 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching and Evaluating LLMs to Reason About Polymer Design Related Tasks
Jan 22, 2026Research in AI4Science has shown promise in many science applications, including polymer design. However, current LLMs prove ineffective on this problem space because: (i) most models lack polymer-specific knowledge (ii) existing aligned models lack coverage of knowledge and capabilities relevant to polymer design. Addressing this, we introduce PolyBench, a large scale training and test benchmark dataset of more than 125K polymer design related tasks, leveraging a knowledge base of 13M+ data points obtained from experimental and synthetic sources to ensure broad coverage of polymers and their properties. For effective alignment using PolyBench, we introduce a knowledge-augmented reasoning distillation method that augments this dataset with structured CoT. Furthermore, tasks in PolyBench are organized from simple to complex analytical reasoning problems, enabling generalization tests and diagnostic probes across the problem space. Experiments show that small language models (SLMs), of 7B to 14B parameters, trained on PolyBench data outperform similar sized models, and even closed source frontier LLMs on PolyBench test dataset while demonstrating gains on other polymer benchmarks as well.
Causal Graph based Event Reasoning using Semantic Relation Experts
Jun 07, 2025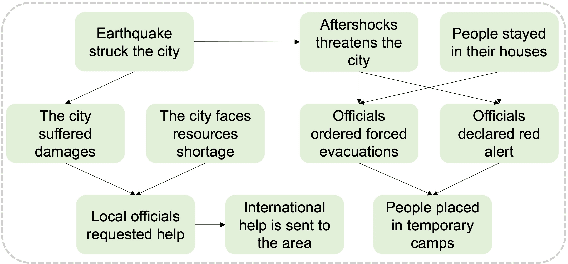
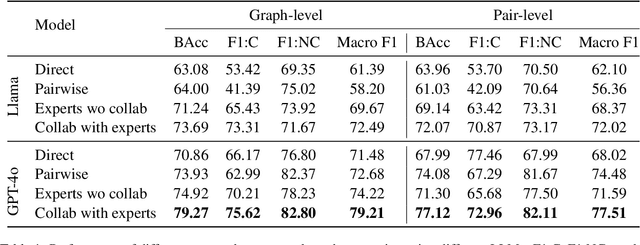
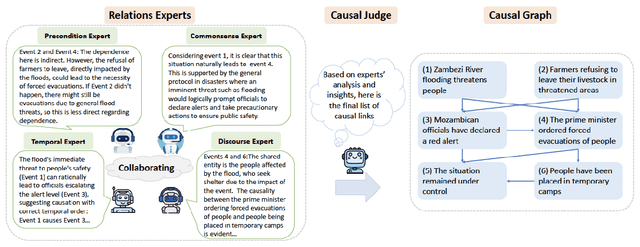
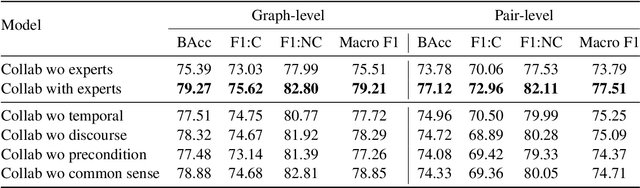
Understanding how events in a scenario causally connect with each other is important for effectively modeling and reasoning about events. But event reasoning remains a difficult challenge, and despite recent advances, Large Language Models (LLMs) still struggle to accurately identify causal connections between events. This struggle leads to poor performance on deeper reasoning tasks like event forecasting and timeline understanding. To address this challenge, we investigate the generation of causal event graphs (e.g., A enables B) as a parallel mechanism to help LLMs explicitly represent causality during inference. This paper evaluates both how to generate correct graphs as well as how graphs can assist reasoning. We propose a collaborative approach to causal graph generation where we use LLMs to simulate experts that focus on specific semantic relations. The experts engage in multiple rounds of discussions which are then consolidated by a final expert. Then, to demonstrate the utility of causal graphs, we use them on multiple downstream applications, and also introduce a new explainable event prediction task that requires a causal chain of events in the explanation. These explanations are more informative and coherent than baseline generations. Finally, our overall approach not finetuned on any downstream task, achieves competitive results with state-of-the-art models on both forecasting and next event prediction tasks.
MuSciClaims: Multimodal Scientific Claim Verification
Jun 05, 2025Assessing scientific claims requires identifying, extracting, and reasoning with multimodal data expressed in information-rich figures in scientific literature. Despite the large body of work in scientific QA, figure captioning, and other multimodal reasoning tasks over chart-based data, there are no readily usable multimodal benchmarks that directly test claim verification abilities. To remedy this gap, we introduce a new benchmark MuSciClaims accompanied by diagnostics tasks. We automatically extract supported claims from scientific articles, which we manually perturb to produce contradicted claims. The perturbations are designed to test for a specific set of claim verification capabilities. We also introduce a suite of diagnostic tasks that help understand model failures. Our results show most vision-language models are poor (~0.3-0.5 F1), with even the best model only achieving 0.77 F1. They are also biased towards judging claims as supported, likely misunderstanding nuanced perturbations within the claims. Our diagnostics show models are bad at localizing correct evidence within figures, struggle with aggregating information across modalities, and often fail to understand basic components of the figure.
$\texttt{DIAMONDs}$: A Dataset for $\mathbb{D}$ynamic $\mathbb{I}$nformation $\mathbb{A}$nd $\mathbb{M}$ental modeling $\mathbb{O}$f $\mathbb{N}$umeric $\mathbb{D}$iscussions
May 19, 2025Understanding multiparty conversations demands robust Theory of Mind (ToM) capabilities, including the ability to track dynamic information, manage knowledge asymmetries, and distinguish relevant information across extended exchanges. To advance ToM evaluation in such settings, we present a carefully designed scalable methodology for generating high-quality benchmark conversation-question pairs with these characteristics. Using this methodology, we create $\texttt{DIAMONDs}$, a new conversational QA dataset covering common business, financial or other group interactions. In these goal-oriented conversations, participants often have to track certain numerical quantities (say $\textit{expected profit}$) of interest that can be derived from other variable quantities (like $\textit{marketing expenses, expected sales, salary}$, etc.), whose values also change over the course of the conversation. $\texttt{DIAMONDs}$ questions pose simple numerical reasoning problems over such quantities of interest (e.g., $\textit{funds required for charity events, expected company profit next quarter}$, etc.) in the context of the information exchanged in conversations. This allows for precisely evaluating ToM capabilities for carefully tracking and reasoning over participants' knowledge states. Our evaluation of state-of-the-art language models reveals significant challenges in handling participant-centric reasoning, specifically in situations where participants have false beliefs. Models also struggle with conversations containing distractors and show limited ability to identify scenarios with insufficient information. These findings highlight current models' ToM limitations in handling real-world multi-party conversations.
Does RoBERTa Perform Better than BERT in Continual Learning: An Attention Sink Perspective
Oct 08, 2024
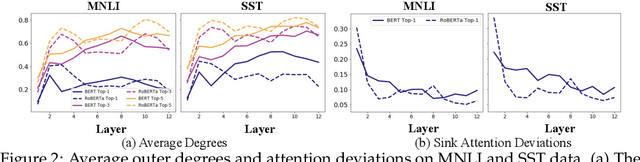


Continual learning (CL) aims to train models that can sequentially learn new tasks without forgetting previous tasks' knowledge. Although previous works observed that pre-training can benefit CL, it remains unclear whether a pre-trained model with higher downstream capacity also performs better in CL. In this paper, we observe that pre-trained models may allocate high attention scores to some 'sink' tokens, such as [SEP] tokens, which are ubiquitous across various tasks. Such attention sinks may lead to models' over-smoothing in single-task learning and interference in sequential tasks' learning, which may compromise the models' CL performance despite their high pre-trained capabilities. To reduce these effects, we propose a pre-scaling mechanism that encourages attention diversity across all tokens. Specifically, it first scales the task's attention to the non-sink tokens in a probing stage, and then fine-tunes the model with scaling. Experiments show that pre-scaling yields substantial improvements in CL without experience replay, or progressively storing parameters from previous tasks.
Look Hear: Gaze Prediction for Speech-directed Human Attention
Jul 28, 2024
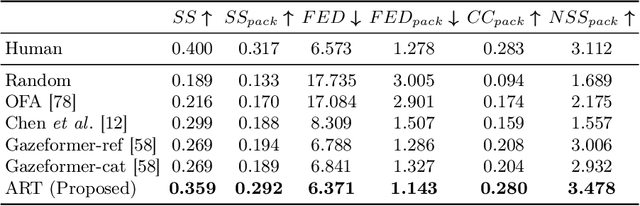

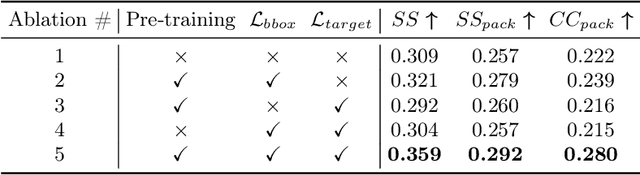
For computer systems to effectively interact with humans using spoken language, they need to understand how the words being generated affect the users' moment-by-moment attention. Our study focuses on the incremental prediction of attention as a person is seeing an image and hearing a referring expression defining the object in the scene that should be fixated by gaze. To predict the gaze scanpaths in this incremental object referral task, we developed the Attention in Referral Transformer model or ART, which predicts the human fixations spurred by each word in a referring expression. ART uses a multimodal transformer encoder to jointly learn gaze behavior and its underlying grounding tasks, and an autoregressive transformer decoder to predict, for each word, a variable number of fixations based on fixation history. To train ART, we created RefCOCO-Gaze, a large-scale dataset of 19,738 human gaze scanpaths, corresponding to 2,094 unique image-expression pairs, from 220 participants performing our referral task. In our quantitative and qualitative analyses, ART not only outperforms existing methods in scanpath prediction, but also appears to capture several human attention patterns, such as waiting, scanning, and verification.
AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents
Jul 26, 2024



Autonomous agents that address day-to-day digital tasks (e.g., ordering groceries for a household), must not only operate multiple apps (e.g., notes, messaging, shopping app) via APIs, but also generate rich code with complex control flow in an iterative manner based on their interaction with the environment. However, existing benchmarks for tool use are inadequate, as they only cover tasks that require a simple sequence of API calls. To remedy this gap, we built $\textbf{AppWorld Engine}$, a high-quality execution environment (60K lines of code) of 9 day-to-day apps operable via 457 APIs and populated with realistic digital activities simulating the lives of ~100 fictitious users. We then created $\textbf{AppWorld Benchmark}$ (40K lines of code), a suite of 750 natural, diverse, and challenging autonomous agent tasks requiring rich and interactive code generation. It supports robust programmatic evaluation with state-based unit tests, allowing for different ways of completing a task while also checking for unexpected changes, i.e., collateral damage. The state-of-the-art LLM, GPT-4o, solves only ~49% of our 'normal' tasks and ~30% of 'challenge' tasks, while other models solve at least 16% fewer. This highlights the benchmark's difficulty and AppWorld's potential to push the frontiers of interactive coding agents. The project website is available at https://appworld.dev/.
On Initializing Transformers with Pre-trained Embeddings
Jul 17, 2024It has become common practice now to use random initialization schemes, rather than the pre-trained embeddings, when training transformer based models from scratch. Indeed, we find that pre-trained word embeddings from GloVe, and some sub-word embeddings extracted from language models such as T5 and mT5 fare much worse compared to random initialization. This is counter-intuitive given the well-known representational and transfer-learning advantages of pre-training. Interestingly, we also find that BERT and mBERT embeddings fare better than random initialization, showing the advantages of pre-trained representations. In this work, we posit two potential factors that contribute to these mixed results: the model sensitivity to parameter distribution and the embedding interactions with position encodings. We observe that pre-trained GloVe, T5, and mT5 embeddings have a wider distribution of values. As argued in the initialization studies, such large value initializations can lead to poor training because of saturated outputs. Further, the larger embedding values can, in effect, absorb the smaller position encoding values when added together, thus losing position information. Standardizing the pre-trained embeddings to a narrow range (e.g. as prescribed by Xavier) leads to substantial gains for Glove, T5, and mT5 embeddings. On the other hand, BERT pre-trained embeddings, while larger, are still relatively closer to Xavier initialization range which may allow it to effectively transfer the pre-trained knowledge.
CaT-BENCH: Benchmarking Language Model Understanding of Causal and Temporal Dependencies in Plans
Jun 22, 2024



Understanding the abilities of LLMs to reason about natural language plans, such as instructional text and recipes, is critical to reliably using them in decision-making systems. A fundamental aspect of plans is the temporal order in which their steps needs to be executed, which reflects the underlying causal dependencies between them. We introduce CaT-Bench, a benchmark of Step Order Prediction questions, which test whether a step must necessarily occur before or after another in cooking recipe plans. We use this to evaluate how well frontier LLMs understand causal and temporal dependencies. We find that SOTA LLMs are underwhelming (best zero-shot is only 0.59 in F1), and are biased towards predicting dependence more often, perhaps relying on temporal order of steps as a heuristic. While prompting for explanations and using few-shot examples improve performance, the best F1 result is only 0.73. Further, human evaluation of explanations along with answer correctness show that, on average, humans do not agree with model reasoning. Surprisingly, we also find that explaining after answering leads to better performance than normal chain-of-thought prompting, and LLM answers are not consistent across questions about the same step pairs. Overall, results show that LLMs' ability to detect dependence between steps has significant room for improvement.
Comparing Human-Centered Language Modeling: Is it Better to Model Groups, Individual Traits, or Both?
Jan 23, 2024



Natural language processing has made progress in incorporating human context into its models, but whether it is more effective to use group-wise attributes (e.g., over-45-year-olds) or model individuals remains open. Group attributes are technically easier but coarse: not all 45-year-olds write the same way. In contrast, modeling individuals captures the complexity of each person's identity. It allows for a more personalized representation, but we may have to model an infinite number of users and require data that may be impossible to get. We compare modeling human context via group attributes, individual users, and combined approaches. Combining group and individual features significantly benefits user-level regression tasks like age estimation or personality assessment from a user's documents. Modeling individual users significantly improves the performance of single document-level classification tasks like stance and topic detection. We also find that individual-user modeling does well even without user's historical data.