 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-context Learning Generalizes, But Not Always Robustly: The Case of Syntax
Paper and Code
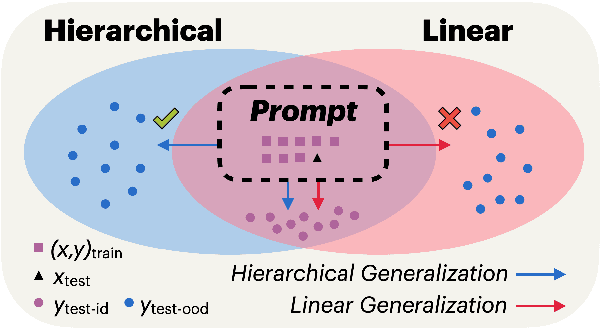
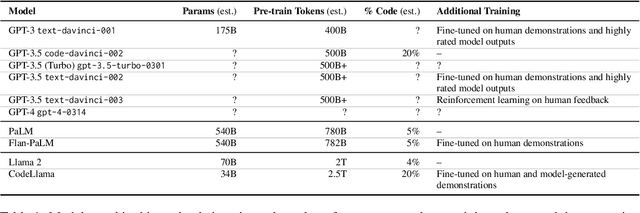

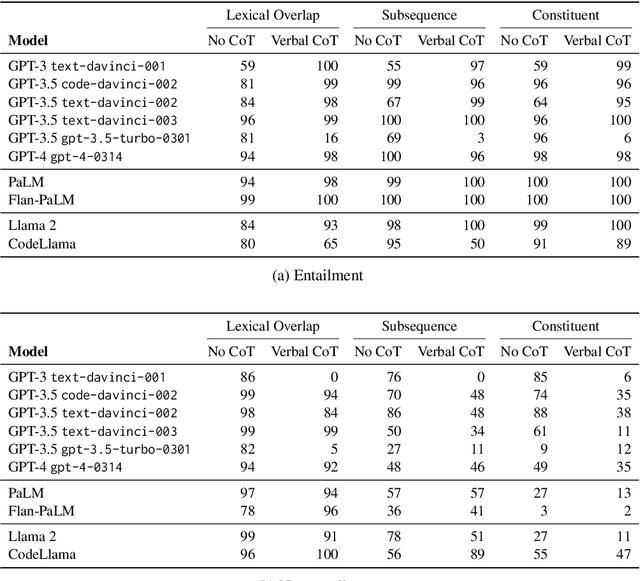
In-context learning (ICL) is now a common method for supervising large language models (LLMs): given labeled examples in the input context, the LLM learns to perform the task without weight updates. Despite ICL's prevalence and utility, we understand little about whether models supervised in this manner represent the underlying structure of their tasks, rather than superficial heuristics that only generalize to identically distributed examples. In this study, we investigate the robustness of LLMs supervised via ICL using the test case of sensitivity to syntax, which is a prerequisite for robust language understanding. Our experiments are based on two simple and well-controlled syntactic transformations tasks, where correct out-of-distribution generalization requires an accurate syntactic analysis of the input. We further investigate whether out-of-distribution generalization can be improved via chain-of-thought prompting, where the model is provided with a sequence of intermediate computation steps that illustrate how the task ought to be performed. In experiments with models from the GPT, PaLM, and Llama 2 families, we find large variance across LMs on this fundamental linguistic phenomenon, and that the variance is explained more by the composition of the pre-training corpus and supervision methods than by model size. In particular, we find evidence that models pre-trained on code generalize better, and benefit to a greater extent from chain-of-thought prompting.