 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRELIC: Evaluating Compositional Instruction Following via Language Recognition
Jun 05, 2025Large language models (LLMs) are increasingly expected to perform tasks based only on a specification of the task provided in context, without examples of inputs and outputs; this ability is referred to as instruction following. We introduce the Recognition of Languages In-Context (RELIC) framework to evaluate instruction following using language recognition: the task of determining if a string is generated by formal grammar. Unlike many standard evaluations of LLMs' ability to use their context, this task requires composing together a large number of instructions (grammar productions) retrieved from the context. Because the languages are synthetic, the task can be increased in complexity as LLMs' skills improve, and new instances can be automatically generated, mitigating data contamination. We evaluate state-of-the-art LLMs on RELIC and find that their accuracy can be reliably predicted from the complexity of the grammar and the individual example strings, and that even the most advanced LLMs currently available show near-chance performance on more complex grammars and samples, in line with theoretical expectations. We also use RELIC to diagnose how LLMs attempt to solve increasingly difficult reasoning tasks, finding that as the complexity of the language recognition task increases, models switch to relying on shallow heuristics instead of following complex instructions.
Between Circuits and Chomsky: Pre-pretraining on Formal Languages Imparts Linguistic Biases
Feb 26, 2025



Pretraining language models on formal languages can improve their acquisition of natural language, but it is unclear which features of the formal language impart an inductive bias that leads to effective transfer. Drawing on insights from linguistics and complexity theory, we hypothesize that effective transfer occurs when the formal language both captures dependency structures in natural language and remains within the computational limitations of the model architecture. Focusing on transformers, we find that formal languages with both these properties enable language models to achieve lower loss on natural language and better linguistic generalization compared to other languages. In fact, pre-pretraining, or training on formal-then-natural language, reduces loss more efficiently than the same amount of natural language. For a 1B-parameter language model trained on roughly 1.6B tokens of natural language, pre-pretraining achieves the same loss and better linguistic generalization with a 33% smaller token budget. We also give mechanistic evidence of cross-task transfer from formal to natural language: attention heads acquired during formal language pretraining remain crucial for the model's performance on syntactic evaluations.
How Does Code Pretraining Affect Language Model Task Performance?
Sep 06, 2024


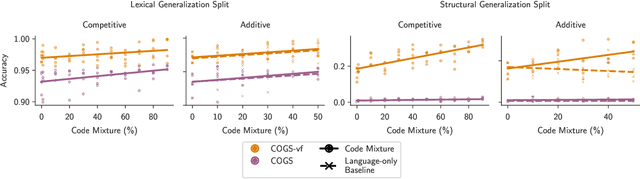
Large language models are increasingly trained on corpora containing both natural language and non-linguistic data like source code. Aside from aiding programming-related tasks, anecdotal evidence suggests that including code in pretraining corpora may improve performance on other, unrelated tasks, yet to date no work has been able to establish a causal connection by controlling between language and code data. Here we do just this. We pretrain language models on datasets which interleave natural language and code in two different settings: additive, in which the total volume of data seen during pretraining is held constant; and competitive, in which the volume of language data is held constant. We study how the pretraining mixture affects performance on (a) a diverse collection of tasks included in the BigBench benchmark, and (b) compositionality, measured by generalization accuracy on semantic parsing and syntactic transformations. We find that pretraining on higher proportions of code improves performance on compositional tasks involving structured output (like semantic parsing), and mathematics. Conversely, increase code mixture can harm performance on other tasks, including on tasks that requires sensitivity to linguistic structure such as syntax or morphology, and tasks measuring real-world knowledge.
The Illusion of State in State-Space Models
Apr 12, 2024


State-space models (SSMs) have emerged as a potential alternative architecture for building large language models (LLMs) compared to the previously ubiquitous transformer architecture. One theoretical weakness of transformers is that they cannot express certain kinds of sequential computation and state tracking (Merrill and Sabharwal, 2023), which SSMs are explicitly designed to address via their close architectural similarity to recurrent neural networks (RNNs). But do SSMs truly have an advantage (over transformers) in expressive power for state tracking? Surprisingly, the answer is no. Our analysis reveals that the expressive power of SSMs is limited very similarly to transformers: SSMs cannot express computation outside the complexity class $\mathsf{TC}^0$. In particular, this means they cannot solve simple state-tracking problems like permutation composition. It follows that SSMs are provably unable to accurately track chess moves with certain notation, evaluate code, or track entities in a long narrative. To supplement our formal analysis, we report experiments showing that Mamba-style SSMs indeed struggle with state tracking. Thus, despite its recurrent formulation, the "state" in an SSM is an illusion: SSMs have similar expressiveness limitations to non-recurrent models like transformers, which may fundamentally limit their ability to solve real-world state-tracking problems.
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Nov 20, 2023



We present GPQA, a challenging dataset of 448 multiple-choice questions written by domain experts in biology, physics, and chemistry. We ensure that the questions are high-quality and extremely difficult: experts who have or are pursuing PhDs in the corresponding domains reach 65% accuracy (74% when discounting clear mistakes the experts identified in retrospect), while highly skilled non-expert validators only reach 34% accuracy, despite spending on average over 30 minutes with unrestricted access to the web (i.e., the questions are "Google-proof"). The questions are also difficult for state-of-the-art AI systems, with our strongest GPT-4 based baseline achieving 39% accuracy. If we are to use future AI systems to help us answer very hard questions, for example, when developing new scientific knowledge, we need to develop scalable oversight methods that enable humans to supervise their outputs, which may be difficult even if the supervisors are themselves skilled and knowledgeable. The difficulty of GPQA both for skilled non-experts and frontier AI systems should enable realistic scalable oversight experiments, which we hope can help devise ways for human experts to reliably get truthful information from AI systems that surpass human capabilities.
Debate Helps Supervise Unreliable Experts
Nov 15, 2023As AI systems are used to answer more difficult questions and potentially help create new knowledge, judging the truthfulness of their outputs becomes more difficult and more important. How can we supervise unreliable experts, which have access to the truth but may not accurately report it, to give answers that are systematically true and don't just superficially seem true, when the supervisor can't tell the difference between the two on their own? In this work, we show that debate between two unreliable experts can help a non-expert judge more reliably identify the truth. We collect a dataset of human-written debates on hard reading comprehension questions where the judge has not read the source passage, only ever seeing expert arguments and short quotes selectively revealed by 'expert' debaters who have access to the passage. In our debates, one expert argues for the correct answer, and the other for an incorrect answer. Comparing debate to a baseline we call consultancy, where a single expert argues for only one answer which is correct half of the time, we find that debate performs significantly better, with 84% judge accuracy compared to consultancy's 74%. Debates are also more efficient, being 68% of the length of consultancies. By comparing human to AI debaters, we find evidence that with more skilled (in this case, human) debaters, the performance of debate goes up but the performance of consultancy goes down. Our error analysis also supports this trend, with 46% of errors in human debate attributable to mistakes by the honest debater (which should go away with increased skill); whereas 52% of errors in human consultancy are due to debaters obfuscating the relevant evidence from the judge (which should become worse with increased skill). Overall, these results show that debate is a promising approach for supervising increasingly capable but potentially unreliable AI systems.
In-context Learning Generalizes, But Not Always Robustly: The Case of Syntax
Nov 13, 2023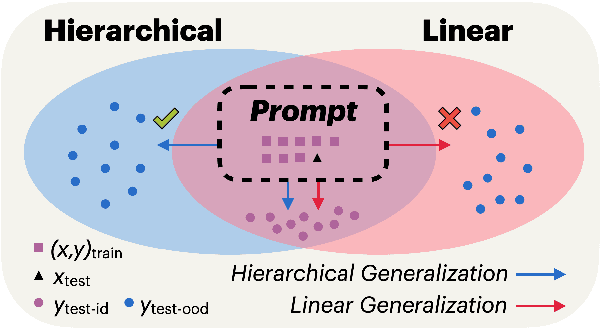
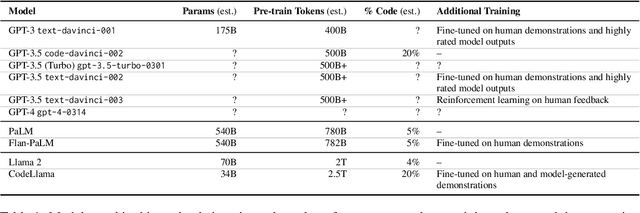

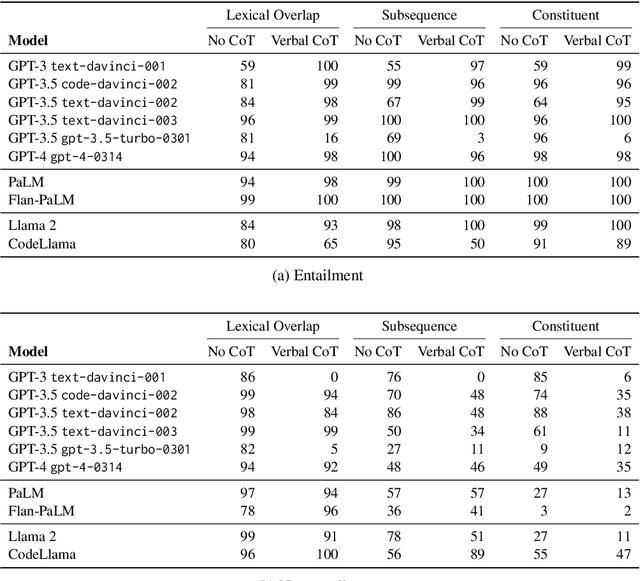
In-context learning (ICL) is now a common method for supervising large language models (LLMs): given labeled examples in the input context, the LLM learns to perform the task without weight updates. Despite ICL's prevalence and utility, we understand little about whether models supervised in this manner represent the underlying structure of their tasks, rather than superficial heuristics that only generalize to identically distributed examples. In this study, we investigate the robustness of LLMs supervised via ICL using the test case of sensitivity to syntax, which is a prerequisite for robust language understanding. Our experiments are based on two simple and well-controlled syntactic transformations tasks, where correct out-of-distribution generalization requires an accurate syntactic analysis of the input. We further investigate whether out-of-distribution generalization can be improved via chain-of-thought prompting, where the model is provided with a sequence of intermediate computation steps that illustrate how the task ought to be performed. In experiments with models from the GPT, PaLM, and Llama 2 families, we find large variance across LMs on this fundamental linguistic phenomenon, and that the variance is explained more by the composition of the pre-training corpus and supervision methods than by model size. In particular, we find evidence that models pre-trained on code generalize better, and benefit to a greater extent from chain-of-thought prompting.
How Abstract Is Linguistic Generalization in Large Language Models? Experiments with Argument Structure
Nov 08, 2023Language models are typically evaluated on their success at predicting the distribution of specific words in specific contexts. Yet linguistic knowledge also encodes relationships between contexts, allowing inferences between word distributions. We investigate the degree to which pre-trained Transformer-based large language models (LLMs) represent such relationships, focusing on the domain of argument structure. We find that LLMs perform well in generalizing the distribution of a novel noun argument between related contexts that were seen during pre-training (e.g., the active object and passive subject of the verb spray), succeeding by making use of the semantically-organized structure of the embedding space for word embeddings. However, LLMs fail at generalizations between related contexts that have not been observed during pre-training, but which instantiate more abstract, but well-attested structural generalizations (e.g., between the active object and passive subject of an arbitrary verb). Instead, in this case, LLMs show a bias to generalize based on linear order. This finding points to a limitation with current models and points to a reason for which their training is data-intensive.s reported here are available at https://github.com/clay-lab/structural-alternations.
The Impact of Depth and Width on Transformer Language Model Generalization
Oct 30, 2023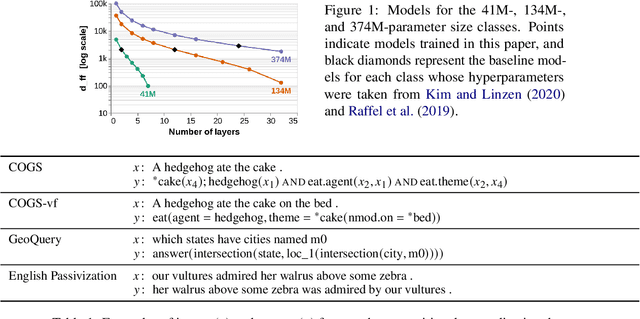
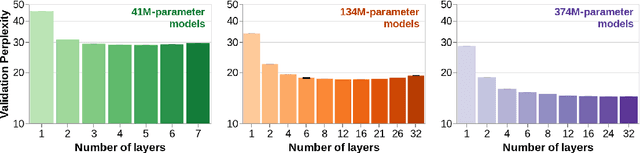

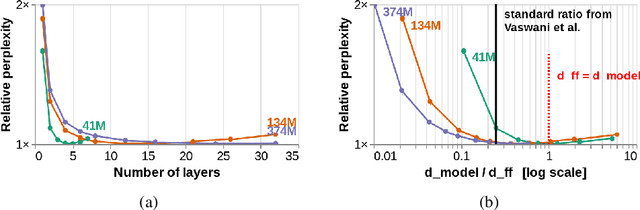
To process novel sentences, language models (LMs) must generalize compositionally -- combine familiar elements in new ways. What aspects of a model's structure promote compositional generalization? Focusing on transformers, we test the hypothesis, motivated by recent theoretical and empirical work, that transformers generalize more compositionally when they are deeper (have more layers). Because simply adding layers increases the total number of parameters, confounding depth and size, we construct three classes of models which trade off depth for width such that the total number of parameters is kept constant (41M, 134M and 374M parameters). We pretrain all models as LMs and fine-tune them on tasks that test for compositional generalization. We report three main conclusions: (1) after fine-tuning, deeper models generalize better out-of-distribution than shallower models do, but the relative benefit of additional layers diminishes rapidly; (2) within each family, deeper models show better language modeling performance, but returns are similarly diminishing; (3) the benefits of depth for compositional generalization cannot be attributed solely to better performance on language modeling or on in-distribution data.
(QA)$^2$: Question Answering with Questionable Assumptions
Dec 20, 2022Naturally-occurring information-seeking questions often contain questionable assumptions -- assumptions that are false or unverifiable. Questions containing questionable assumptions are challenging because they require a distinct answer strategy that deviates from typical answers to information-seeking questions. For instance, the question "When did Marie Curie discover Uranium?" cannot be answered as a typical when question without addressing the false assumption "Marie Curie discovered Uranium". In this work, we propose (QA)$^2$ (Question Answering with Questionable Assumptions), an open-domain evaluation dataset consisting of naturally-occurring search engine queries that may or may not contain questionable assumptions. To be successful on (QA)$^2$, systems must be able to detect questionable assumptions and also be able to produce adequate responses for both typical information-seeking questions and ones with questionable assumptions. We find that current models do struggle with handling questionable assumptions -- the best performing model achieves 59% human rater acceptability on abstractive QA with (QA)$^2$ questions, leaving substantial headroom for progress.