 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOIST-Former: Hand-held Objects Identification, Segmentation, and Tracking in the Wild
Apr 22, 2024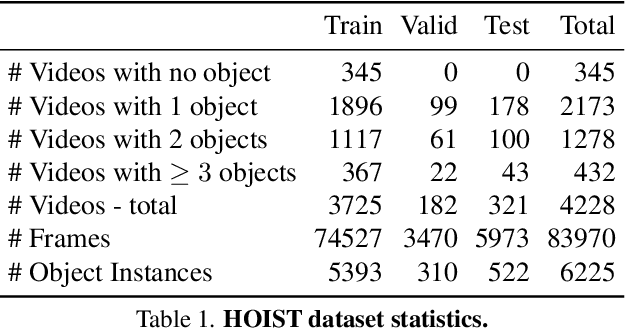
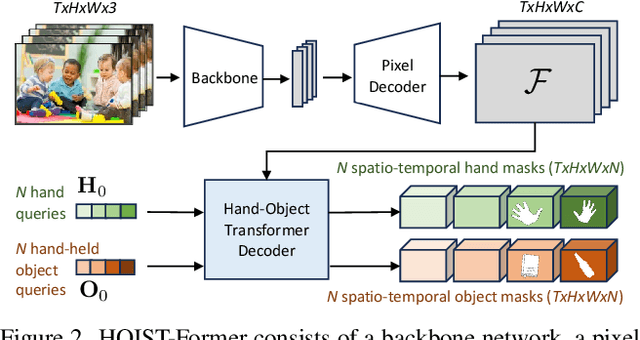
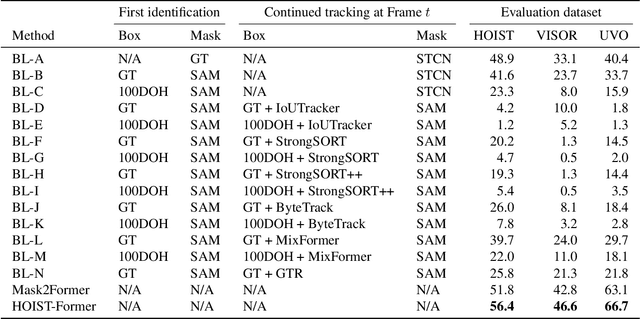
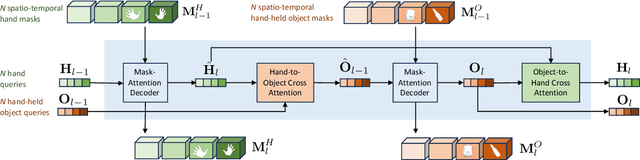
We address the challenging task of identifying, segmenting, and tracking hand-held objects, which is crucial for applications such as human action segmentation and performance evaluation. This task is particularly challenging due to heavy occlusion, rapid motion, and the transitory nature of objects being hand-held, where an object may be held, released, and subsequently picked up again. To tackle these challenges, we have developed a novel transformer-based architecture called HOIST-Former. HOIST-Former is adept at spatially and temporally segmenting hands and objects by iteratively pooling features from each other, ensuring that the processes of identification, segmentation, and tracking of hand-held objects depend on the hands' positions and their contextual appearance. We further refine HOIST-Former with a contact loss that focuses on areas where hands are in contact with objects. Moreover, we also contribute an in-the-wild video dataset called HOIST, which comprises 4,125 videos complete with bounding boxes, segmentation masks, and tracking IDs for hand-held objects. Through experiments on the HOIST dataset and two additional public datasets, we demonstrate the efficacy of HOIST-Former in segmenting and tracking hand-held objects.
Predicting Goal-directed Human Attention Using Inverse Reinforcement Learning
Jun 25, 2020
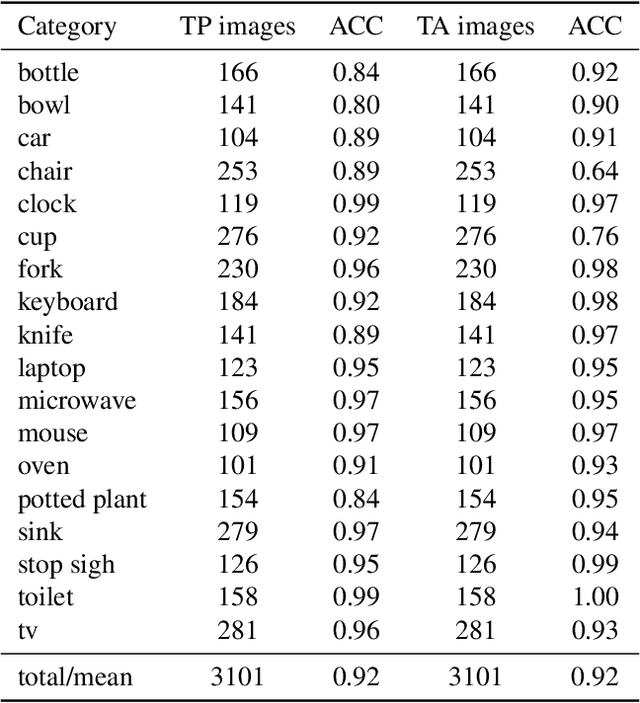

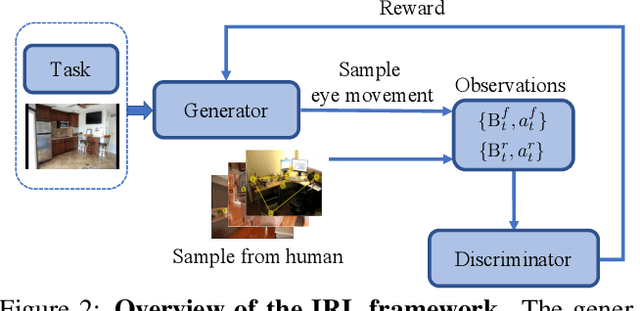
Being able to predict human gaze behavior has obvious importance for behavioral vision and for computer vision applications. Most models have mainly focused on predicting free-viewing behavior using saliency maps, but these predictions do not generalize to goal-directed behavior, such as when a person searches for a visual target object. We propose the first inverse reinforcement learning (IRL) model to learn the internal reward function and policy used by humans during visual search. The viewer's internal belief states were modeled as dynamic contextual belief maps of object locations. These maps were learned by IRL and then used to predict behavioral scanpaths for multiple target categories. To train and evaluate our IRL model we created COCO-Search18, which is now the largest dataset of high-quality search fixations in existence. COCO-Search18 has 10 participants searching for each of 18 target-object categories in 6202 images, making about 300,000 goal-directed fixations. When trained and evaluated on COCO-Search18, the IRL model outperformed baseline models in predicting search fixation scanpaths, both in terms of similarity to human search behavior and search efficiency. Finally, reward maps recovered by the IRL model reveal distinctive target-dependent patterns of object prioritization, which we interpret as a learned object context.
Predicting Goal-directed Attention Control Using Inverse-Reinforcement Learning
Jan 31, 2020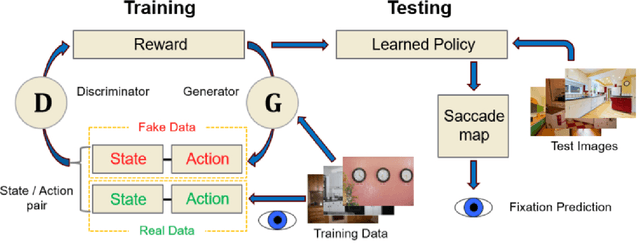



Understanding how goal states control behavior is a question ripe for interrogation by new methods from machine learning. These methods require large and labeled datasets to train models. To annotate a large-scale image dataset with observed search fixations, we collected 16,184 fixations from people searching for either microwaves or clocks in a dataset of 4,366 images (MS-COCO). We then used this behaviorally-annotated dataset and the machine learning method of Inverse-Reinforcement Learning (IRL) to learn target-specific reward functions and policies for these two target goals. Finally, we used these learned policies to predict the fixations of 60 new behavioral searchers (clock = 30, microwave = 30) in a disjoint test dataset of kitchen scenes depicting both a microwave and a clock (thus controlling for differences in low-level image contrast). We found that the IRL model predicted behavioral search efficiency and fixation-density maps using multiple metrics. Moreover, reward maps from the IRL model revealed target-specific patterns that suggest, not just attention guidance by target features, but also guidance by scene context (e.g., fixations along walls in the search of clocks). Using machine learning and the psychologically-meaningful principle of reward, it is possible to learn the visual features used in goal-directed attention control.