 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled coordinates for machine learning-based molecular fragment linking
Nov 01, 2021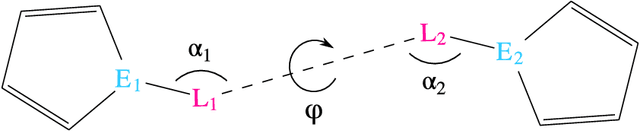
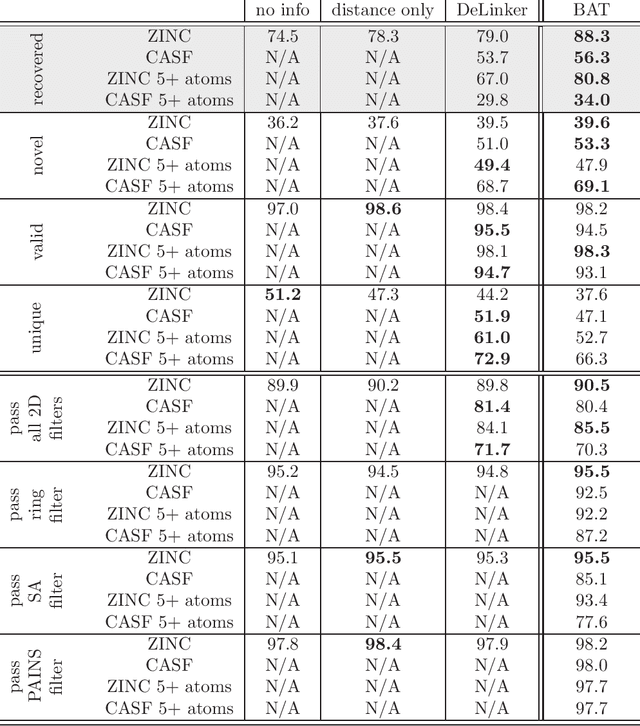
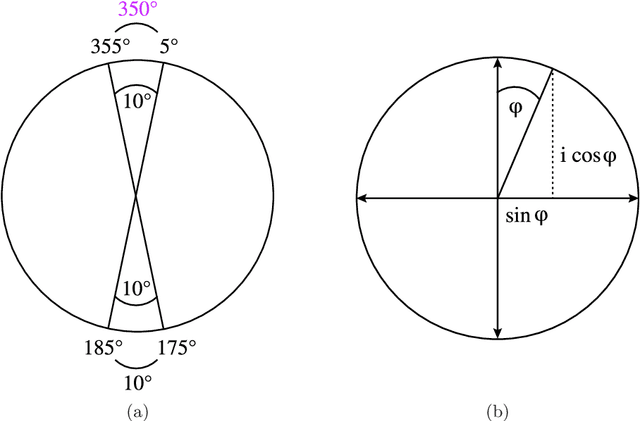
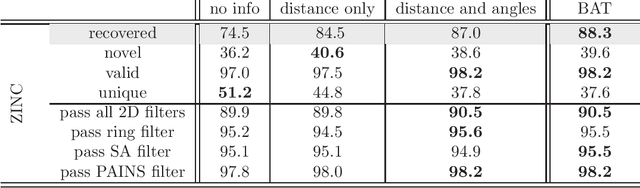
Recent developments in machine-learning based molecular fragment linking have demonstrated the importance of informing the generation process with structural information specifying the relative orientation of the fragments to be linked. However, such structural information has not yet been provided in the form of a complete relative coordinate system. Mathematical details for a decoupled set of bond lengths, bond angles and torsion angles are elaborated and the coordinate system is demonstrated to be complete. Significant impact on the quality of the generated linkers is demonstrated numerically. The amount of reliable information within the different types of degrees of freedom is investigated. Ablation studies and an information-theoretical analysis are performed. The presented benefits suggest the application of a complete and decoupled relative coordinate system as a standard good practice in linker design.
Schema Curation via Causal Association Rule Mining
Apr 18, 2021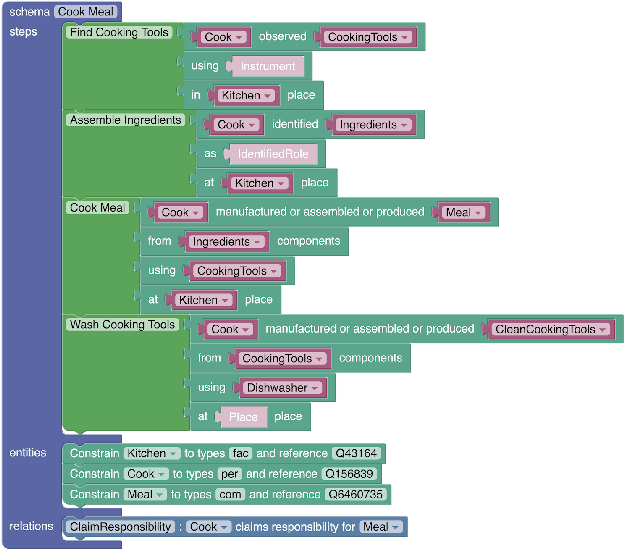



Event schemas are structured knowledge sources defining typical real-world scenarios (e.g., going to an airport). We present a framework for efficient human-in-the-loop construction of a schema library, based on a novel mechanism for schema induction and a well-crafted interface that allows non-experts to "program" complex event structures. Associated with this work we release a machine readable resource (schema library) of 232 detailed event schemas, each of which describe a distinct typical scenario in terms of its relevant sub-event structure (what happens in the scenario), participants (who plays a role in the scenario), fine-grained typing of each participant, and the implied relational constraints between them. Our custom annotation interface, SchemaBlocks, and the event schemas are available online.
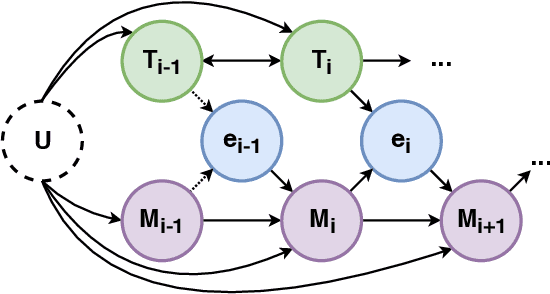
Generating Narrative Text in a Switching Dynamical System
Apr 08, 2020
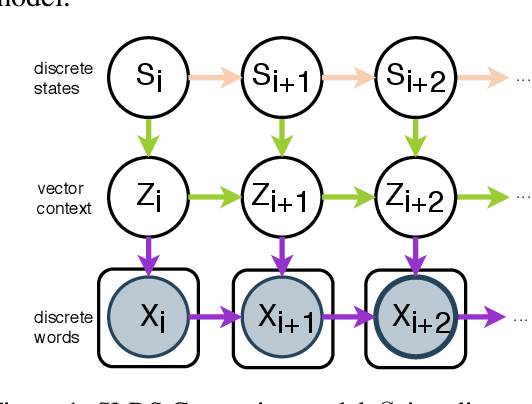
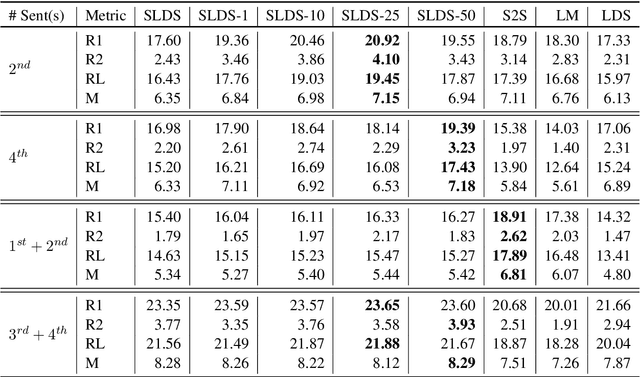
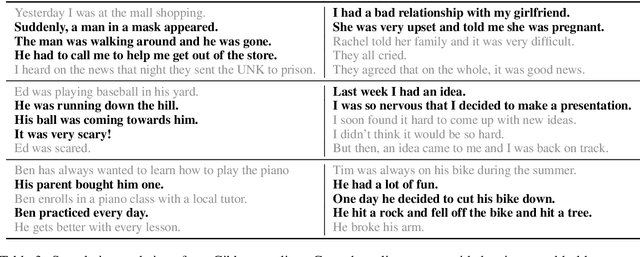
Early work on narrative modeling used explicit plans and goals to generate stories, but the language generation itself was restricted and inflexible. Modern methods use language models for more robust generation, but often lack an explicit representation of the scaffolding and dynamics that guide a coherent narrative. This paper introduces a new model that integrates explicit narrative structure with neural language models, formalizing narrative modeling as a Switching Linear Dynamical System (SLDS). A SLDS is a dynamical system in which the latent dynamics of the system (i.e. how the state vector transforms over time) is controlled by top-level discrete switching variables. The switching variables represent narrative structure (e.g., sentiment or discourse states), while the latent state vector encodes information on the current state of the narrative. This probabilistic formulation allows us to control generation, and can be learned in a semi-supervised fashion using both labeled and unlabeled data. Additionally, we derive a Gibbs sampler for our model that can fill in arbitrary parts of the narrative, guided by the switching variables. Our filled-in (English language) narratives outperform several baselines on both automatic and human evaluations.
Causal Inference of Script Knowledge
Apr 02, 2020

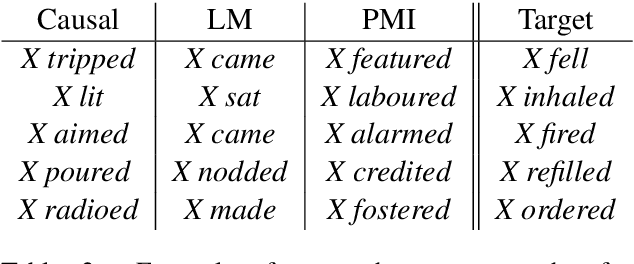
When does a sequence of events define an everyday scenario and how can this knowledge be induced from text? Prior works in inducing such scripts have relied on, in one form or another, measures of correlation between instances of events in a corpus. We argue from both a conceptual and practical sense that a purely correlation-based approach is insufficient, and instead propose an approach to script induction based on the causal effect between events, formally defined via interventions. Through both human and automatic evaluations, we show that the output of our method based on causal effects better matches the intuition of what a script represents
Hierarchical Quantized Representations for Script Generation
Aug 28, 2018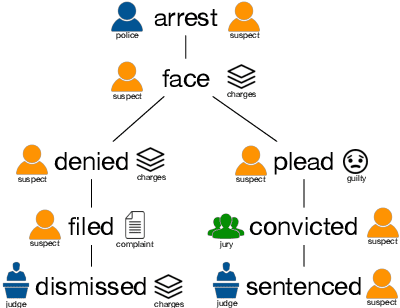
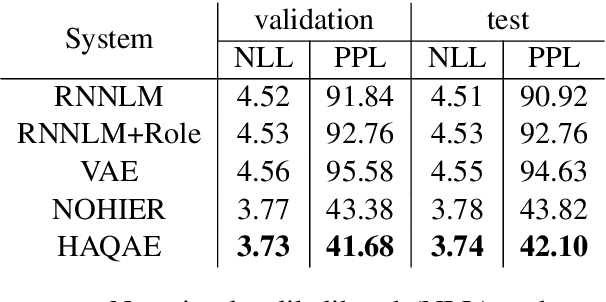
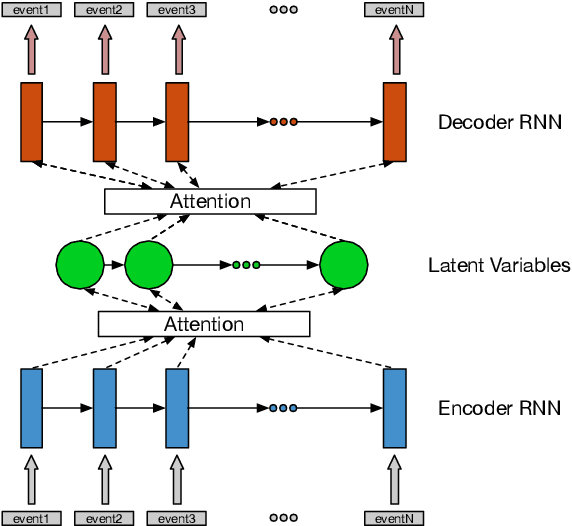
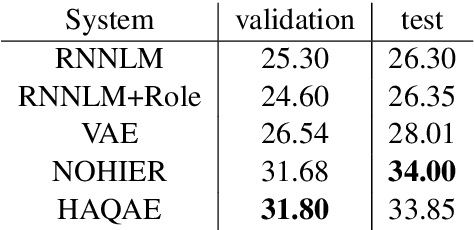
Scripts define knowledge about how everyday scenarios (such as going to a restaurant) are expected to unfold. One of the challenges to learning scripts is the hierarchical nature of the knowledge. For example, a suspect arrested might plead innocent or guilty, and a very different track of events is then expected to happen. To capture this type of information, we propose an autoencoder model with a latent space defined by a hierarchy of categorical variables. We utilize a recently proposed vector quantization based approach, which allows continuous embeddings to be associated with each latent variable value. This permits the decoder to softly decide what portions of the latent hierarchy to condition on by attending over the value embeddings for a given setting. Our model effectively encodes and generates scripts, outperforming a recent language modeling-based method on several standard tasks, and allowing the autoencoder model to achieve substantially lower perplexity scores compared to the previous language modeling-based method.
The Fine Line between Linguistic Generalization and Failure in Seq2Seq-Attention Models
May 08, 2018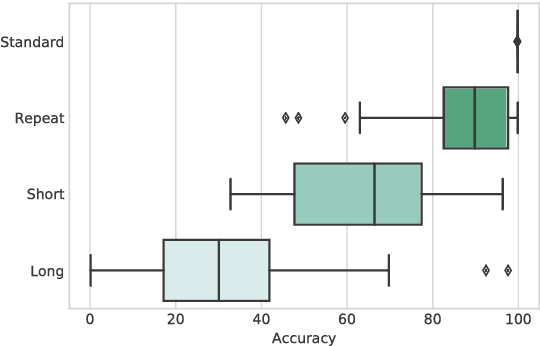
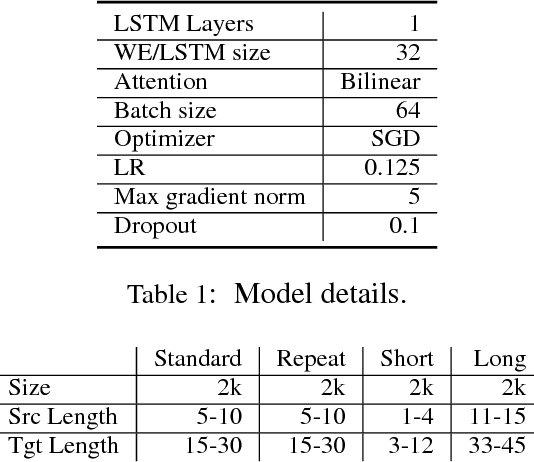
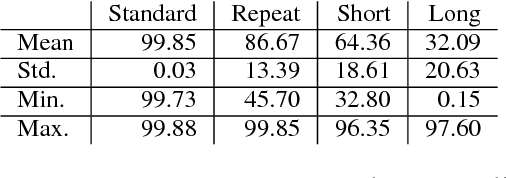
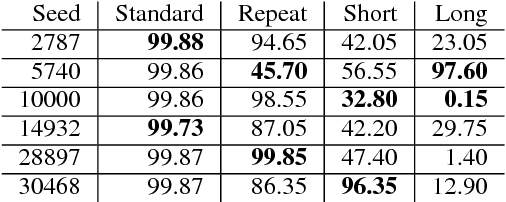
Seq2Seq based neural architectures have become the go-to architecture to apply to sequence to sequence language tasks. Despite their excellent performance on these tasks, recent work has noted that these models usually do not fully capture the linguistic structure required to generalize beyond the dense sections of the data distribution \cite{ettinger2017towards}, and as such, are likely to fail on samples from the tail end of the distribution (such as inputs that are noisy \citep{belkinovnmtbreak} or of different lengths \citep{bentivoglinmtlength}). In this paper, we look at a model's ability to generalize on a simple symbol rewriting task with a clearly defined structure. We find that the model's ability to generalize this structure beyond the training distribution depends greatly on the chosen random seed, even when performance on the standard test set remains the same. This suggests that a model's ability to capture generalizable structure is highly sensitive. Moreover, this sensitivity may not be apparent when evaluating it on standard test sets.
Controlling Decoding for More Abstractive Summaries with Copy-Based Networks
Mar 20, 2018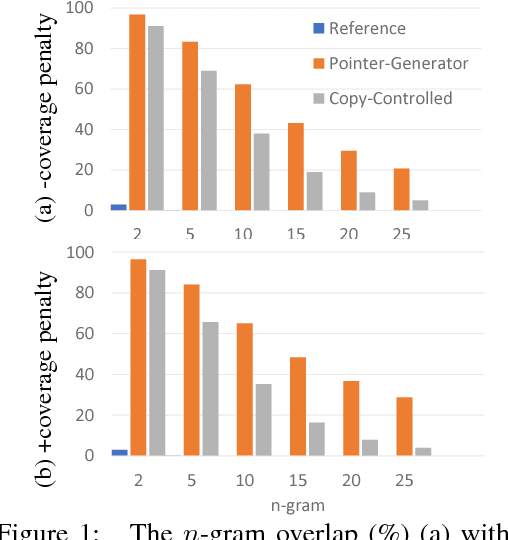
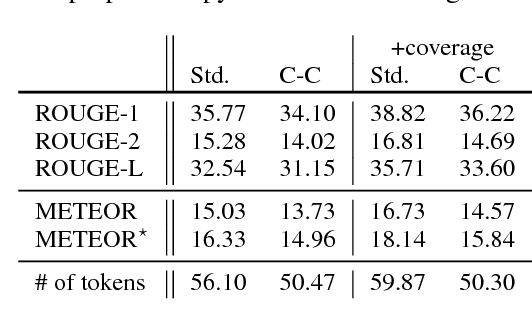
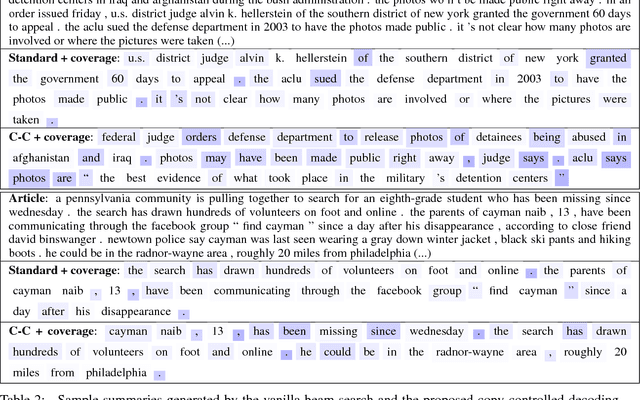
Attention-based neural abstractive summarization systems equipped with copy mechanisms have shown promising results. Despite this success, it has been noticed that such a system generates a summary by mostly, if not entirely, copying over phrases, sentences, and sometimes multiple consecutive sentences from an input paragraph, effectively performing extractive summarization. In this paper, we verify this behavior using the latest neural abstractive summarization system - a pointer-generator network. We propose a simple baseline method that allows us to control the amount of copying without retraining. Experiments indicate that the method provides a strong baseline for abstractive systems looking to obtain high ROUGE scores while minimizing overlap with the source article, substantially reducing the n-gram overlap with the original article while keeping within 2 points of the original model's ROUGE score.
Event Representations with Tensor-based Compositions
Nov 21, 2017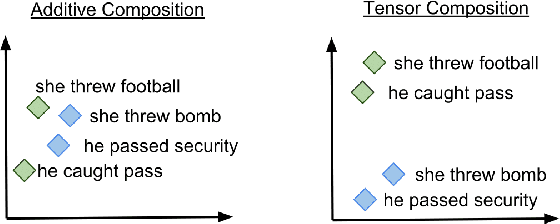
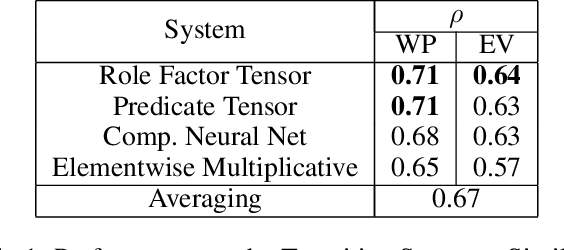
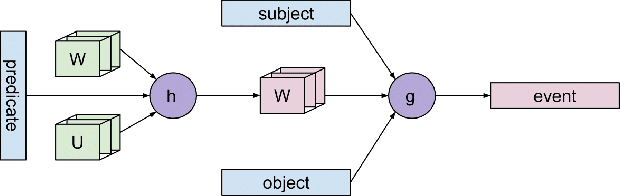

Robust and flexible event representations are important to many core areas in language understanding. Scripts were proposed early on as a way of representing sequences of events for such understanding, and has recently attracted renewed attention. However, obtaining effective representations for modeling script-like event sequences is challenging. It requires representations that can capture event-level and scenario-level semantics. We propose a new tensor-based composition method for creating event representations. The method captures more subtle semantic interactions between an event and its entities and yields representations that are effective at multiple event-related tasks. With the continuous representations, we also devise a simple schema generation method which produces better schemas compared to a prior discrete representation based method. Our analysis shows that the tensors capture distinct usages of a predicate even when there are only subtle differences in their surface realizations.