 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\texttt{DIAMONDs}$: A Dataset for $\mathbb{D}$ynamic $\mathbb{I}$nformation $\mathbb{A}$nd $\mathbb{M}$ental modeling $\mathbb{O}$f $\mathbb{N}$umeric $\mathbb{D}$iscussions
May 19, 2025Understanding multiparty conversations demands robust Theory of Mind (ToM) capabilities, including the ability to track dynamic information, manage knowledge asymmetries, and distinguish relevant information across extended exchanges. To advance ToM evaluation in such settings, we present a carefully designed scalable methodology for generating high-quality benchmark conversation-question pairs with these characteristics. Using this methodology, we create $\texttt{DIAMONDs}$, a new conversational QA dataset covering common business, financial or other group interactions. In these goal-oriented conversations, participants often have to track certain numerical quantities (say $\textit{expected profit}$) of interest that can be derived from other variable quantities (like $\textit{marketing expenses, expected sales, salary}$, etc.), whose values also change over the course of the conversation. $\texttt{DIAMONDs}$ questions pose simple numerical reasoning problems over such quantities of interest (e.g., $\textit{funds required for charity events, expected company profit next quarter}$, etc.) in the context of the information exchanged in conversations. This allows for precisely evaluating ToM capabilities for carefully tracking and reasoning over participants' knowledge states. Our evaluation of state-of-the-art language models reveals significant challenges in handling participant-centric reasoning, specifically in situations where participants have false beliefs. Models also struggle with conversations containing distractors and show limited ability to identify scenarios with insufficient information. These findings highlight current models' ToM limitations in handling real-world multi-party conversations.
SandboxAQ's submission to MRL 2024 Shared Task on Multi-lingual Multi-task Information Retrieval
Oct 28, 2024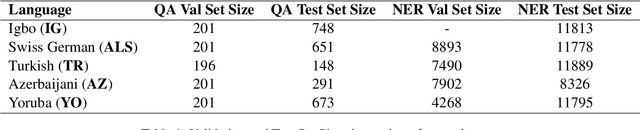
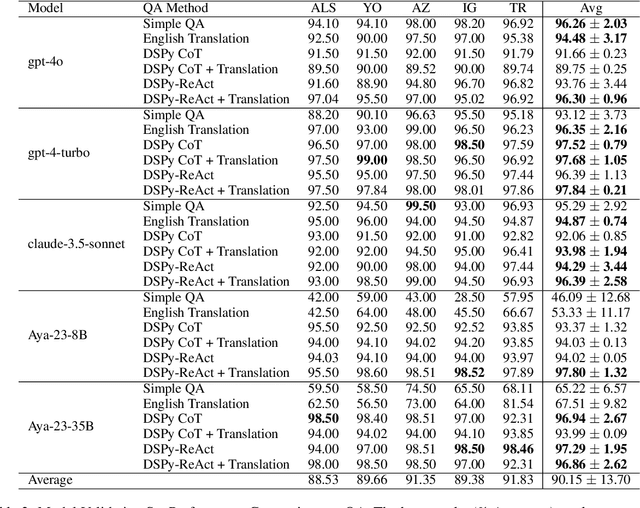
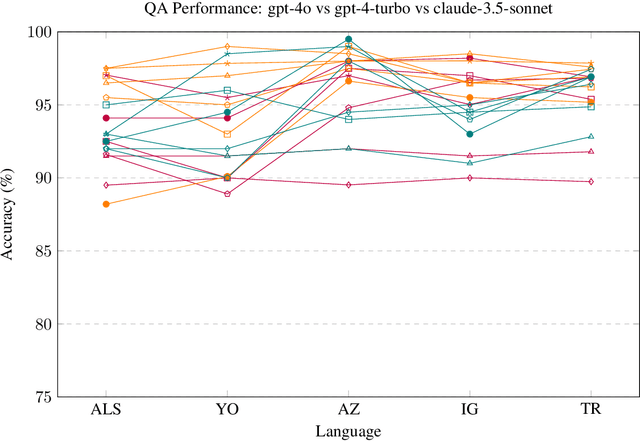
This paper explores the problems of Question Answering (QA) and Named Entity Recognition (NER) in five diverse languages. We tested five Large Language Models with various prompting methods, including zero-shot, chain-of-thought reasoning, and translation techniques. Our results show that while some models consistently outperform others, their effectiveness varies significantly across tasks and languages. We saw that advanced prompting techniques generally improved QA performance but had mixed results for NER; and we observed that language difficulty patterns differed between tasks. Our findings highlight the need for task-specific approaches in multilingual NLP and suggest that current models may develop different linguistic competencies for different tasks.
POQue: Asking Participant-specific Outcome Questions for a Deeper Understanding of Complex Events
Dec 05, 2022



Knowledge about outcomes is critical for complex event understanding but is hard to acquire. We show that by pre-identifying a participant in a complex event, crowd workers are able to (1) infer the collective impact of salient events that make up the situation, (2) annotate the volitional engagement of participants in causing the situation, and (3) ground the outcome of the situation in state changes of the participants. By creating a multi-step interface and a careful quality control strategy, we collect a high quality annotated dataset of 8K short newswire narratives and ROCStories with high inter-annotator agreement (0.74-0.96 weighted Fleiss Kappa). Our dataset, POQue (Participant Outcome Questions), enables the exploration and development of models that address multiple aspects of semantic understanding. Experimentally, we show that current language models lag behind human performance in subtle ways through our task formulations that target abstract and specific comprehension of a complex event, its outcome, and a participant's influence over the event culmination.
Distilling Knowledge from Language Models for Video-based Action Anticipation
Oct 12, 2022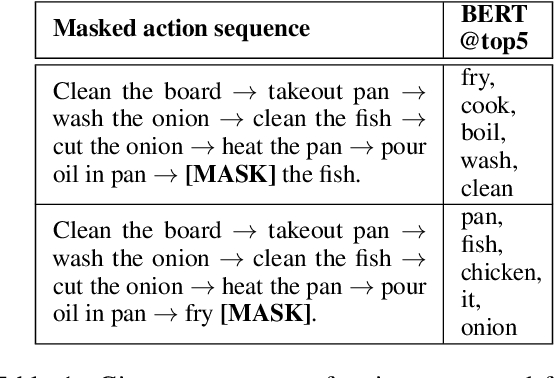
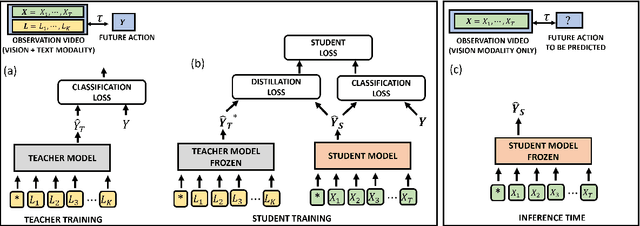

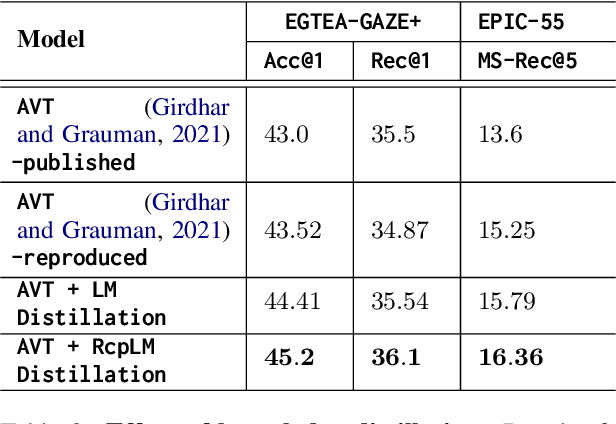
Anticipating future actions in a video is useful for many autonomous and assistive technologies. Prior action anticipation work mostly treats this as a vision modality problem, where the models learn the task information primarily from the video features in the target action anticipation datasets. In this work, we propose a method to make use of the text-modality that is available during the training, to bring in complementary information that is not present in the target action anticipation datasets. In particular, we leverage pre-trained language models to build a text-modality teacher that is able to predict future actions based on text labels of the past actions extracted from the input video. To further adapt the teacher to the target domain (cooking), we also pretrain the teacher on textual instructions from a recipes dataset (Recipe1M). Then, we distill the knowledge gained by the text-modality teacher into a vision-modality student to further improve it's performance. We empirically evaluate this simple cross-modal distillation strategy on two video datasets EGTEA-GAZE+ and EPIC-KITCHEN 55. Distilling this text-modality knowledge into a strong vision model (Anticipative Vision Transformer) yields consistent gains across both datasets, 3.5% relative improvement on top1 class mean recall for EGTEA-GAZE+, 7.2% on top5 many-shot class mean recall for EPIC-KITCHEN 55 and achieves new state-of-the-results.
PASTA: A Dataset for Modeling Participant States in Narratives
Jul 31, 2022
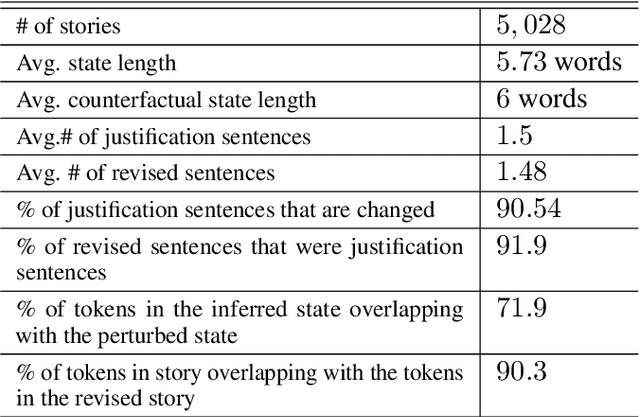
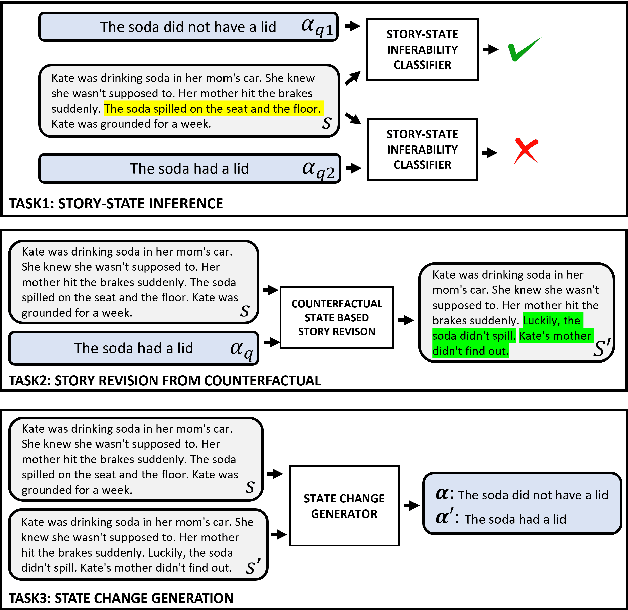
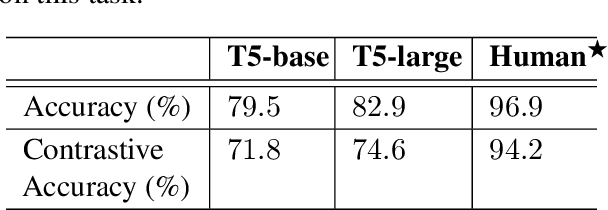
The events in a narrative can be understood as a coherent whole via the underlying states of its participants. Often, these participant states are not explicitly mentioned in the narrative, left to be filled in via common-sense or inference. A model that understands narratives should be able to infer these implicit participant states and reason about the impact of changes to these states on the narrative. To facilitate this goal, we introduce a new crowdsourced Participants States dataset, PASTA. This dataset contains valid, inferable participant states; a counterfactual perturbation to the state; and the changes to the story that would be necessary if the counterfactual was true. We introduce three state-based reasoning tasks that test for the ability to infer when a state is entailed by a story, revise a story for a counterfactual state, and to explain the most likely state change given a revised story. Our benchmarking experiments show that while today's LLMs are able to reason about states to some degree, there is a large room for improvement, suggesting potential avenues for future research.