 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAGA: A Participant-specific Examination of Story Alternatives and Goal Applicability for a Deeper Understanding of Complex Events
Aug 11, 2024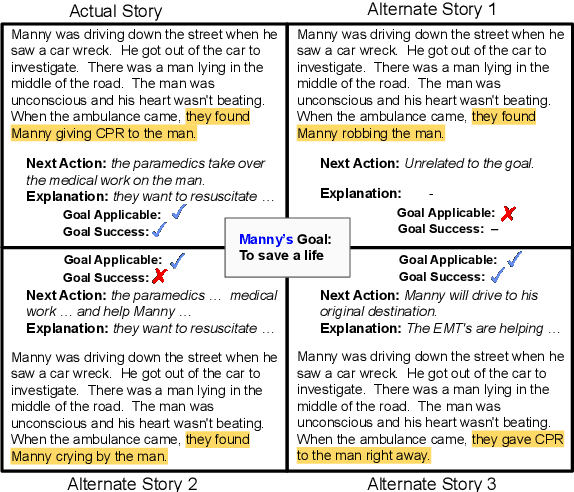

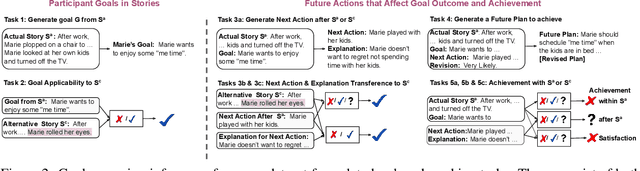
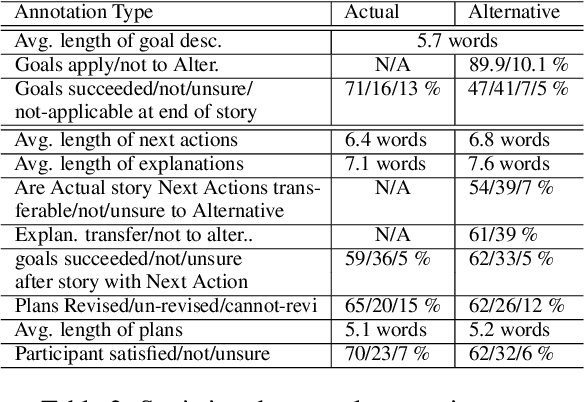
Interpreting and assessing goal driven actions is vital to understanding and reasoning over complex events. It is important to be able to acquire the knowledge needed for this understanding, though doing so is challenging. We argue that such knowledge can be elicited through a participant achievement lens. We analyze a complex event in a narrative according to the intended achievements of the participants in that narrative, the likely future actions of the participants, and the likelihood of goal success. We collect 6.3K high quality goal and action annotations reflecting our proposed participant achievement lens, with an average weighted Fleiss-Kappa IAA of 80%. Our collection contains annotated alternate versions of each narrative. These alternate versions vary minimally from the "original" story, but can license drastically different inferences. Our findings suggest that while modern large language models can reflect some of the goal-based knowledge we study, they find it challenging to fully capture the design and intent behind concerted actions, even when the model pretraining included the data from which we extracted the goal knowledge. We show that smaller models fine-tuned on our dataset can achieve performance surpassing larger models.
UMBCLU at SemEval-2024 Task 1A and 1C: Semantic Textual Relatedness with and without machine translation
Feb 20, 2024This paper describes the system we developed for SemEval-2024 Task 1, "Semantic Textual Relatedness for African and Asian Languages." The aim of the task is to build a model that can identify semantic textual relatedness (STR) between two sentences of a target language belonging to a collection of African and Asian languages. We participated in Subtasks A and C and explored supervised and cross-lingual training leveraging large language models (LLMs). Pre-trained large language models have been extensively used for machine translation and semantic similarity. Using a combination of machine translation and sentence embedding LLMs, we developed a unified STR model, TranSem, for subtask A and fine-tuned the T5 family of models on the STR data, FineSem, for use in subtask C. Our model results for 7 languages in subtask A were better than the official baseline for 3 languages and on par with the baseline for the remaining 4 languages. Our model results for the 12 languages in subtask C resulted in 1st place for Africaans, 2nd place for Indonesian, and 3rd place for English with low performance for the remaining 9 languages.
POQue: Asking Participant-specific Outcome Questions for a Deeper Understanding of Complex Events
Dec 05, 2022



Knowledge about outcomes is critical for complex event understanding but is hard to acquire. We show that by pre-identifying a participant in a complex event, crowd workers are able to (1) infer the collective impact of salient events that make up the situation, (2) annotate the volitional engagement of participants in causing the situation, and (3) ground the outcome of the situation in state changes of the participants. By creating a multi-step interface and a careful quality control strategy, we collect a high quality annotated dataset of 8K short newswire narratives and ROCStories with high inter-annotator agreement (0.74-0.96 weighted Fleiss Kappa). Our dataset, POQue (Participant Outcome Questions), enables the exploration and development of models that address multiple aspects of semantic understanding. Experimentally, we show that current language models lag behind human performance in subtle ways through our task formulations that target abstract and specific comprehension of a complex event, its outcome, and a participant's influence over the event culmination.