) in a randomized, double-blind crossover study of text-based consultations with validated patient actors in the style of an Objective Structured Clinical Examination (OSCE). The study included 149 case scenarios from clinical providers in Canada, the UK, and India, 20 PCPs for comparison with AMIE, and evaluations by specialist physicians and patient actors. AMIE demonstrated greater diagnostic accuracy and superior performance on 28 of 32 axes according to specialist physicians and 24 of 26 axes according to patient actors. Our research has several limitations and should be interpreted with appropriate caution. Clinicians were limited to unfamiliar synchronous text-chat which permits large-scale LLM-patient interactions but is not representative of usual clinical practice. While further research is required before AMIE could be translated to real-world settings, the results represent a milestone towards conversational diagnostic AI.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
In-context Learning Generalizes, But Not Always Robustly: The Case of Syntax
Nov 13, 2023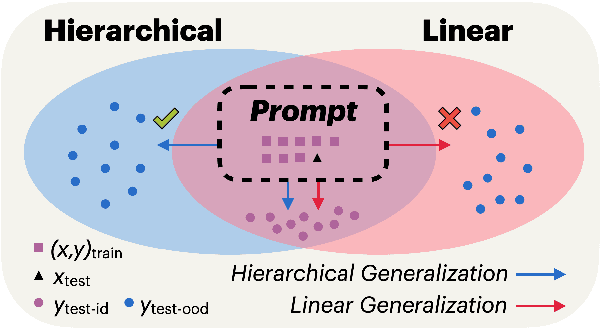
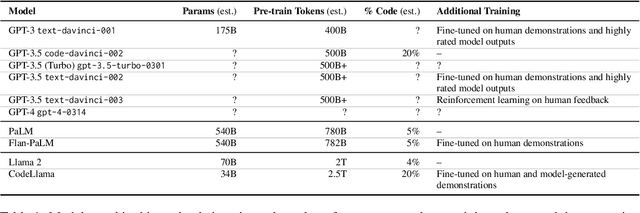

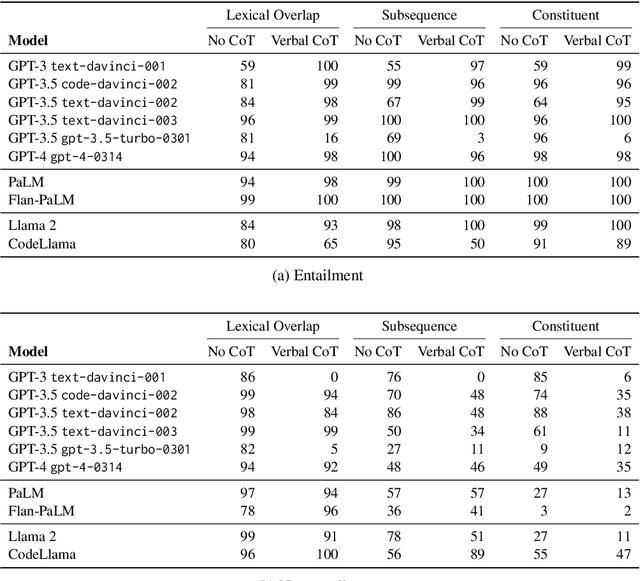
In-context learning (ICL) is now a common method for supervising large language models (LLMs): given labeled examples in the input context, the LLM learns to perform the task without weight updates. Despite ICL's prevalence and utility, we understand little about whether models supervised in this manner represent the underlying structure of their tasks, rather than superficial heuristics that only generalize to identically distributed examples. In this study, we investigate the robustness of LLMs supervised via ICL using the test case of sensitivity to syntax, which is a prerequisite for robust language understanding. Our experiments are based on two simple and well-controlled syntactic transformations tasks, where correct out-of-distribution generalization requires an accurate syntactic analysis of the input. We further investigate whether out-of-distribution generalization can be improved via chain-of-thought prompting, where the model is provided with a sequence of intermediate computation steps that illustrate how the task ought to be performed. In experiments with models from the GPT, PaLM, and Llama 2 families, we find large variance across LMs on this fundamental linguistic phenomenon, and that the variance is explained more by the composition of the pre-training corpus and supervision methods than by model size. In particular, we find evidence that models pre-trained on code generalize better, and benefit to a greater extent from chain-of-thought prompting.
Flan-MoE: Scaling Instruction-Finetuned Language Models with Sparse Mixture of Experts
May 24, 2023The explosive growth of language models and their applications have led to an increased demand for efficient and scalable methods. In this paper, we introduce Flan-MoE, a set of Instruction-Finetuned Sparse Mixture-of-Expert (MoE) models. We show that naively finetuning MoE models on a task-specific dataset (in other words, no instruction-finetuning) often yield worse performance compared to dense models of the same computational complexity. However, our Flan-MoE outperforms dense models under multiple experiment settings: instruction-finetuning only and instruction-finetuning followed by task-specific finetuning. This shows that instruction-finetuning is an essential stage for MoE models. Specifically, our largest model, Flan-MoE-32B, surpasses the performance of Flan-PaLM-62B on four benchmarks, while utilizing only one-third of the FLOPs. The success of Flan-MoE encourages rethinking the design of large-scale, high-performance language models, under the setting of task-agnostic learning.
Simfluence: Modeling the Influence of Individual Training Examples by Simulating Training Runs
Mar 14, 2023Training data attribution (TDA) methods offer to trace a model's prediction on any given example back to specific influential training examples. Existing approaches do so by assigning a scalar influence score to each training example, under a simplifying assumption that influence is additive. But in reality, we observe that training examples interact in highly non-additive ways due to factors such as inter-example redundancy, training order, and curriculum learning effects. To study such interactions, we propose Simfluence, a new paradigm for TDA where the goal is not to produce a single influence score per example, but instead a training run simulator: the user asks, ``If my model had trained on example $z_1$, then $z_2$, ..., then $z_n$, how would it behave on $z_{test}$?''; the simulator should then output a simulated training run, which is a time series predicting the loss on $z_{test}$ at every step of the simulated run. This enables users to answer counterfactual questions about what their model would have learned under different training curricula, and to directly see where in training that learning would occur. We present a simulator, Simfluence-Linear, that captures non-additive interactions and is often able to predict the spiky trajectory of individual example losses with surprising fidelity. Furthermore, we show that existing TDA methods such as TracIn and influence functions can be viewed as special cases of Simfluence-Linear. This enables us to directly compare methods in terms of their simulation accuracy, subsuming several prior TDA approaches to evaluation. In experiments on large language model (LLM) fine-tuning, we show that our method predicts loss trajectories with much higher accuracy than existing TDA methods (doubling Spearman's correlation and reducing mean-squared error by 75%) across several tasks, models, and training methods.
Larger language models do in-context learning differently
Mar 08, 2023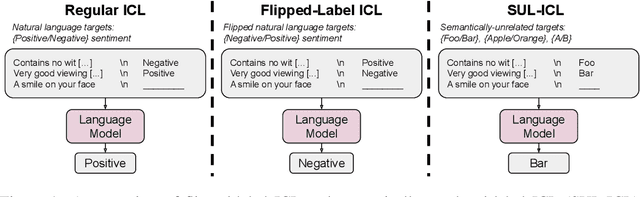



We study how in-context learning (ICL) in language models is affected by semantic priors versus input-label mappings. We investigate two setups-ICL with flipped labels and ICL with semantically-unrelated labels-across various model families (GPT-3, InstructGPT, Codex, PaLM, and Flan-PaLM). First, experiments on ICL with flipped labels show that overriding semantic priors is an emergent ability of model scale. While small language models ignore flipped labels presented in-context and thus rely primarily on semantic priors from pretraining, large models can override semantic priors when presented with in-context exemplars that contradict priors, despite the stronger semantic priors that larger models may hold. We next study semantically-unrelated label ICL (SUL-ICL), in which labels are semantically unrelated to their inputs (e.g., foo/bar instead of negative/positive), thereby forcing language models to learn the input-label mappings shown in in-context exemplars in order to perform the task. The ability to do SUL-ICL also emerges primarily with scale, and large-enough language models can even perform linear classification in a SUL-ICL setting. Finally, we evaluate instruction-tuned models and find that instruction tuning strengthens both the use of semantic priors and the capacity to learn input-label mappings, but more of the former.
The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
Feb 14, 2023



We study the design decisions of publicly available instruction tuning methods, and break down the development of Flan 2022 (Chung et al., 2022). Through careful ablation studies on the Flan Collection of tasks and methods, we tease apart the effect of design decisions which enable Flan-T5 to outperform prior work by 3-17%+ across evaluation settings. We find task balancing and enrichment techniques are overlooked but critical to effective instruction tuning, and in particular, training with mixed prompt settings (zero-shot, few-shot, and chain-of-thought) actually yields stronger (2%+) performance in all settings. In further experiments, we show Flan-T5 requires less finetuning to converge higher and faster than T5 on single downstream tasks, motivating instruction-tuned models as more computationally-efficient starting checkpoints for new tasks. Finally, to accelerate research on instruction tuning, we make the Flan 2022 collection of datasets, templates, and methods publicly available at https://github.com/google-research/FLAN/tree/main/flan/v2.