 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOIST-Former: Hand-held Objects Identification, Segmentation, and Tracking in the Wild
Apr 22, 2024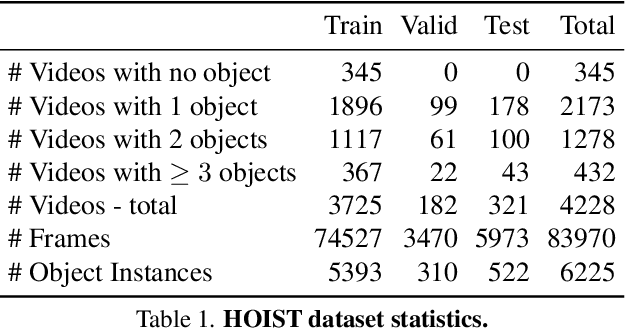
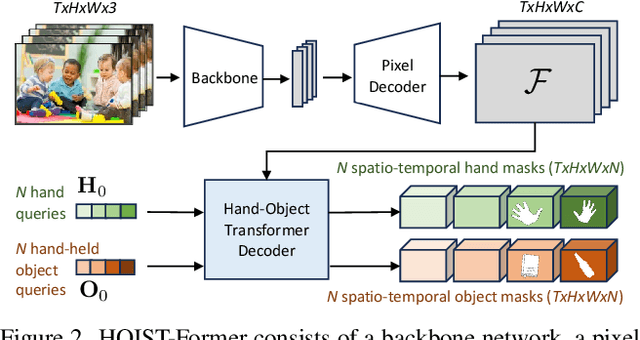
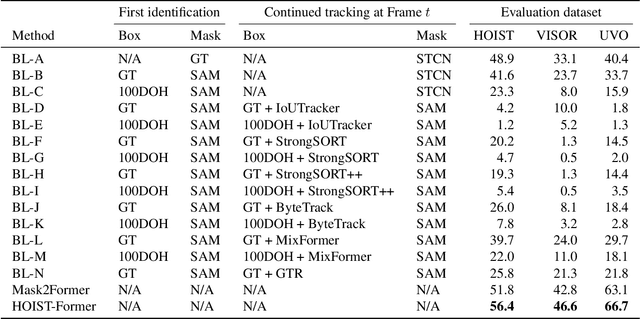
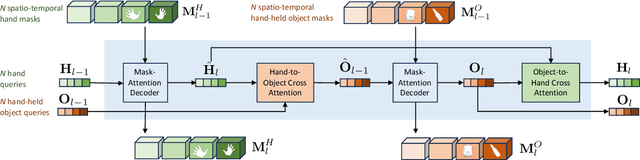
We address the challenging task of identifying, segmenting, and tracking hand-held objects, which is crucial for applications such as human action segmentation and performance evaluation. This task is particularly challenging due to heavy occlusion, rapid motion, and the transitory nature of objects being hand-held, where an object may be held, released, and subsequently picked up again. To tackle these challenges, we have developed a novel transformer-based architecture called HOIST-Former. HOIST-Former is adept at spatially and temporally segmenting hands and objects by iteratively pooling features from each other, ensuring that the processes of identification, segmentation, and tracking of hand-held objects depend on the hands' positions and their contextual appearance. We further refine HOIST-Former with a contact loss that focuses on areas where hands are in contact with objects. Moreover, we also contribute an in-the-wild video dataset called HOIST, which comprises 4,125 videos complete with bounding boxes, segmentation masks, and tracking IDs for hand-held objects. Through experiments on the HOIST dataset and two additional public datasets, we demonstrate the efficacy of HOIST-Former in segmenting and tracking hand-held objects.
HanDiffuser: Text-to-Image Generation With Realistic Hand Appearances
Mar 04, 2024



Text-to-image generative models can generate high-quality humans, but realism is lost when generating hands. Common artifacts include irregular hand poses, shapes, incorrect numbers of fingers, and physically implausible finger orientations. To generate images with realistic hands, we propose a novel diffusion-based architecture called HanDiffuser that achieves realism by injecting hand embeddings in the generative process. HanDiffuser consists of two components: a Text-to-Hand-Params diffusion model to generate SMPL-Body and MANO-Hand parameters from input text prompts, and a Text-Guided Hand-Params-to-Image diffusion model to synthesize images by conditioning on the prompts and hand parameters generated by the previous component. We incorporate multiple aspects of hand representation, including 3D shapes and joint-level finger positions, orientations and articulations, for robust learning and reliable performance during inference. We conduct extensive quantitative and qualitative experiments and perform user studies to demonstrate the efficacy of our method in generating images with high-quality hands.
Detecting Hands and Recognizing Physical Contact in the Wild
Oct 19, 2020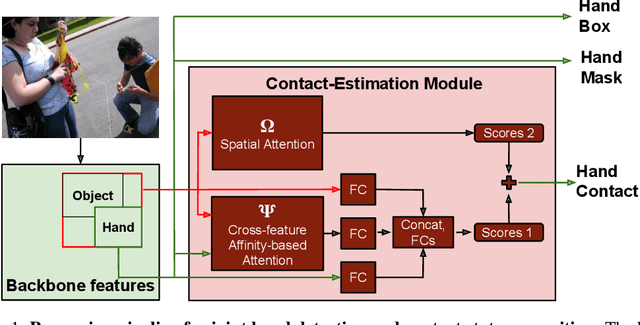
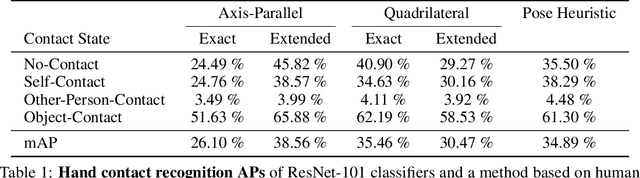
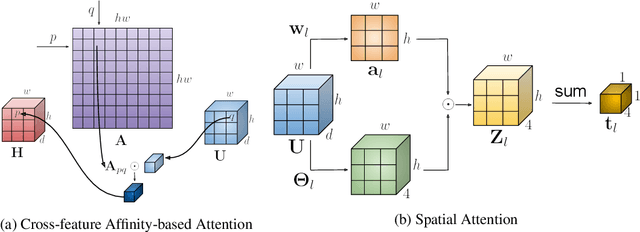
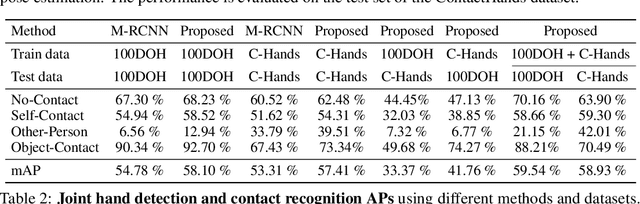
We investigate a new problem of detecting hands and recognizing their physical contact state in unconstrained conditions. This is a challenging inference task given the need to reason beyond the local appearance of hands. The lack of training annotations indicating which object or parts of an object the hand is in contact with further complicates the task. We propose a novel convolutional network based on Mask-RCNN that can jointly learn to localize hands and predict their physical contact to address this problem. The network uses outputs from another object detector to obtain locations of objects present in the scene. It uses these outputs and hand locations to recognize the hand's contact state using two attention mechanisms. The first attention mechanism is based on the hand and a region's affinity, enclosing the hand and the object, and densely pools features from this region to the hand region. The second attention module adaptively selects salient features from this plausible region of contact. To develop and evaluate our method's performance, we introduce a large-scale dataset called ContactHands, containing unconstrained images annotated with hand locations and contact states. The proposed network, including the parameters of attention modules, is end-to-end trainable. This network achieves approximately 7\% relative improvement over a baseline network that was built on the vanilla Mask-RCNN architecture and trained for recognizing hand contact states.
Contextual Attention for Hand Detection in the Wild
Apr 09, 2019
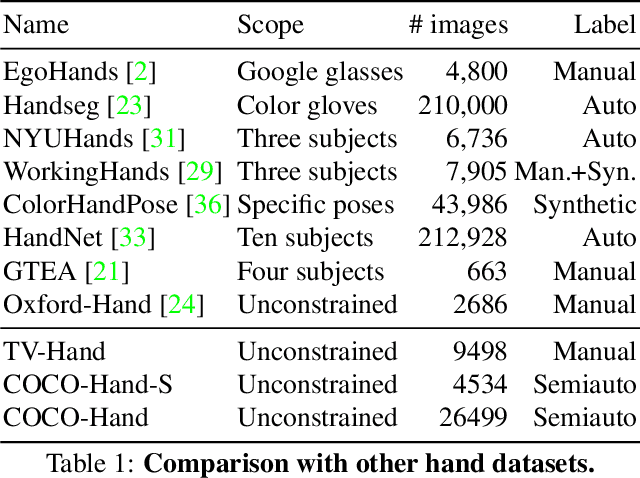
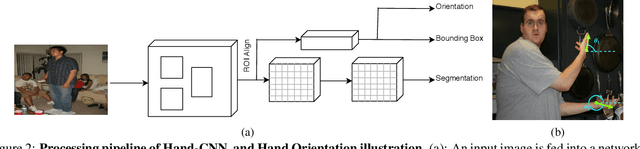
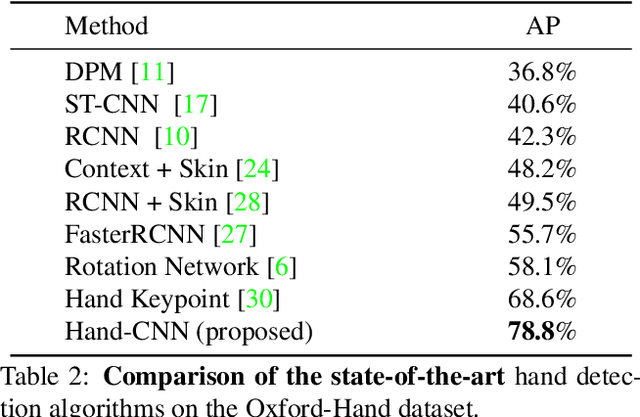
We present Hand-CNN, a novel convolutional network architecture for detecting hand masks and predicting hand orientations in unconstrained images. Hand-CNN extends MaskRCNN with a novel attention mechanism to incorporate contextual cues in the detection process. This attention mechanism can be implemented as an efficient network module that captures non-local dependencies between features. This network module can be inserted at different stages of an object detection network, and the entire detector can be trained end-to-end. We also introduce a large-scale annotated hand dataset containing hands in unconstrained images for training and evaluation. We show that Hand-CNN outperforms existing methods on several datasets, including our hand detection benchmark and the publicly available PASCAL VOC human layout challenge. We also conduct ablation studies on hand detection to show the effectiveness of the proposed contextual attention module.