 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Diverse Precondition Generation
Jun 14, 2021
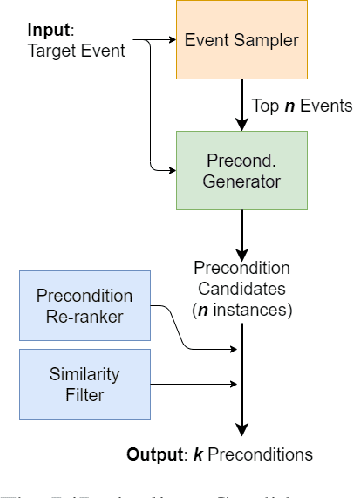

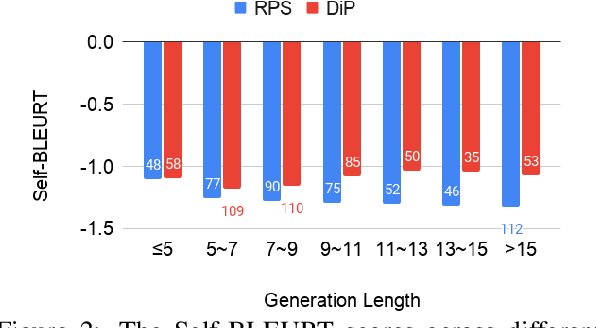
Language understanding must identify the logical connections between events in a discourse, but core events are often unstated due to their commonsense nature. This paper fills in these missing events by generating precondition events. Precondition generation can be framed as a sequence-to-sequence problem: given a target event, generate a possible precondition. However, in most real-world scenarios, an event can have several preconditions, requiring diverse generation -- a challenge for standard seq2seq approaches. We propose DiP, a Diverse Precondition generation system that can generate unique and diverse preconditions. DiP uses a generative process with three components -- an event sampler, a candidate generator, and a post-processor. The event sampler provides control codes (precondition triggers) which the candidate generator uses to focus its generation. Unlike other conditional generation systems, DiP automatically generates control codes without training on diverse examples. Analysis against baselines reveals that DiP improves the diversity of preconditions significantly while also generating more preconditions.
Modeling Preconditions in Text with a Crowd-sourced Dataset
Oct 14, 2020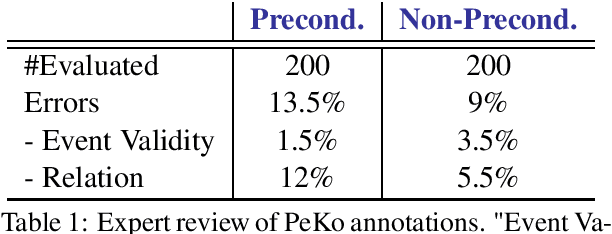

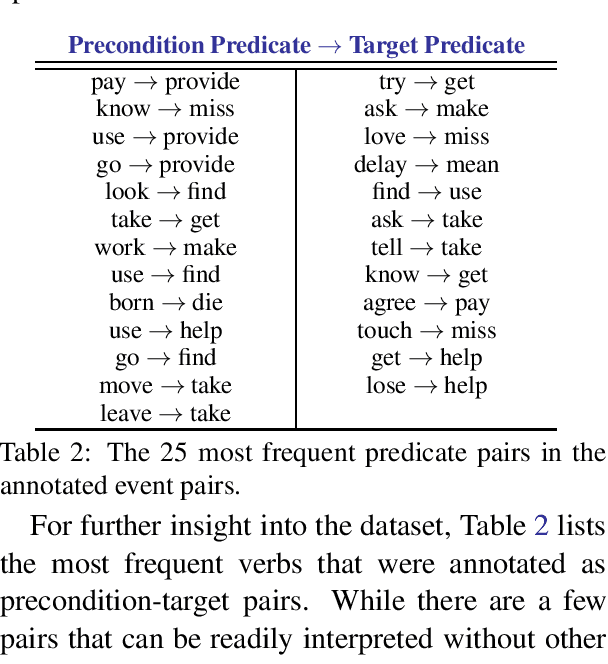
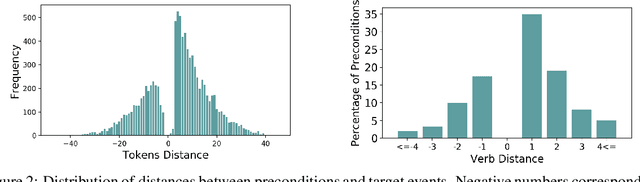
Preconditions provide a form of logical connection between events that explains why some events occur together and information that is complementary to the more widely studied relations such as causation, temporal ordering, entailment, and discourse relations. Modeling preconditions in text has been hampered in part due to the lack of large scale labeled data grounded in text. This paper introduces PeKo, a crowd-sourced annotation of preconditions between event pairs in newswire, an order of magnitude larger than prior text annotations. To complement this new corpus, we also introduce two challenge tasks aimed at modeling preconditions: (i) Precondition Identification -- a standard classification task defined over pairs of event mentions, and (ii) Precondition Generation -- a generative task aimed at testing a more general ability to reason about a given event. Evaluation on both tasks shows that modeling preconditions is challenging even for today's large language models (LM). This suggests that precondition knowledge is not easily accessible in LM-derived representations alone. Our generation results show that fine-tuning an LM on PeKo yields better conditional relations than when trained on raw text or temporally-ordered corpora.
Modeling Label Semantics for Predicting Emotional Reactions
Jun 28, 2020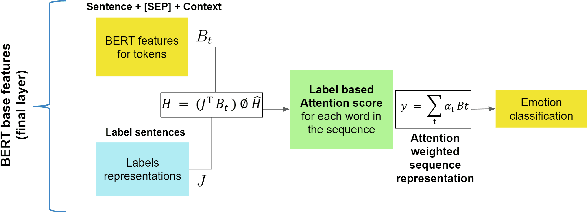
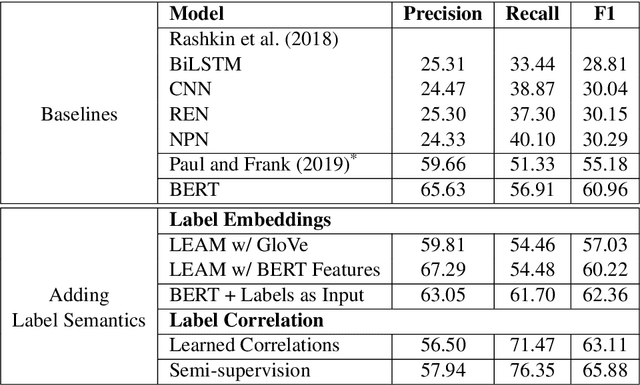
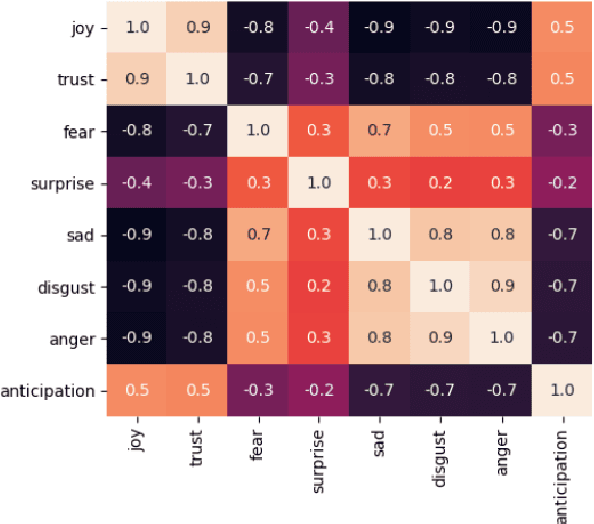
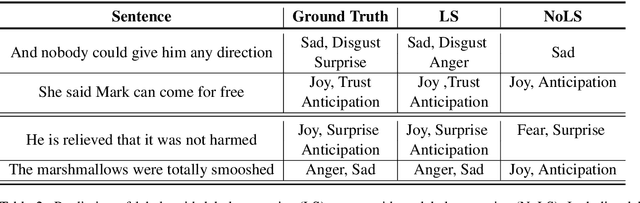
Predicting how events induce emotions in the characters of a story is typically seen as a standard multi-label classification task, which usually treats labels as anonymous classes to predict. They ignore information that may be conveyed by the emotion labels themselves. We propose that the semantics of emotion labels can guide a model's attention when representing the input story. Further, we observe that the emotions evoked by an event are often related: an event that evokes joy is unlikely to also evoke sadness. In this work, we explicitly model label classes via label embeddings, and add mechanisms that track label-label correlations both during training and inference. We also introduce a new semi-supervision strategy that regularizes for the correlations on unlabeled data. Our empirical evaluations show that modeling label semantics yields consistent benefits, and we advance the state-of-the-art on an emotion inference task.
Generating Narrative Text in a Switching Dynamical System
Apr 08, 2020
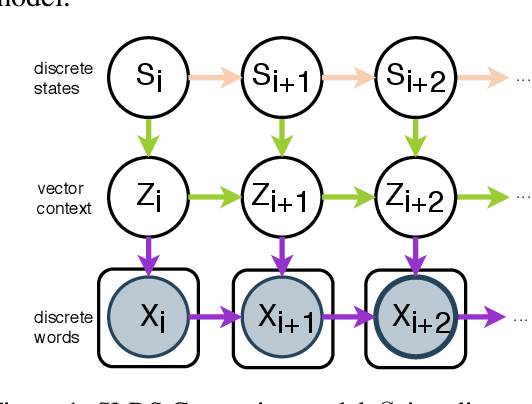
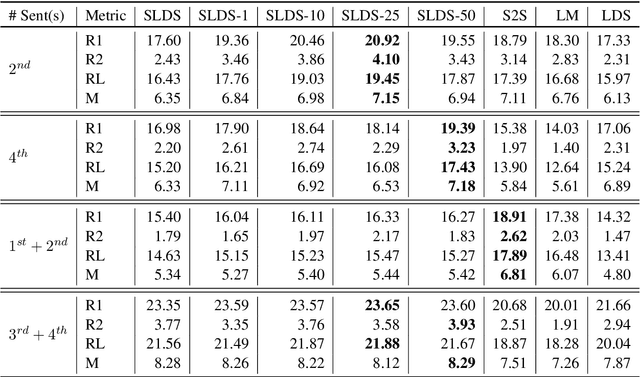
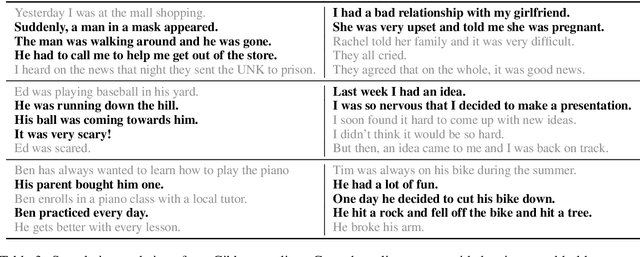
Early work on narrative modeling used explicit plans and goals to generate stories, but the language generation itself was restricted and inflexible. Modern methods use language models for more robust generation, but often lack an explicit representation of the scaffolding and dynamics that guide a coherent narrative. This paper introduces a new model that integrates explicit narrative structure with neural language models, formalizing narrative modeling as a Switching Linear Dynamical System (SLDS). A SLDS is a dynamical system in which the latent dynamics of the system (i.e. how the state vector transforms over time) is controlled by top-level discrete switching variables. The switching variables represent narrative structure (e.g., sentiment or discourse states), while the latent state vector encodes information on the current state of the narrative. This probabilistic formulation allows us to control generation, and can be learned in a semi-supervised fashion using both labeled and unlabeled data. Additionally, we derive a Gibbs sampler for our model that can fill in arbitrary parts of the narrative, guided by the switching variables. Our filled-in (English language) narratives outperform several baselines on both automatic and human evaluations.
Repurposing Entailment for Multi-Hop Question Answering Tasks
Apr 20, 2019



Question Answering (QA) naturally reduces to an entailment problem, namely, verifying whether some text entails the answer to a question. However, for multi-hop QA tasks, which require reasoning with multiple sentences, it remains unclear how best to utilize entailment models pre-trained on large scale datasets such as SNLI, which are based on sentence pairs. We introduce Multee, a general architecture that can effectively use entailment models for multi-hop QA tasks. Multee uses (i) a local module that helps locate important sentences, thereby avoiding distracting information, and (ii) a global module that aggregates information by effectively incorporating importance weights. Importantly, we show that both modules can use entailment functions pre-trained on a large scale NLI datasets. We evaluate performance on MultiRC and OpenBookQA, two multihop QA datasets. When using an entailment function pre-trained on NLI datasets, Multee outperforms QA models trained only on the target QA datasets and the OpenAI transformer models. The code is available at https://github.com/StonyBrookNLP/multee.
Fake Sentence Detection as a Training Task for Sentence Encoding
Aug 24, 2018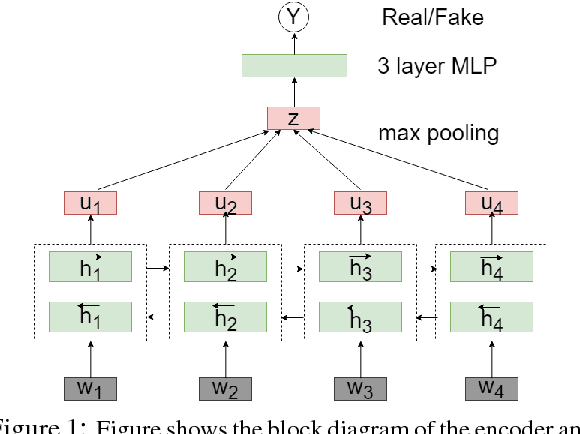
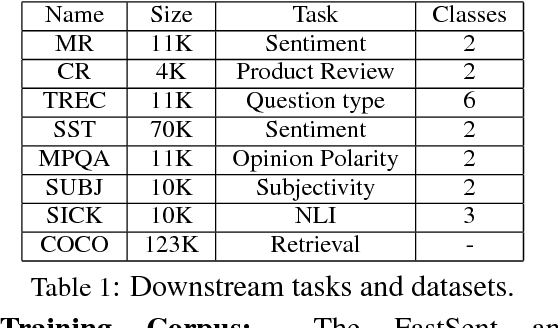


Sentence encoders are typically trained on language modeling tasks with large unlabeled datasets. While these encoders achieve state-of-the-art results on many sentence-level tasks, they are difficult to train with long training cycles. We introduce fake sentence detection as a new training task for learning sentence encoders. We automatically generate fake sentences by corrupting original sentences from a source collection and train the encoders to produce representations that are effective at detecting fake sentences. This binary classification task turns to be quite efficient for training sentence encoders. We compare a basic BiLSTM encoder trained on this task with a strong sentence encoding models (Skipthought and FastSent) trained on a language modeling task. We find that the BiLSTM trains much faster on fake sentence detection (20 hours instead of weeks) using smaller amounts of data (1M instead of 64M sentences). Further analysis shows the learned representations capture many syntactic and semantic properties expected from good sentence representations.