 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fine Line between Linguistic Generalization and Failure in Seq2Seq-Attention Models
Paper and Code
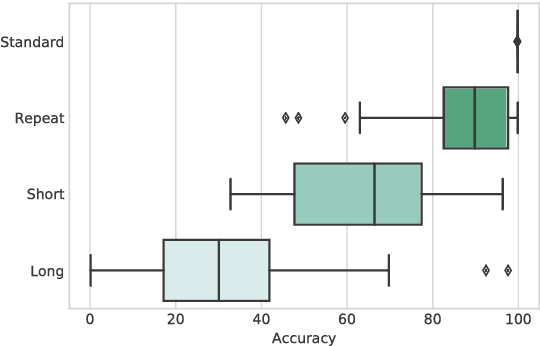
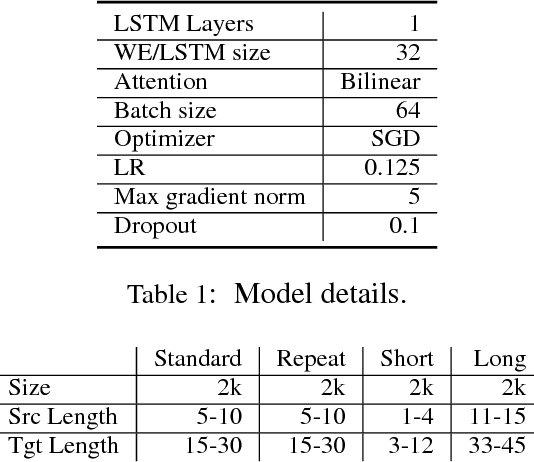
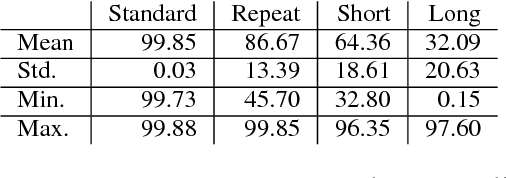
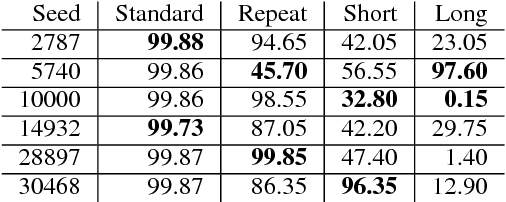
Seq2Seq based neural architectures have become the go-to architecture to apply to sequence to sequence language tasks. Despite their excellent performance on these tasks, recent work has noted that these models usually do not fully capture the linguistic structure required to generalize beyond the dense sections of the data distribution \cite{ettinger2017towards}, and as such, are likely to fail on samples from the tail end of the distribution (such as inputs that are noisy \citep{belkinovnmtbreak} or of different lengths \citep{bentivoglinmtlength}). In this paper, we look at a model's ability to generalize on a simple symbol rewriting task with a clearly defined structure. We find that the model's ability to generalize this structure beyond the training distribution depends greatly on the chosen random seed, even when performance on the standard test set remains the same. This suggests that a model's ability to capture generalizable structure is highly sensitive. Moreover, this sensitivity may not be apparent when evaluating it on standard test sets.