 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Graph based Event Reasoning using Semantic Relation Experts
Jun 07, 2025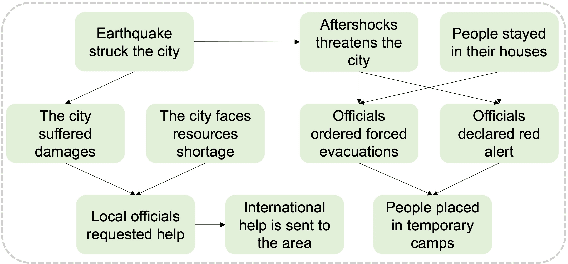
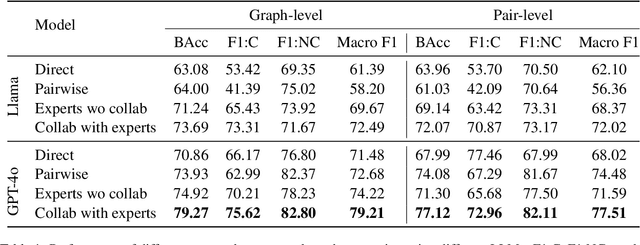
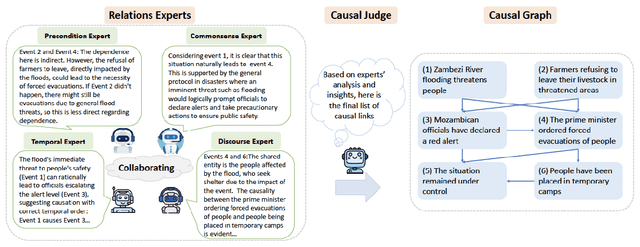
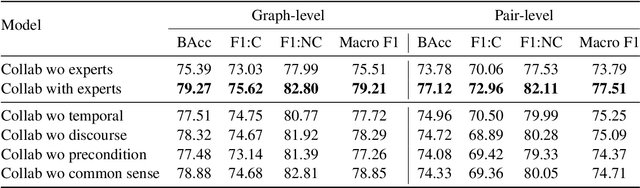
Understanding how events in a scenario causally connect with each other is important for effectively modeling and reasoning about events. But event reasoning remains a difficult challenge, and despite recent advances, Large Language Models (LLMs) still struggle to accurately identify causal connections between events. This struggle leads to poor performance on deeper reasoning tasks like event forecasting and timeline understanding. To address this challenge, we investigate the generation of causal event graphs (e.g., A enables B) as a parallel mechanism to help LLMs explicitly represent causality during inference. This paper evaluates both how to generate correct graphs as well as how graphs can assist reasoning. We propose a collaborative approach to causal graph generation where we use LLMs to simulate experts that focus on specific semantic relations. The experts engage in multiple rounds of discussions which are then consolidated by a final expert. Then, to demonstrate the utility of causal graphs, we use them on multiple downstream applications, and also introduce a new explainable event prediction task that requires a causal chain of events in the explanation. These explanations are more informative and coherent than baseline generations. Finally, our overall approach not finetuned on any downstream task, achieves competitive results with state-of-the-art models on both forecasting and next event prediction tasks.
CaT-BENCH: Benchmarking Language Model Understanding of Causal and Temporal Dependencies in Plans
Jun 22, 2024



Understanding the abilities of LLMs to reason about natural language plans, such as instructional text and recipes, is critical to reliably using them in decision-making systems. A fundamental aspect of plans is the temporal order in which their steps needs to be executed, which reflects the underlying causal dependencies between them. We introduce CaT-Bench, a benchmark of Step Order Prediction questions, which test whether a step must necessarily occur before or after another in cooking recipe plans. We use this to evaluate how well frontier LLMs understand causal and temporal dependencies. We find that SOTA LLMs are underwhelming (best zero-shot is only 0.59 in F1), and are biased towards predicting dependence more often, perhaps relying on temporal order of steps as a heuristic. While prompting for explanations and using few-shot examples improve performance, the best F1 result is only 0.73. Further, human evaluation of explanations along with answer correctness show that, on average, humans do not agree with model reasoning. Surprisingly, we also find that explaining after answering leads to better performance than normal chain-of-thought prompting, and LLM answers are not consistent across questions about the same step pairs. Overall, results show that LLMs' ability to detect dependence between steps has significant room for improvement.
Modeling Complex Event Scenarios via Simple Entity-focused Questions
Feb 14, 2023



Event scenarios are often complex and involve multiple event sequences connected through different entity participants. Exploring such complex scenarios requires an ability to branch through different sequences, something that is difficult to achieve with standard event language modeling. To address this, we propose a question-guided generation framework that models events in complex scenarios as answers to questions about participants. At any step in the generation process, the framework uses the previously generated events as context, but generates the next event as an answer to one of three questions: what else a participant did, what else happened to a participant, or what else happened. The participants and the questions themselves can be sampled or be provided as input from a user, allowing for controllable exploration. Our empirical evaluation shows that this question-guided generation provides better coverage of participants, diverse events within a domain, comparable perplexities for modeling event sequences, and more effective control for interactive schema generation.
PASTA: A Dataset for Modeling Participant States in Narratives
Jul 31, 2022
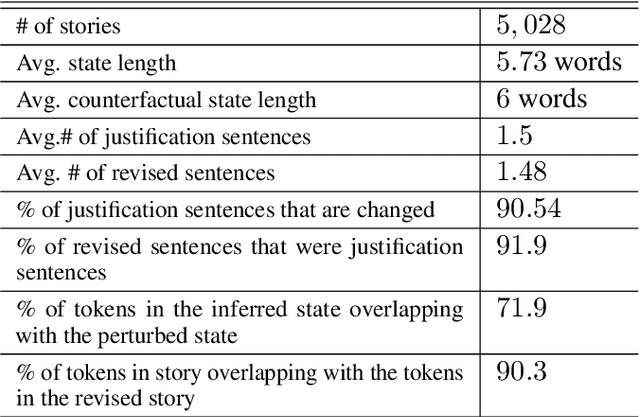
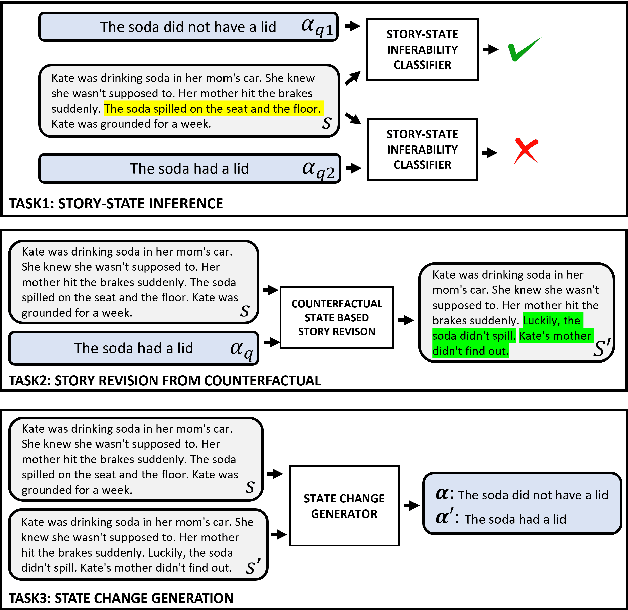
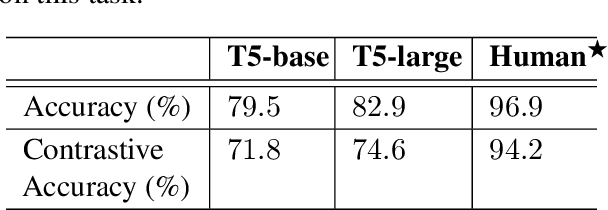
The events in a narrative can be understood as a coherent whole via the underlying states of its participants. Often, these participant states are not explicitly mentioned in the narrative, left to be filled in via common-sense or inference. A model that understands narratives should be able to infer these implicit participant states and reason about the impact of changes to these states on the narrative. To facilitate this goal, we introduce a new crowdsourced Participants States dataset, PASTA. This dataset contains valid, inferable participant states; a counterfactual perturbation to the state; and the changes to the story that would be necessary if the counterfactual was true. We introduce three state-based reasoning tasks that test for the ability to infer when a state is entailed by a story, revise a story for a counterfactual state, and to explain the most likely state change given a revised story. Our benchmarking experiments show that while today's LLMs are able to reason about states to some degree, there is a large room for improvement, suggesting potential avenues for future research.
Toward Diverse Precondition Generation
Jun 14, 2021
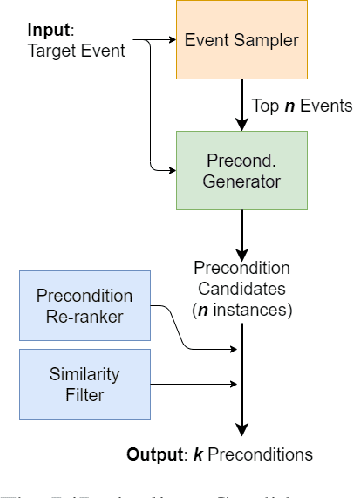

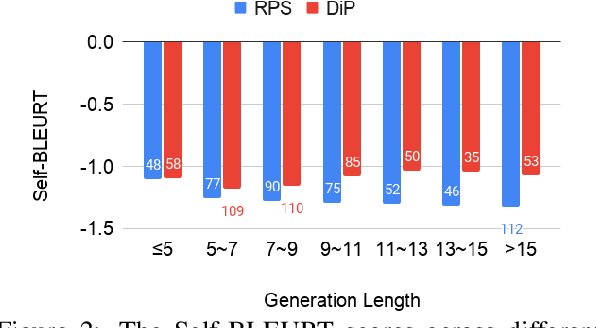
Language understanding must identify the logical connections between events in a discourse, but core events are often unstated due to their commonsense nature. This paper fills in these missing events by generating precondition events. Precondition generation can be framed as a sequence-to-sequence problem: given a target event, generate a possible precondition. However, in most real-world scenarios, an event can have several preconditions, requiring diverse generation -- a challenge for standard seq2seq approaches. We propose DiP, a Diverse Precondition generation system that can generate unique and diverse preconditions. DiP uses a generative process with three components -- an event sampler, a candidate generator, and a post-processor. The event sampler provides control codes (precondition triggers) which the candidate generator uses to focus its generation. Unlike other conditional generation systems, DiP automatically generates control codes without training on diverse examples. Analysis against baselines reveals that DiP improves the diversity of preconditions significantly while also generating more preconditions.
TellMeWhy: A Dataset for Answering Why-Questions in Narratives
Jun 11, 2021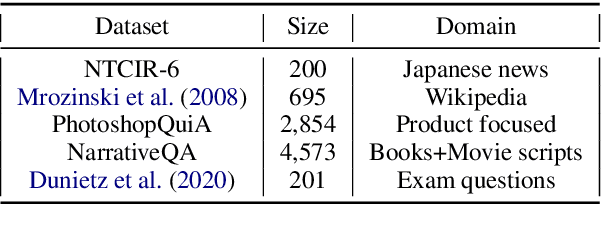

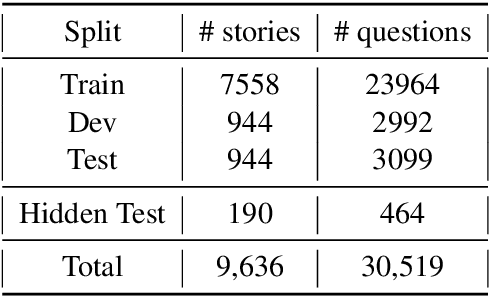
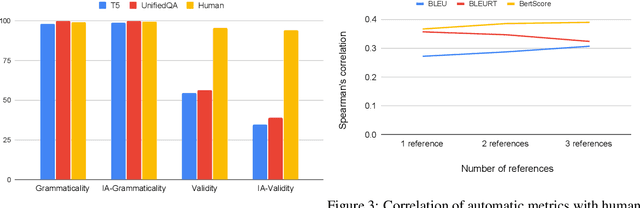
Answering questions about why characters perform certain actions is central to understanding and reasoning about narratives. Despite recent progress in QA, it is not clear if existing models have the ability to answer "why" questions that may require commonsense knowledge external to the input narrative. In this work, we introduce TellMeWhy, a new crowd-sourced dataset that consists of more than 30k questions and free-form answers concerning why characters in short narratives perform the actions described. For a third of this dataset, the answers are not present within the narrative. Given the limitations of automated evaluation for this task, we also present a systematized human evaluation interface for this dataset. Our evaluation of state-of-the-art models show that they are far below human performance on answering such questions. They are especially worse on questions whose answers are external to the narrative, thus providing a challenge for future QA and narrative understanding research.
Conditional Generation of Temporally-ordered Event Sequences
Dec 31, 2020
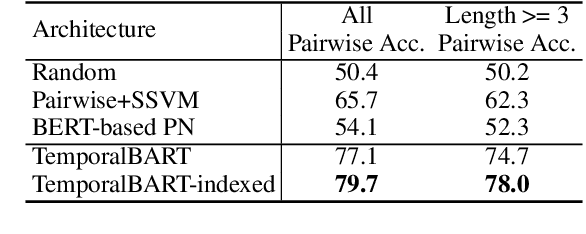
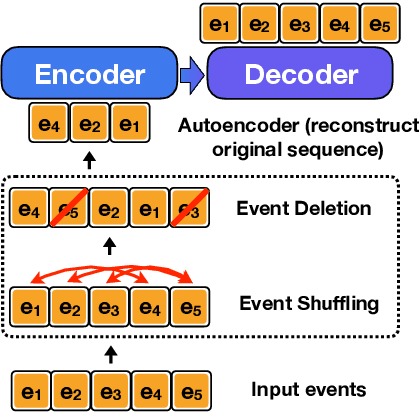

Models encapsulating narrative schema knowledge have proven to be useful for a range of event-related tasks, but these models typically do not engage with temporal relationships between events. We present a a BART-based conditional generation model capable of capturing event cooccurrence as well as temporality of event sequences. This single model can address both temporal ordering, sorting a given sequence of events into the order they occurred, and event infilling, predicting new events which fit into a temporally-ordered sequence of existing ones. Our model is trained as a denoising autoencoder: we take temporally-ordered event sequences, shuffle them, delete some events, and then attempting to recover the original event sequence. In this fashion, the model learns to make inferences given incomplete knowledge about the events in an underlying scenario. On the temporal ordering task, we show that our model is able to unscramble event sequences from existing datasets without access to explicitly labeled temporal training data, outperforming both a BERT-based pairwise model and a BERT-based pointer network. On event infilling, human evaluation shows that our model is able to generate events that fit better temporally into the input events when compared to GPT-2 story completion models.
Modeling Preconditions in Text with a Crowd-sourced Dataset
Oct 14, 2020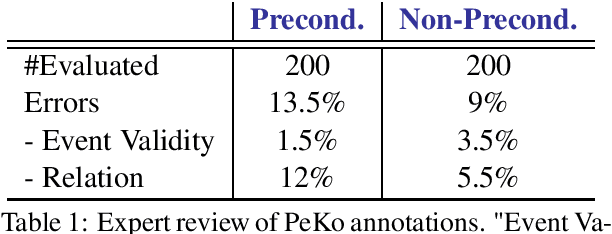

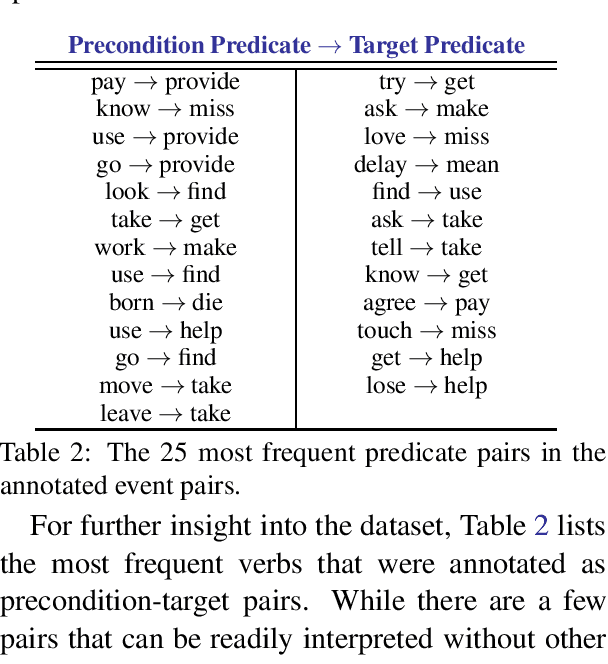
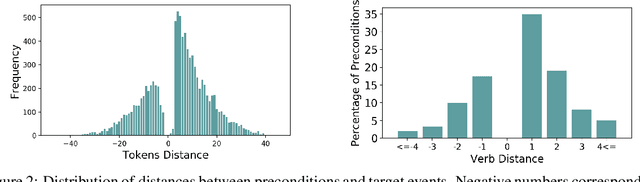
Preconditions provide a form of logical connection between events that explains why some events occur together and information that is complementary to the more widely studied relations such as causation, temporal ordering, entailment, and discourse relations. Modeling preconditions in text has been hampered in part due to the lack of large scale labeled data grounded in text. This paper introduces PeKo, a crowd-sourced annotation of preconditions between event pairs in newswire, an order of magnitude larger than prior text annotations. To complement this new corpus, we also introduce two challenge tasks aimed at modeling preconditions: (i) Precondition Identification -- a standard classification task defined over pairs of event mentions, and (ii) Precondition Generation -- a generative task aimed at testing a more general ability to reason about a given event. Evaluation on both tasks shows that modeling preconditions is challenging even for today's large language models (LM). This suggests that precondition knowledge is not easily accessible in LM-derived representations alone. Our generation results show that fine-tuning an LM on PeKo yields better conditional relations than when trained on raw text or temporally-ordered corpora.
Modeling Label Semantics for Predicting Emotional Reactions
Jun 28, 2020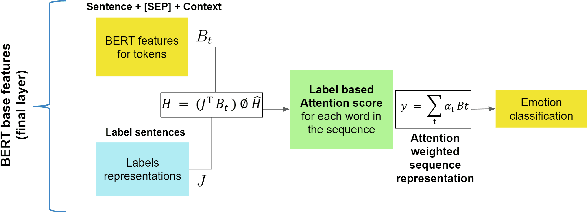
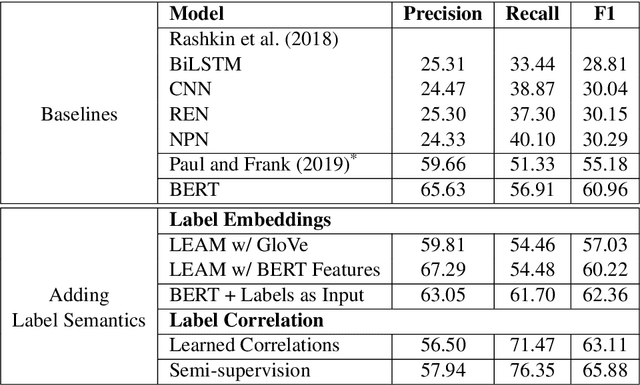
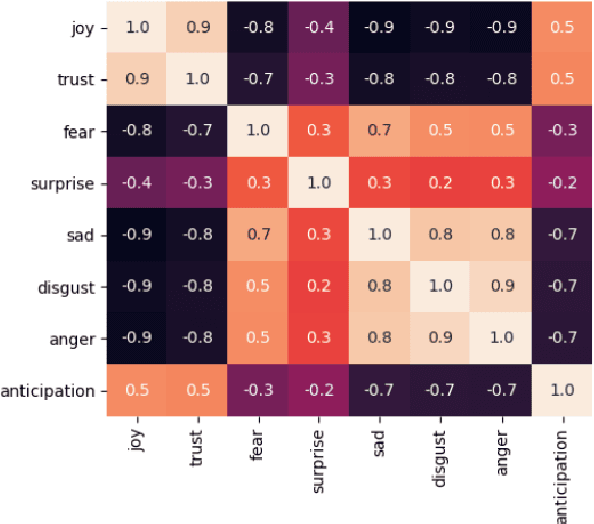
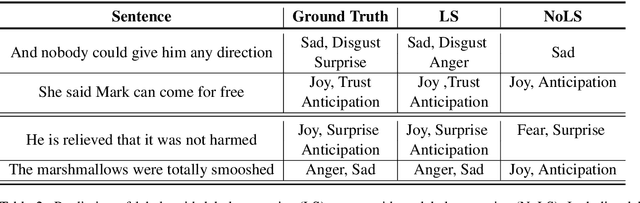
Predicting how events induce emotions in the characters of a story is typically seen as a standard multi-label classification task, which usually treats labels as anonymous classes to predict. They ignore information that may be conveyed by the emotion labels themselves. We propose that the semantics of emotion labels can guide a model's attention when representing the input story. Further, we observe that the emotions evoked by an event are often related: an event that evokes joy is unlikely to also evoke sadness. In this work, we explicitly model label classes via label embeddings, and add mechanisms that track label-label correlations both during training and inference. We also introduce a new semi-supervision strategy that regularizes for the correlations on unlabeled data. Our empirical evaluations show that modeling label semantics yields consistent benefits, and we advance the state-of-the-art on an emotion inference task.
Generating Narrative Text in a Switching Dynamical System
Apr 08, 2020
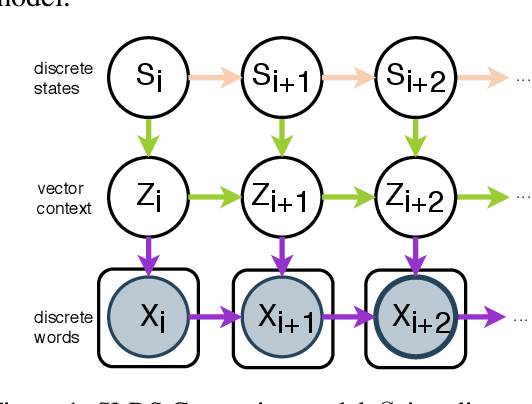
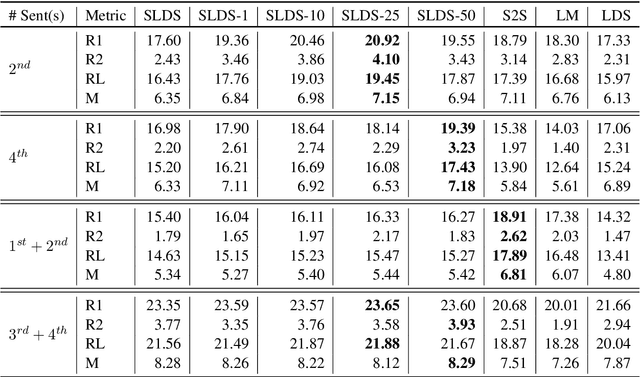
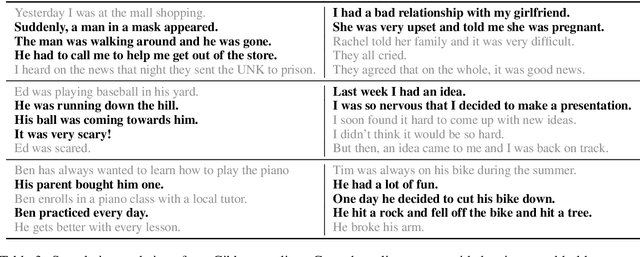
Early work on narrative modeling used explicit plans and goals to generate stories, but the language generation itself was restricted and inflexible. Modern methods use language models for more robust generation, but often lack an explicit representation of the scaffolding and dynamics that guide a coherent narrative. This paper introduces a new model that integrates explicit narrative structure with neural language models, formalizing narrative modeling as a Switching Linear Dynamical System (SLDS). A SLDS is a dynamical system in which the latent dynamics of the system (i.e. how the state vector transforms over time) is controlled by top-level discrete switching variables. The switching variables represent narrative structure (e.g., sentiment or discourse states), while the latent state vector encodes information on the current state of the narrative. This probabilistic formulation allows us to control generation, and can be learned in a semi-supervised fashion using both labeled and unlabeled data. Additionally, we derive a Gibbs sampler for our model that can fill in arbitrary parts of the narrative, guided by the switching variables. Our filled-in (English language) narratives outperform several baselines on both automatic and human evaluations.