 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating metamers of human scene understanding
Jan 16, 2026Human vision combines low-resolution "gist" information from the visual periphery with sparse but high-resolution information from fixated locations to construct a coherent understanding of a visual scene. In this paper, we introduce MetamerGen, a tool for generating scenes that are aligned with latent human scene representations. MetamerGen is a latent diffusion model that combines peripherally obtained scene gist information with information obtained from scene-viewing fixations to generate image metamers for what humans understand after viewing a scene. Generating images from both high and low resolution (i.e. "foveated") inputs constitutes a novel image-to-image synthesis problem, which we tackle by introducing a dual-stream representation of the foveated scenes consisting of DINOv2 tokens that fuse detailed features from fixated areas with peripherally degraded features capturing scene context. To evaluate the perceptual alignment of MetamerGen generated images to latent human scene representations, we conducted a same-different behavioral experiment where participants were asked for a "same" or "different" response between the generated and the original image. With that, we identify scene generations that are indeed metamers for the latent scene representations formed by the viewers. MetamerGen is a powerful tool for understanding scene understanding. Our proof-of-concept analyses uncovered specific features at multiple levels of visual processing that contributed to human judgments. While it can generate metamers even conditioned on random fixations, we find that high-level semantic alignment most strongly predicts metamerism when the generated scenes are conditioned on viewers' own fixated regions.
Predicting Visual Attention in Graphic Design Documents
Jul 02, 2024



We present a model for predicting visual attention during the free viewing of graphic design documents. While existing works on this topic have aimed at predicting static saliency of graphic designs, our work is the first attempt to predict both spatial attention and dynamic temporal order in which the document regions are fixated by gaze using a deep learning based model. We propose a two-stage model for predicting dynamic attention on such documents, with webpages being our primary choice of document design for demonstration. In the first stage, we predict the saliency maps for each of the document components (e.g. logos, banners, texts, etc. for webpages) conditioned on the type of document layout. These component saliency maps are then jointly used to predict the overall document saliency. In the second stage, we use these layout-specific component saliency maps as the state representation for an inverse reinforcement learning model of fixation scanpath prediction during document viewing. To test our model, we collected a new dataset consisting of eye movements from 41 people freely viewing 450 webpages (the largest dataset of its kind). Experimental results show that our model outperforms existing models in both saliency and scanpath prediction for webpages, and also generalizes very well to other graphic design documents such as comics, posters, mobile UIs, etc. and natural images.
Decoding the visual attention of pathologists to reveal their level of expertise
Mar 25, 2024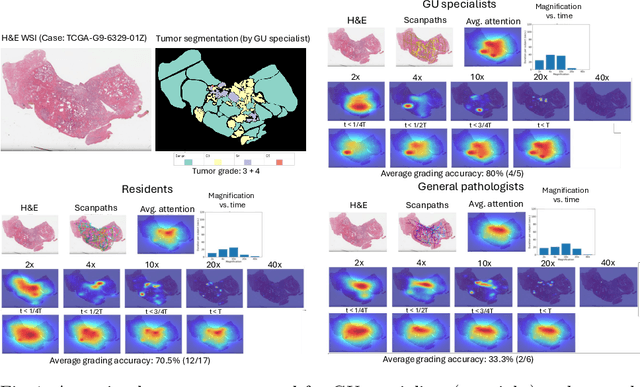
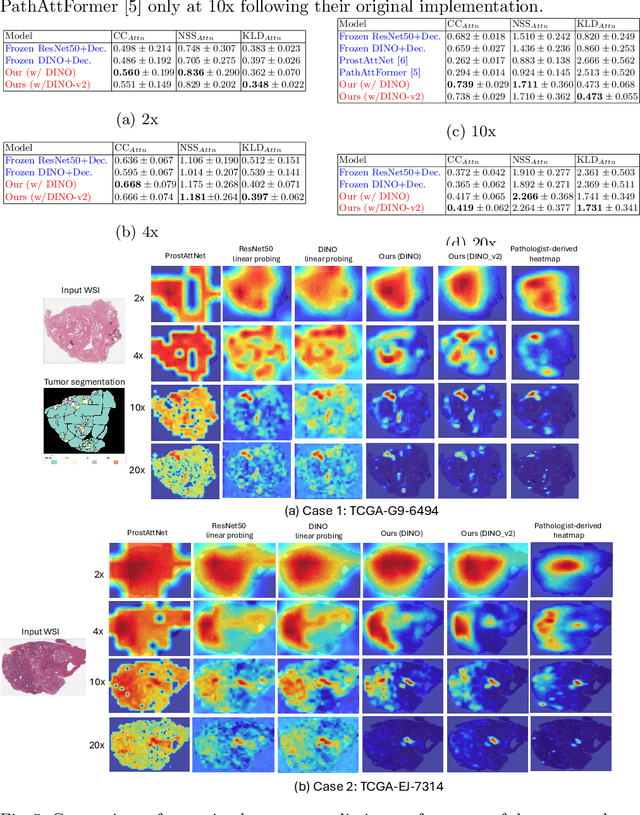
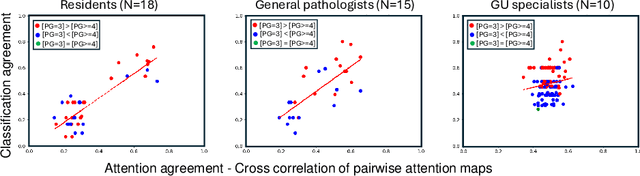

We present a method for classifying the expertise of a pathologist based on how they allocated their attention during a cancer reading. We engage this decoding task by developing a novel method for predicting the attention of pathologists as they read whole-slide Images (WSIs) of prostate and make cancer grade classifications. Our ground truth measure of a pathologists' attention is the x, y and z (magnification) movement of their viewport as they navigated through WSIs during readings, and to date we have the attention behavior of 43 pathologists reading 123 WSIs. These data revealed that specialists have higher agreement in both their attention and cancer grades compared to general pathologists and residents, suggesting that sufficient information may exist in their attention behavior to classify their expertise level. To attempt this, we trained a transformer-based model to predict the visual attention heatmaps of resident, general, and specialist (GU) pathologists during Gleason grading. Based solely on a pathologist's attention during a reading, our model was able to predict their level of expertise with 75.3%, 56.1%, and 77.2% accuracy, respectively, better than chance and baseline models. Our model therefore enables a pathologist's expertise level to be easily and objectively evaluated, important for pathology training and competency assessment. Tools developed from our model could also be used to help pathology trainees learn how to read WSIs like an expert.
Reconstruction-guided attention improves the robustness and shape processing of neural networks
Sep 27, 2022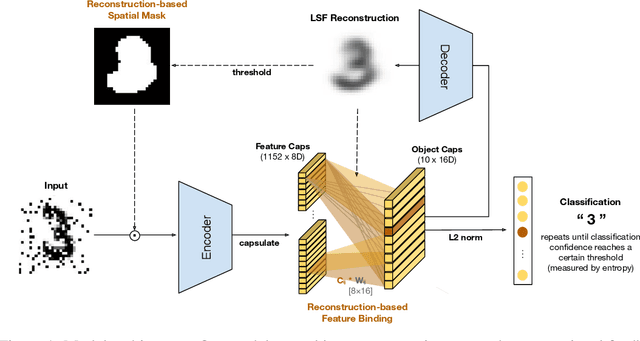
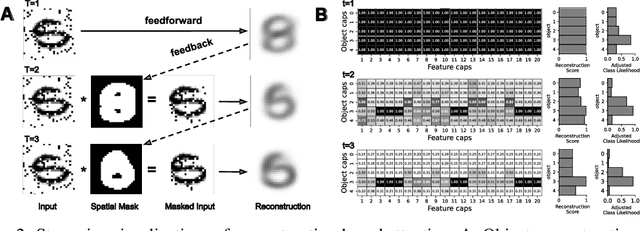
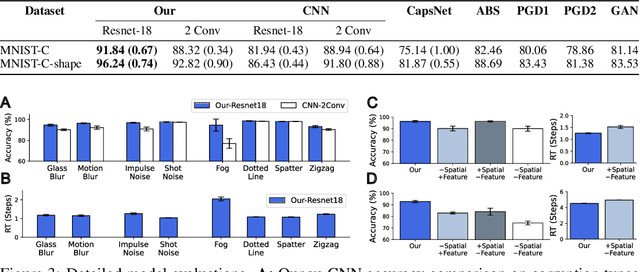
Many visual phenomena suggest that humans use top-down generative or reconstructive processes to create visual percepts (e.g., imagery, object completion, pareidolia), but little is known about the role reconstruction plays in robust object recognition. We built an iterative encoder-decoder network that generates an object reconstruction and used it as top-down attentional feedback to route the most relevant spatial and feature information to feed-forward object recognition processes. We tested this model using the challenging out-of-distribution digit recognition dataset, MNIST-C, where 15 different types of transformation and corruption are applied to handwritten digit images. Our model showed strong generalization performance against various image perturbations, on average outperforming all other models including feedforward CNNs and adversarially trained networks. Our model is particularly robust to blur, noise, and occlusion corruptions, where shape perception plays an important role. Ablation studies further reveal two complementary roles of spatial and feature-based attention in robust object recognition, with the former largely consistent with spatial masking benefits in the attention literature (the reconstruction serves as a mask) and the latter mainly contributing to the model's inference speed (i.e., number of time steps to reach a certain confidence threshold) by reducing the space of possible object hypotheses. We also observed that the model sometimes hallucinates a non-existing pattern out of noise, leading to highly interpretable human-like errors. Our study shows that modeling reconstruction-based feedback endows AI systems with a powerful attention mechanism, which can help us understand the role of generating perception in human visual processing.
Visual attention analysis of pathologists examining whole slide images of Prostate cancer
Feb 17, 2022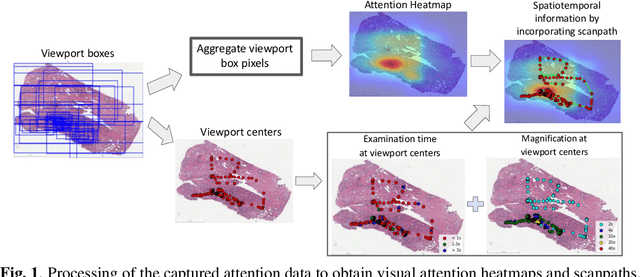
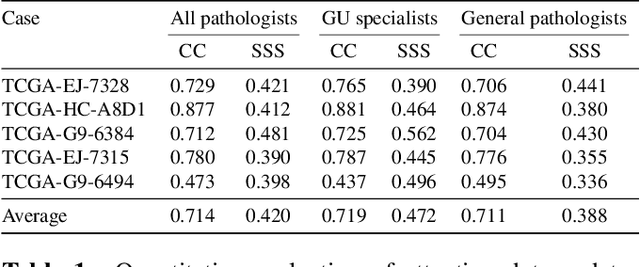
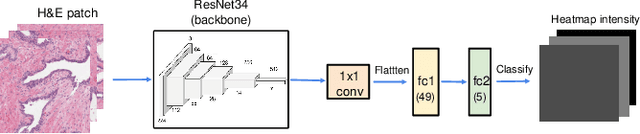
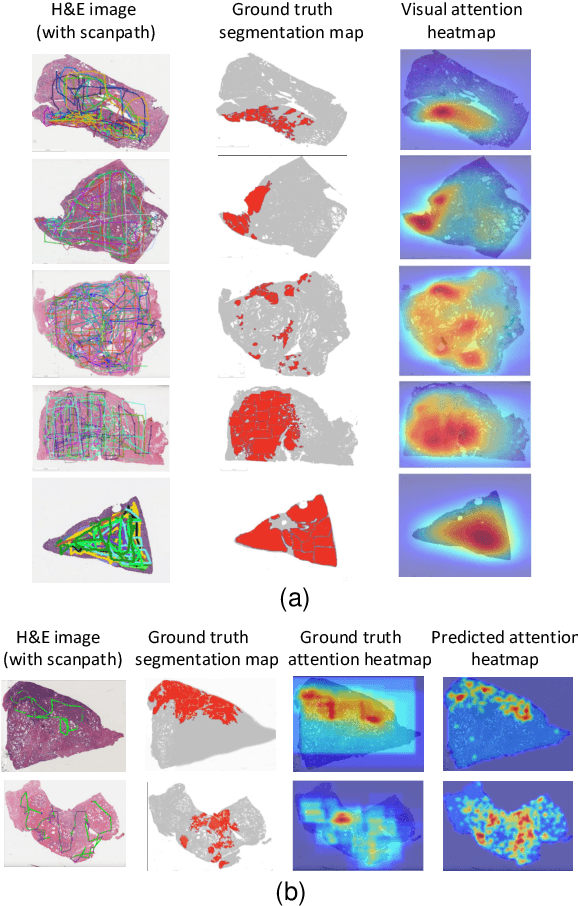
We study the attention of pathologists as they examine whole-slide images (WSIs) of prostate cancer tissue using a digital microscope. To the best of our knowledge, our study is the first to report in detail how pathologists navigate WSIs of prostate cancer as they accumulate information for their diagnoses. We collected slide navigation data (i.e., viewport location, magnification level, and time) from 13 pathologists in 2 groups (5 genitourinary (GU) specialists and 8 general pathologists) and generated visual attention heatmaps and scanpaths. Each pathologist examined five WSIs from the TCGA PRAD dataset, which were selected by a GU pathology specialist. We examined and analyzed the distributions of visual attention for each group of pathologists after each WSI was examined. To quantify the relationship between a pathologist's attention and evidence for cancer in the WSI, we obtained tumor annotations from a genitourinary specialist. We used these annotations to compute the overlap between the distribution of visual attention and annotated tumor region to identify strong correlations. Motivated by this analysis, we trained a deep learning model to predict visual attention on unseen WSIs. We find that the attention heatmaps predicted by our model correlate quite well with the ground truth attention heatmap and tumor annotations on a test set of 17 WSIs by using various spatial and temporal evaluation metrics.
Predicting Goal-directed Attention Control Using Inverse-Reinforcement Learning
Jan 31, 2020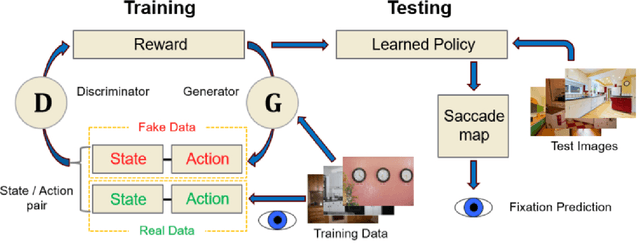



Understanding how goal states control behavior is a question ripe for interrogation by new methods from machine learning. These methods require large and labeled datasets to train models. To annotate a large-scale image dataset with observed search fixations, we collected 16,184 fixations from people searching for either microwaves or clocks in a dataset of 4,366 images (MS-COCO). We then used this behaviorally-annotated dataset and the machine learning method of Inverse-Reinforcement Learning (IRL) to learn target-specific reward functions and policies for these two target goals. Finally, we used these learned policies to predict the fixations of 60 new behavioral searchers (clock = 30, microwave = 30) in a disjoint test dataset of kitchen scenes depicting both a microwave and a clock (thus controlling for differences in low-level image contrast). We found that the IRL model predicted behavioral search efficiency and fixation-density maps using multiple metrics. Moreover, reward maps from the IRL model revealed target-specific patterns that suggest, not just attention guidance by target features, but also guidance by scene context (e.g., fixations along walls in the search of clocks). Using machine learning and the psychologically-meaningful principle of reward, it is possible to learn the visual features used in goal-directed attention control.