 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertificates without Electrons? Theory and Evidence on Impacts from AI-Driven Power Demand
May 30, 2026Data centers now account for 4.4% of United States electricity demand, yet the grid-level effectiveness of the renewable energy certificates (RECs) and power purchase agreements (PPAs) hyperscalers use to claim carbon neutrality remains unclear. We develop a game-theoretic model in which a data center operator chooses among RECs, PPAs, and behind-the-meter colocation while generators make entry decisions under endogenous financing costs. The model identifies a timing wedge -- the mismatch between consumption and credited renewable generation -- as a central mechanism through which AI demand degrades reliability, raises prices, and increases emissions even when RECs cover 100% of annual consumption. Colocation with storage addresses this wedge directly and induces the greatest renewable entry by eliminating generator revenue risk. We test these predictions by exploiting the staggered release of large language models as a natural experiment, using difference-in-differences on a novel dataset linking AI activity to local grid outcomes. AI demand significantly increases fossil generation, wholesale prices (up to 25% in treated PJM zones), and outage frequency (0.5--1 additional outages per year) near data centers, with impacts scaling in model size. Data centers with on-site generation exhibit a sign reversal in power-quality effects, consistent with the model's prediction that behind-the-meter capacity absorbs demand spikes. Counterfactual analyses show that edge inference, spatial reallocation, and colocated storage each substantially mitigate grid impacts, while REC-only strategies do not. Together, our results demonstrate that the externalities of AI to the grid are tightly coupled to procurement design and the spatial organization of data center infrastructure.
Dual-Foundation Models for Unsupervised Domain Adaptation
May 05, 2026Semantic segmentation provides pixel-level scene understanding essential for autonomous driving and fine-grained perception tasks. However, training segmentation models requires costly, labor-intensive annotations on real-world datasets. Unsupervised Domain Adaptation (UDA) addresses this by training models on labeled synthetic data and adapting them to unlabeled real images. While conceptually simple, adaptation is challenging due to the domain gap, i.e., differences in visual appearance and scene structure between synthetic and real data. Prior approaches bridge this gap through pixel-level mixing or feature-level contrastive learning. Yet, these techniques suffer from two major limitations: (1) reliance on high-confidence pseudo-labels restricts learning to a subset of the target domain, and (2) prototype-based contrastive methods initialize class prototypes from source-trained models, yielding biased and unstable anchors during adaptation. To address these issues, we propose a dual-foundation UDA framework that leverages two complementary foundation models. First, we employ the Segment Anything Model (SAM) with superpixel-guided prompting to enable learning from a broader range of target pixels beyond high-confidence predictions. Second, we incorporate DINOv3 to construct stable, domain-invariant class prototypes through its robust representation learning. Our method achieves consistent improvements of +1.3% and +1.4% mIoU over strong UDA baselines on GTA-to-Cityscapes and SYNTHIA-to-Cityscapes, respectively.
Predicting Visual Attention in Graphic Design Documents
Jul 02, 2024



We present a model for predicting visual attention during the free viewing of graphic design documents. While existing works on this topic have aimed at predicting static saliency of graphic designs, our work is the first attempt to predict both spatial attention and dynamic temporal order in which the document regions are fixated by gaze using a deep learning based model. We propose a two-stage model for predicting dynamic attention on such documents, with webpages being our primary choice of document design for demonstration. In the first stage, we predict the saliency maps for each of the document components (e.g. logos, banners, texts, etc. for webpages) conditioned on the type of document layout. These component saliency maps are then jointly used to predict the overall document saliency. In the second stage, we use these layout-specific component saliency maps as the state representation for an inverse reinforcement learning model of fixation scanpath prediction during document viewing. To test our model, we collected a new dataset consisting of eye movements from 41 people freely viewing 450 webpages (the largest dataset of its kind). Experimental results show that our model outperforms existing models in both saliency and scanpath prediction for webpages, and also generalizes very well to other graphic design documents such as comics, posters, mobile UIs, etc. and natural images.
IrEne: Interpretable Energy Prediction for Transformers
Jun 02, 2021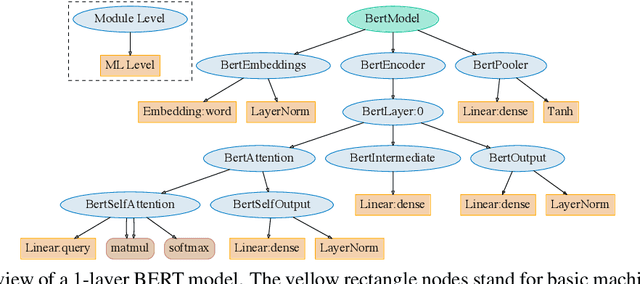

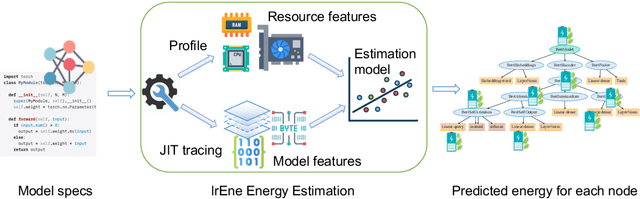
Existing software-based energy measurements of NLP models are not accurate because they do not consider the complex interactions between energy consumption and model execution. We present IrEne, an interpretable and extensible energy prediction system that accurately predicts the inference energy consumption of a wide range of Transformer-based NLP models. IrEne constructs a model tree graph that breaks down the NLP model into modules that are further broken down into low-level machine learning (ML) primitives. IrEne predicts the inference energy consumption of the ML primitives as a function of generalizable features and fine-grained runtime resource usage. IrEne then aggregates these low-level predictions recursively to predict the energy of each module and finally of the entire model. Experiments across multiple Transformer models show IrEne predicts inference energy consumption of transformer models with an error of under 7% compared to the ground truth. In contrast, existing energy models see an error of over 50%. We also show how IrEne can be used to conduct energy bottleneck analysis and to easily evaluate the energy impact of different architectural choices. We release the code and data at https://github.com/StonyBrookNLP/irene.
Bew: Towards Answering Business-Entity-Related Web Questions
Dec 10, 2020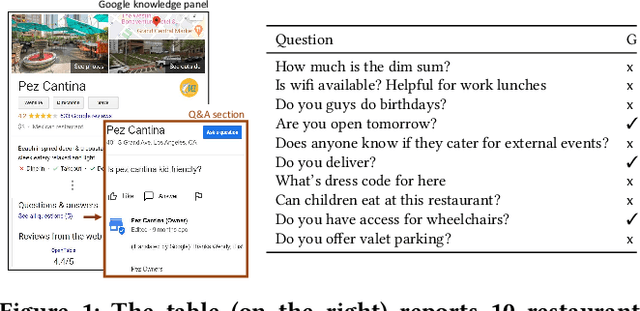
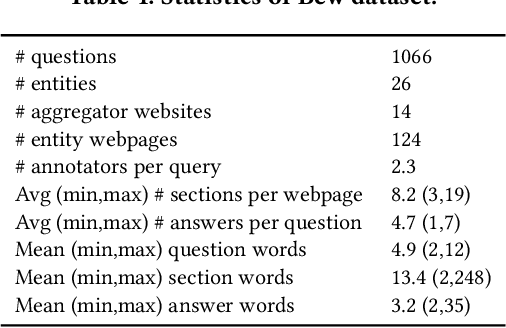

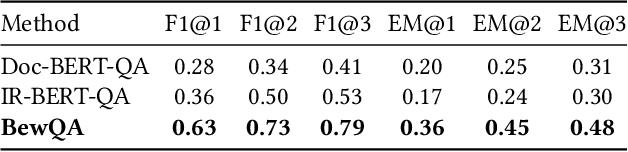
We present BewQA, a system specifically designed to answer a class of questions that we call Bew questions. Bew questions are related to businesses/services such as restaurants, hotels, and movie theaters; for example, "Until what time is happy hour?". These questions are challenging to answer because the answers are found in open-domain Web, are present in short sentences without surrounding context, and are dynamic since the webpage information can be updated frequently. Under these conditions, existing QA systems perform poorly. We present a practical approach, called BewQA, that can answer Bew queries by mining a template of the business-related webpages and using the template to guide the search. We show how we can extract the template automatically by leveraging aggregator websites that aggregate information about business entities in a domain (e.g., restaurants). We answer a given question by identifying the section from the extracted template that is most likely to contain the answer. By doing so we can extract the answers even when the answer span does not have sufficient context. Importantly, BewQA does not require any training. We crowdsource a new dataset of 1066 Bew questions and ground-truth answers in the restaurant domain. Compared to state-of-the-art QA models, BewQA has a 27 percent point improvement in F1 score. Compared to a commercial search engine, BewQA answered correctly 29% more Bew questions.
Towards Accurate and Reliable Energy Measurement of NLP Models
Oct 11, 2020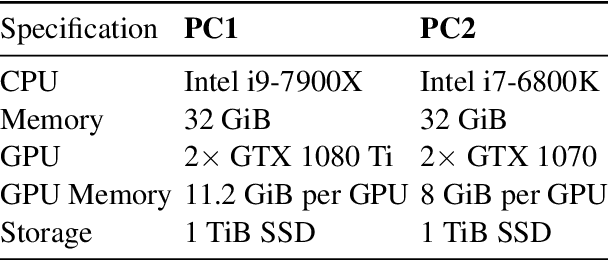
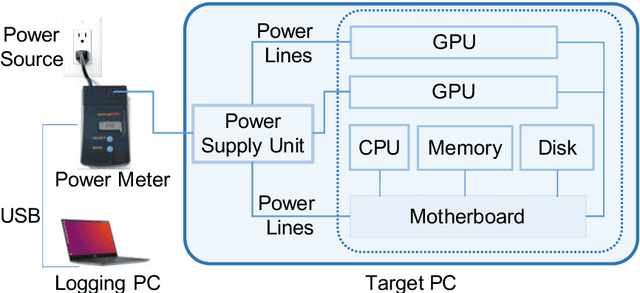
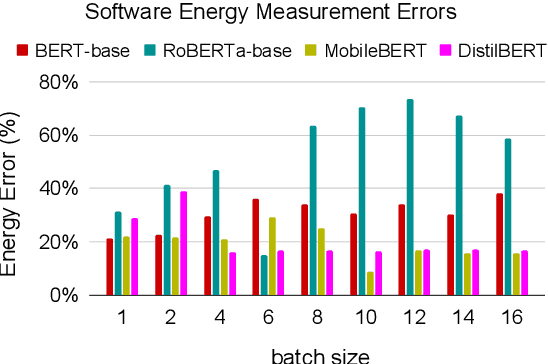
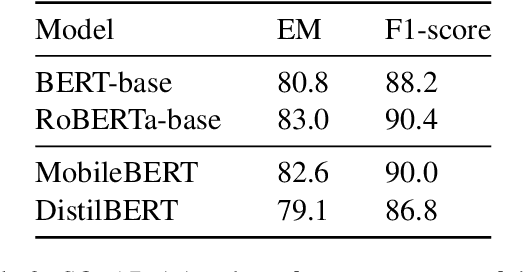
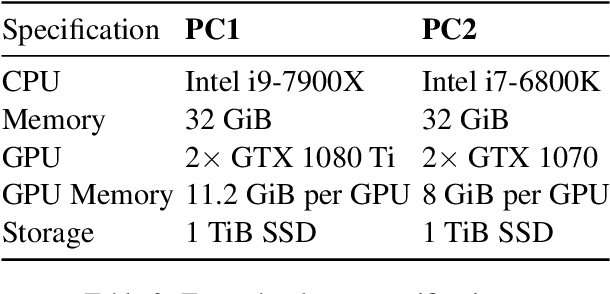
Accurate and reliable measurement of energy consumption is critical for making well-informed design choices when choosing and training large scale NLP models. In this work, we show that existing software-based energy measurements are not accurate because they do not take into account hardware differences and how resource utilization affects energy consumption. We conduct energy measurement experiments with four different models for a question answering task. We quantify the error of existing software-based energy measurements by using a hardware power meter that provides highly accurate energy measurements. Our key takeaway is the need for a more accurate energy estimation model that takes into account hardware variabilities and the non-linear relationship between resource utilization and energy consumption. We release the code and data at https://github.com/csarron/sustainlp2020-energy.
DeFormer: Decomposing Pre-trained Transformers for Faster Question Answering
May 02, 2020



Transformer-based QA models use input-wide self-attention -- i.e. across both the question and the input passage -- at all layers, causing them to be slow and memory-intensive. It turns out that we can get by without input-wide self-attention at all layers, especially in the lower layers. We introduce DeFormer, a decomposed transformer, which substitutes the full self-attention with question-wide and passage-wide self-attentions in the lower layers. This allows for question-independent processing of the input text representations, which in turn enables pre-computing passage representations reducing runtime compute drastically. Furthermore, because DeFormer is largely similar to the original model, we can initialize DeFormer with the pre-training weights of a standard transformer, and directly fine-tune on the target QA dataset. We show DeFormer versions of BERT and XLNet can be used to speed up QA by over 4.3x and with simple distillation-based losses they incur only a 1% drop in accuracy. We open source the code at https://github.com/StonyBrookNLP/deformer.
MobiRNN: Efficient Recurrent Neural Network Execution on Mobile GPU
Jun 03, 2017

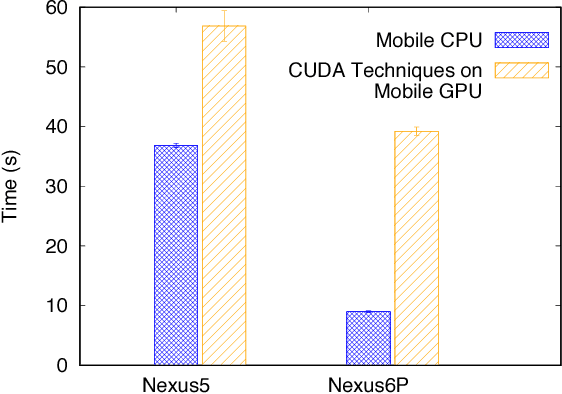

In this paper, we explore optimizations to run Recurrent Neural Network (RNN) models locally on mobile devices. RNN models are widely used for Natural Language Processing, Machine Translation, and other tasks. However, existing mobile applications that use RNN models do so on the cloud. To address privacy and efficiency concerns, we show how RNN models can be run locally on mobile devices. Existing work on porting deep learning models to mobile devices focus on Convolution Neural Networks (CNNs) and cannot be applied directly to RNN models. In response, we present MobiRNN, a mobile-specific optimization framework that implements GPU offloading specifically for mobile GPUs. Evaluations using an RNN model for activity recognition shows that MobiRNN does significantly decrease the latency of running RNN models on phones.