 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtom: Efficient On-Device Video-Language Pipelines Through Modular Reuse
Dec 18, 2025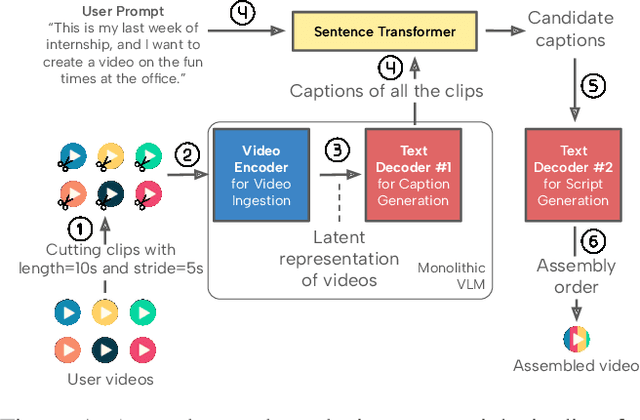
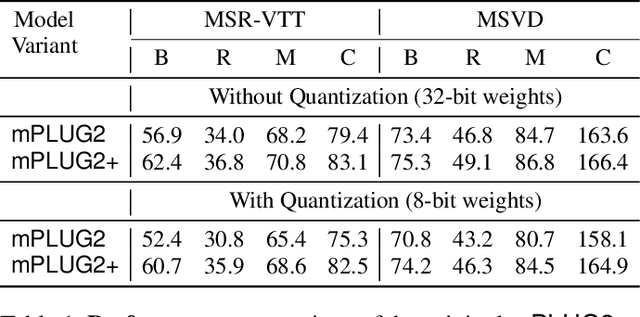
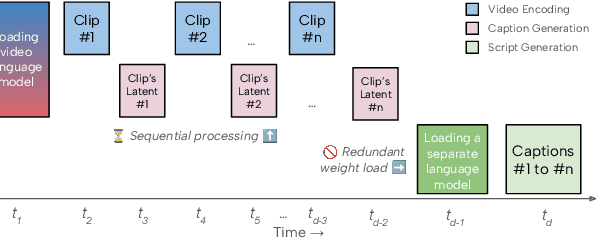
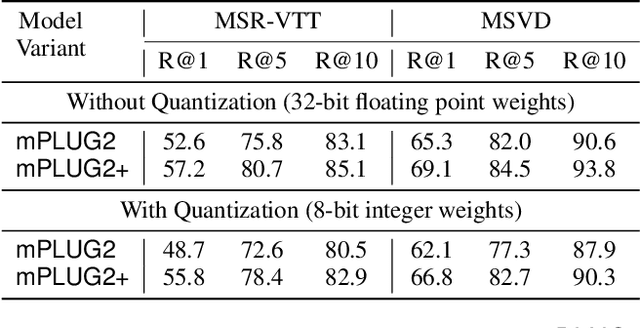
Recent advances in video-language models have enabled powerful applications like video retrieval, captioning, and assembly. However, executing such multi-stage pipelines efficiently on mobile devices remains challenging due to redundant model loads and fragmented execution. We introduce Atom, an on-device system that restructures video-language pipelines for fast and efficient execution. Atom decomposes a billion-parameter model into reusable modules, such as the visual encoder and language decoder, and reuses them across subtasks like captioning, reasoning, and indexing. This reuse-centric design eliminates repeated model loading and enables parallel execution, reducing end-to-end latency without sacrificing performance. On commodity smartphones, Atom achieves 27--33% faster execution compared to non-reuse baselines, with only marginal performance drop ($\leq$ 2.3 Recall@1 in retrieval, $\leq$ 1.5 CIDEr in captioning). These results position Atom as a practical, scalable approach for efficient video-language understanding on edge devices.
SKALD: Learning-Based Shot Assembly for Coherent Multi-Shot Video Creation
Mar 11, 2025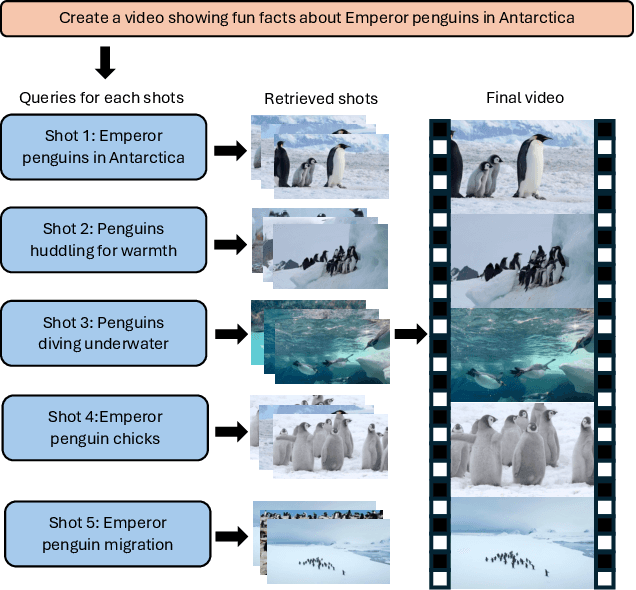
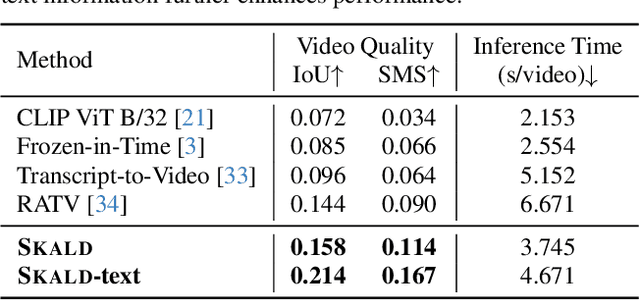

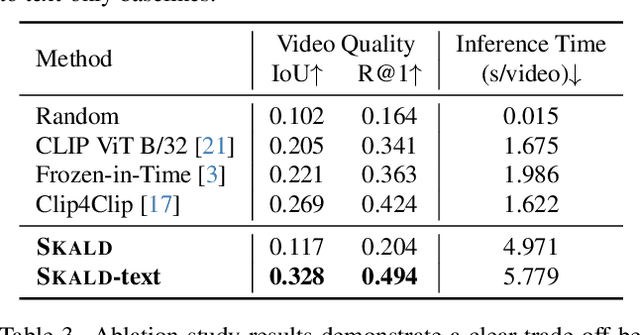
We present SKALD, a multi-shot video assembly method that constructs coherent video sequences from candidate shots with minimal reliance on text. Central to our approach is the Learned Clip Assembly (LCA) score, a learning-based metric that measures temporal and semantic relationships between shots to quantify narrative coherence. We tackle the exponential complexity of combining multiple shots with an efficient beam-search algorithm guided by the LCA score. To train our model effectively with limited human annotations, we propose two tasks for the LCA encoder: Shot Coherence Learning, which uses contrastive learning to distinguish coherent and incoherent sequences, and Feature Regression, which converts these learned representations into a real-valued coherence score. We develop two variants: a base SKALD model that relies solely on visual coherence and SKALD-text, which integrates auxiliary text information when available. Experiments on the VSPD and our curated MSV3C datasets show that SKALD achieves an improvement of up to 48.6% in IoU and a 43% speedup over the state-of-the-art methods. A user study further validates our approach, with 45% of participants favoring SKALD-assembled videos, compared to 22% preferring text-based assembly methods.
Decoupling the components of geometric understanding in Vision Language Models
Mar 05, 2025Understanding geometry relies heavily on vision. In this work, we evaluate whether state-of-the-art vision language models (VLMs) can understand simple geometric concepts. We use a paradigm from cognitive science that isolates visual understanding of simple geometry from the many other capabilities it is often conflated with such as reasoning and world knowledge. We compare model performance with human adults from the USA, as well as with prior research on human adults without formal education from an Amazonian indigenous group. We find that VLMs consistently underperform both groups of human adults, although they succeed with some concepts more than others. We also find that VLM geometric understanding is more brittle than human understanding, and is not robust when tasks require mental rotation. This work highlights interesting differences in the origin of geometric understanding in humans and machines -- e.g. from printed materials used in formal education vs. interactions with the physical world or a combination of the two -- and a small step toward understanding these differences.
The in-context inductive biases of vision-language models differ across modalities
Feb 03, 2025Inductive biases are what allow learners to make guesses in the absence of conclusive evidence. These biases have often been studied in cognitive science using concepts or categories -- e.g. by testing how humans generalize a new category from a few examples that leave the category boundary ambiguous. We use these approaches to study generalization in foundation models during in-context learning. Modern foundation models can condition on both vision and text, and differences in how they interpret and learn from these different modalities is an emerging area of study. Here, we study how their generalizations vary by the modality in which stimuli are presented, and the way the stimuli are described in text. We study these biases with three different experimental paradigms, across three different vision-language models. We find that the models generally show some bias towards generalizing according to shape over color. This shape bias tends to be amplified when the examples are presented visually. By contrast, when examples are presented in text, the ordering of adjectives affects generalization. However, the extent of these effects vary across models and paradigms. These results help to reveal how vision-language models represent different types of inputs in context, and may have practical implications for the use of vision-language models.
ReMI: A Dataset for Reasoning with Multiple Images
Jun 13, 2024



With the continuous advancement of large language models (LLMs), it is essential to create new benchmarks to effectively evaluate their expanding capabilities and identify areas for improvement. This work focuses on multi-image reasoning, an emerging capability in state-of-the-art LLMs. We introduce ReMI, a dataset designed to assess LLMs' ability to Reason with Multiple Images. This dataset encompasses a diverse range of tasks, spanning various reasoning domains such as math, physics, logic, code, table/chart understanding, and spatial and temporal reasoning. It also covers a broad spectrum of characteristics found in multi-image reasoning scenarios. We have benchmarked several cutting-edge LLMs using ReMI and found a substantial gap between their performance and human-level proficiency. This highlights the challenges in multi-image reasoning and the need for further research. Our analysis also reveals the strengths and weaknesses of different models, shedding light on the types of reasoning that are currently attainable and areas where future models require improvement. To foster further research in this area, we are releasing ReMI publicly: https://huggingface.co/datasets/mehrankazemi/ReMI.
HanDiffuser: Text-to-Image Generation With Realistic Hand Appearances
Mar 04, 2024



Text-to-image generative models can generate high-quality humans, but realism is lost when generating hands. Common artifacts include irregular hand poses, shapes, incorrect numbers of fingers, and physically implausible finger orientations. To generate images with realistic hands, we propose a novel diffusion-based architecture called HanDiffuser that achieves realism by injecting hand embeddings in the generative process. HanDiffuser consists of two components: a Text-to-Hand-Params diffusion model to generate SMPL-Body and MANO-Hand parameters from input text prompts, and a Text-Guided Hand-Params-to-Image diffusion model to synthesize images by conditioning on the prompts and hand parameters generated by the previous component. We incorporate multiple aspects of hand representation, including 3D shapes and joint-level finger positions, orientations and articulations, for robust learning and reliable performance during inference. We conduct extensive quantitative and qualitative experiments and perform user studies to demonstrate the efficacy of our method in generating images with high-quality hands.
How do Large Language Models Navigate Conflicts between Honesty and Helpfulness?
Feb 13, 2024In day-to-day communication, people often approximate the truth - for example, rounding the time or omitting details - in order to be maximally helpful to the listener. How do large language models (LLMs) handle such nuanced trade-offs? To address this question, we use psychological models and experiments designed to characterize human behavior to analyze LLMs. We test a range of LLMs and explore how optimization for human preferences or inference-time reasoning affects these trade-offs. We find that reinforcement learning from human feedback improves both honesty and helpfulness, while chain-of-thought prompting skews LLMs towards helpfulness over honesty. Finally, GPT-4 Turbo demonstrates human-like response patterns including sensitivity to the conversational framing and listener's decision context. Our findings reveal the conversational values internalized by LLMs and suggest that even these abstract values can, to a degree, be steered by zero-shot prompting.
PIVOT: Iterative Visual Prompting Elicits Actionable Knowledge for VLMs
Feb 12, 2024



Vision language models (VLMs) have shown impressive capabilities across a variety of tasks, from logical reasoning to visual understanding. This opens the door to richer interaction with the world, for example robotic control. However, VLMs produce only textual outputs, while robotic control and other spatial tasks require outputting continuous coordinates, actions, or trajectories. How can we enable VLMs to handle such settings without fine-tuning on task-specific data? In this paper, we propose a novel visual prompting approach for VLMs that we call Prompting with Iterative Visual Optimization (PIVOT), which casts tasks as iterative visual question answering. In each iteration, the image is annotated with a visual representation of proposals that the VLM can refer to (e.g., candidate robot actions, localizations, or trajectories). The VLM then selects the best ones for the task. These proposals are iteratively refined, allowing the VLM to eventually zero in on the best available answer. We investigate PIVOT on real-world robotic navigation, real-world manipulation from images, instruction following in simulation, and additional spatial inference tasks such as localization. We find, perhaps surprisingly, that our approach enables zero-shot control of robotic systems without any robot training data, navigation in a variety of environments, and other capabilities. Although current performance is far from perfect, our work highlights potentials and limitations of this new regime and shows a promising approach for Internet-Scale VLMs in robotic and spatial reasoning domains. Website: pivot-prompt.github.io and HuggingFace: https://huggingface.co/spaces/pivot-prompt/pivot-prompt-demo.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
A Systematic Comparison of Syllogistic Reasoning in Humans and Language Models
Nov 01, 2023



A central component of rational behavior is logical inference: the process of determining which conclusions follow from a set of premises. Psychologists have documented several ways in which humans' inferences deviate from the rules of logic. Do language models, which are trained on text generated by humans, replicate these biases, or are they able to overcome them? Focusing on the case of syllogisms -- inferences from two simple premises, which have been studied extensively in psychology -- we show that larger models are more logical than smaller ones, and also more logical than humans. At the same time, even the largest models make systematic errors, some of which mirror human reasoning biases such as ordering effects and logical fallacies. Overall, we find that language models mimic the human biases included in their training data, but are able to overcome them in some cases.