 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Visual Information Processing in Multimodal LLMs
Nov 13, 2025
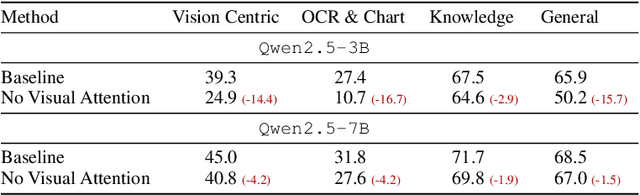
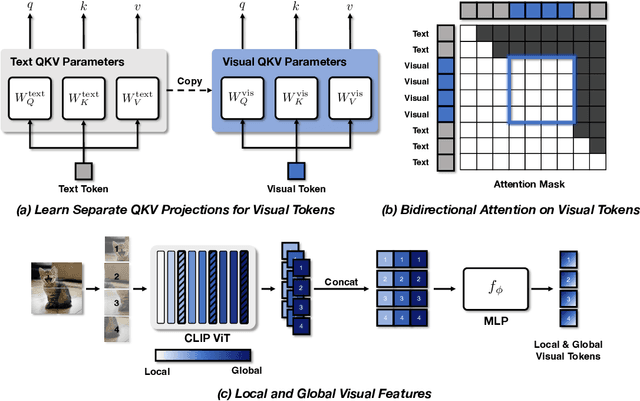
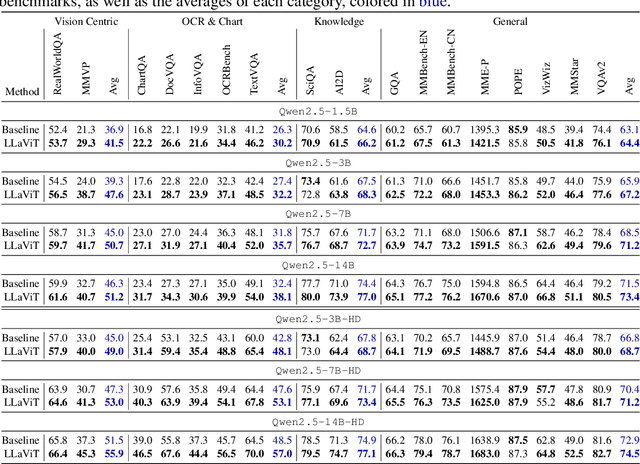
Despite the remarkable success of the LLaVA architecture for vision-language tasks, its design inherently struggles to effectively integrate visual features due to the inherent mismatch between text and vision modalities. We tackle this issue from a novel perspective in which the LLM not only serves as a language model but also a powerful vision encoder. To this end, we present LLaViT - Large Language Models as extended Vision Transformers - which enables the LLM to simultaneously function as a vision encoder through three key modifications: (1) learning separate QKV projections for vision modality, (2) enabling bidirectional attention on visual tokens, and (3) incorporating both global and local visual representations. Through extensive controlled experiments on a wide range of LLMs, we demonstrate that LLaViT significantly outperforms the baseline LLaVA method on a multitude of benchmarks, even surpassing models with double its parameter count, establishing a more effective approach to vision-language modeling.
Interactive Class-Agnostic Object Counting
Sep 11, 2023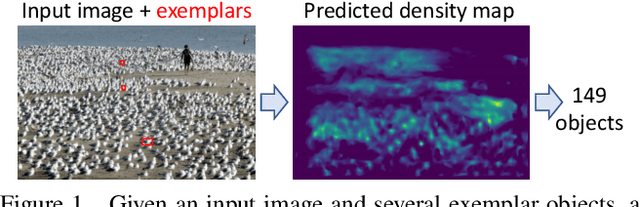
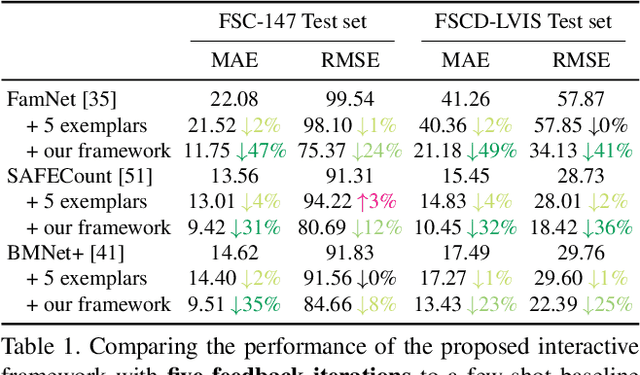
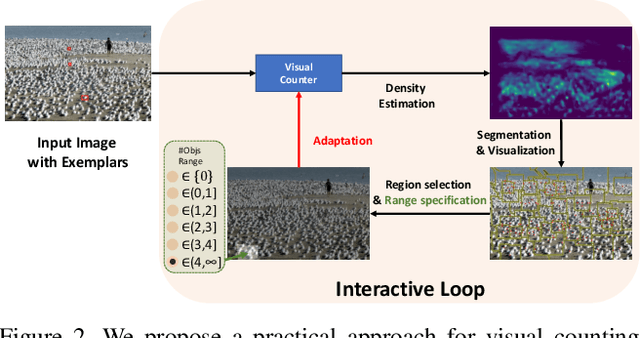
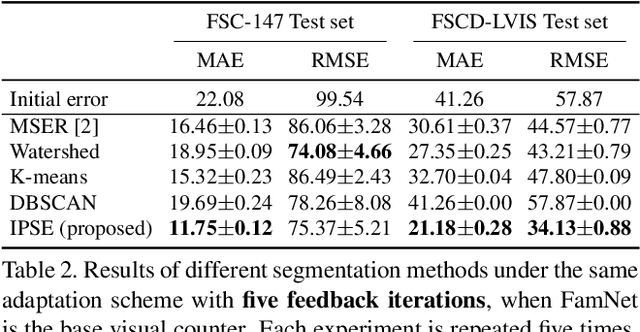
We propose a novel framework for interactive class-agnostic object counting, where a human user can interactively provide feedback to improve the accuracy of a counter. Our framework consists of two main components: a user-friendly visualizer to gather feedback and an efficient mechanism to incorporate it. In each iteration, we produce a density map to show the current prediction result, and we segment it into non-overlapping regions with an easily verifiable number of objects. The user can provide feedback by selecting a region with obvious counting errors and specifying the range for the estimated number of objects within it. To improve the counting result, we develop a novel adaptation loss to force the visual counter to output the predicted count within the user-specified range. For effective and efficient adaptation, we propose a refinement module that can be used with any density-based visual counter, and only the parameters in the refinement module will be updated during adaptation. Our experiments on two challenging class-agnostic object counting benchmarks, FSCD-LVIS and FSC-147, show that our method can reduce the mean absolute error of multiple state-of-the-art visual counters by roughly 30% to 40% with minimal user input. Our project can be found at https://yifehuang97.github.io/ICACountProjectPage/.
Zero-shot Object Counting
Mar 03, 2023


Class-agnostic object counting aims to count object instances of an arbitrary class at test time. It is challenging but also enables many potential applications. Current methods require human-annotated exemplars as inputs which are often unavailable for novel categories, especially for autonomous systems. Thus, we propose zero-shot object counting (ZSC), a new setting where only the class name is available during test time. Such a counting system does not require human annotators in the loop and can operate automatically. Starting from a class name, we propose a method that can accurately identify the optimal patches which can then be used as counting exemplars. Specifically, we first construct a class prototype to select the patches that are likely to contain the objects of interest, namely class-relevant patches. Furthermore, we introduce a model that can quantitatively measure how suitable an arbitrary patch is as a counting exemplar. By applying this model to all the candidate patches, we can select the most suitable patches as exemplars for counting. Experimental results on a recent class-agnostic counting dataset, FSC-147, validate the effectiveness of our method. Code is available at https://github.com/cvlab-stonybrook/zero-shot-counting
Exemplar Free Class Agnostic Counting
May 27, 2022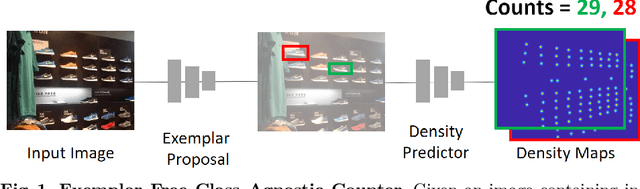
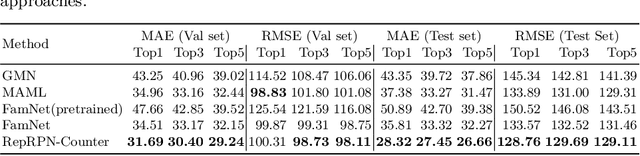
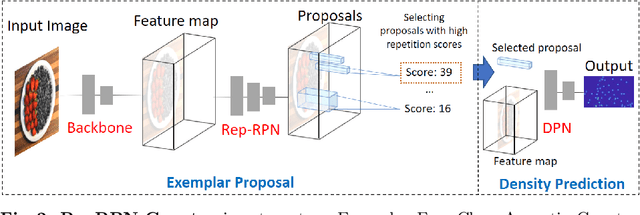
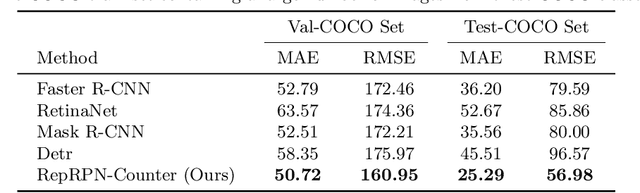
We tackle the task of Class Agnostic Counting, which aims to count objects in a novel object category at test time without any access to labeled training data for that category. All previous class agnostic counting methods cannot work in a fully automated setting, and require computationally expensive test time adaptation. To address these challenges, we propose a visual counter which operates in a fully automated setting and does not require any test time adaptation. Our proposed approach first identifies exemplars from repeating objects in an image, and then counts the repeating objects. We propose a novel region proposal network for identifying the exemplars. After identifying the exemplars, we obtain the corresponding count by using a density estimation based Visual Counter. We evaluate our proposed approach on FSC-147 dataset, and show that it achieves superior performance compared to the existing approaches.
Learning To Count Everything
Apr 16, 2021
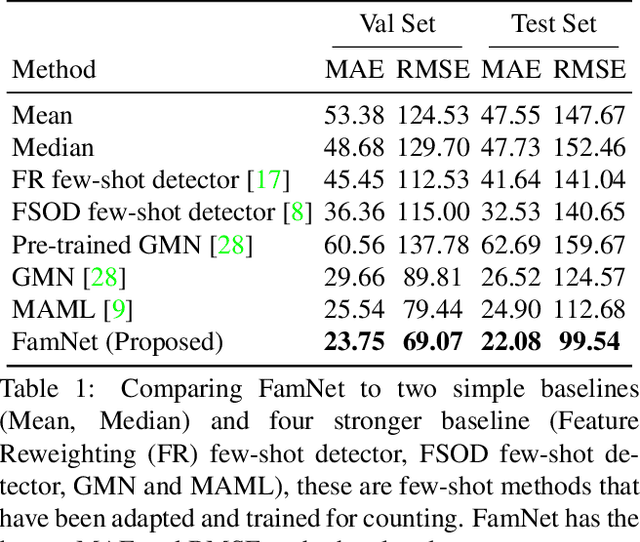
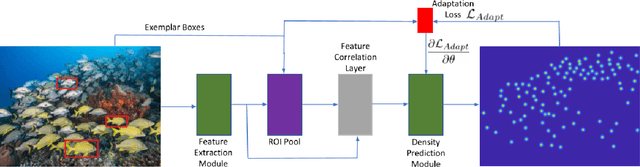
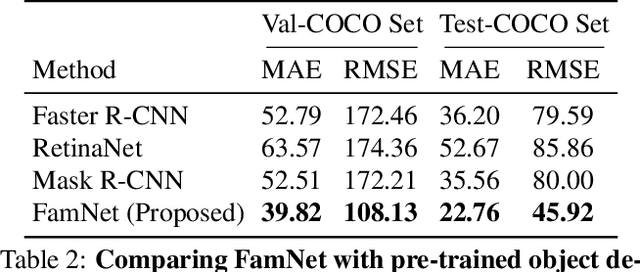
Existing works on visual counting primarily focus on one specific category at a time, such as people, animals, and cells. In this paper, we are interested in counting everything, that is to count objects from any category given only a few annotated instances from that category. To this end, we pose counting as a few-shot regression task. To tackle this task, we present a novel method that takes a query image together with a few exemplar objects from the query image and predicts a density map for the presence of all objects of interest in the query image. We also present a novel adaptation strategy to adapt our network to any novel visual category at test time, using only a few exemplar objects from the novel category. We also introduce a dataset of 147 object categories containing over 6000 images that are suitable for the few-shot counting task. The images are annotated with two types of annotation, dots and bounding boxes, and they can be used for developing few-shot counting models. Experiments on this dataset shows that our method outperforms several state-of-the-art object detectors and few-shot counting approaches. Our code and dataset can be found at https://github.com/cvlab-stonybrook/LearningToCountEverything.
Uncertainty Estimation and Sample Selection for Crowd Counting
Oct 04, 2020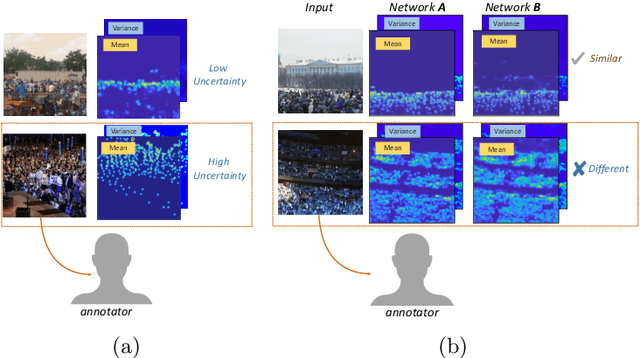

We present a method for image-based crowd counting, one that can predict a crowd density map together with the uncertainty values pertaining to the predicted density map. To obtain prediction uncertainty, we model the crowd density values using Gaussian distributions and develop a convolutional neural network architecture to predict these distributions. A key advantage of our method over existing crowd counting methods is its ability to quantify the uncertainty of its predictions. We illustrate the benefits of knowing the prediction uncertainty by developing a method to reduce the human annotation effort needed to adapt counting networks to a new domain. We present sample selection strategies which make use of the density and uncertainty of predictions from the networks trained on one domain to select the informative images from a target domain of interest to acquire human annotation. We show that our sample selection strategy drastically reduces the amount of labeled data from the target domain needed to adapt a counting network trained on a source domain to the target domain. Empirically, the networks trained on UCF-QNRF dataset can be adapted to surpass the performance of the previous state-of-the-art results on NWPU dataset and Shanghaitech dataset using only 17$\%$ of the labeled training samples from the target domain.
A Study of Human Gaze Behavior During Visual Crowd Counting
Sep 27, 2020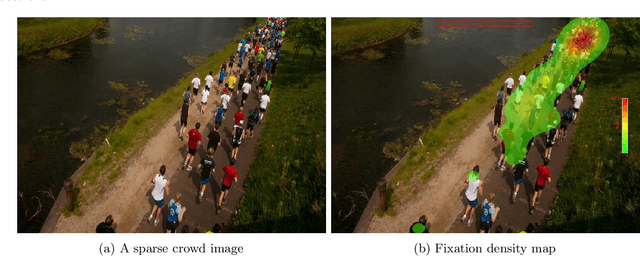
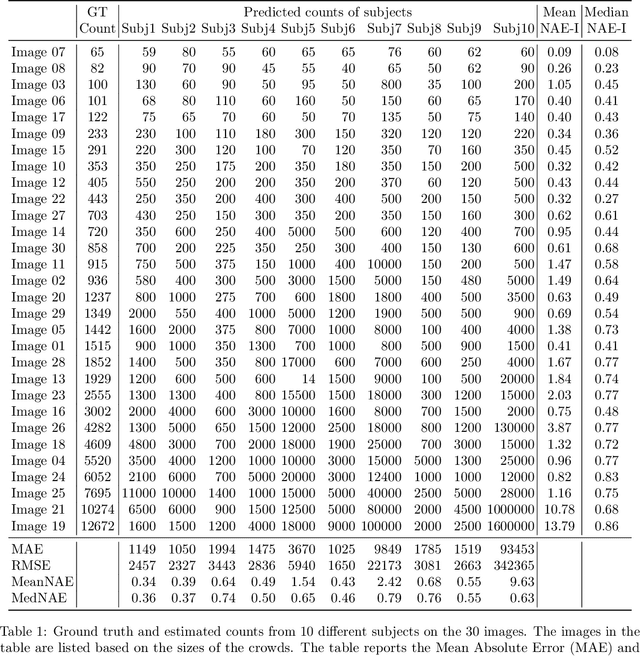

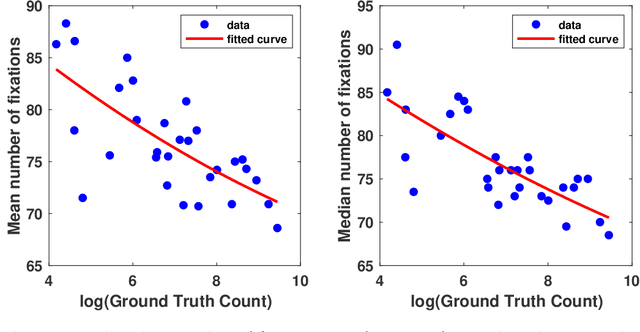
In this paper, we describe our study on how humans allocate their attention during visual crowd counting. Using an eye tracker, we collect gaze behavior of human participants who are tasked with counting the number of people in crowd images. Analyzing the collected gaze behavior of ten human participants on thirty crowd images, we observe some common approaches for visual counting. For an image of a small crowd, the approach is to enumerate over all people or groups of people in the crowd, and this explains the high level of similarity between the fixation density maps of different human participants. For an image of a large crowd, our participants tend to focus on one section of the image, count the number of people in that section, and then extrapolate to the other sections. In terms of count accuracy, our human participants are not as good at the counting task, compared to the performance of the current state-of-the-art computer algorithms. Interestingly, there is a tendency to under count the number of people in all crowd images. Gaze behavior data and images can be downloaded from https://www3.cs.stonybrook.edu/~minhhoai/projects/crowd_counting_gaze/.
Crowd Transformer Network
Apr 04, 2019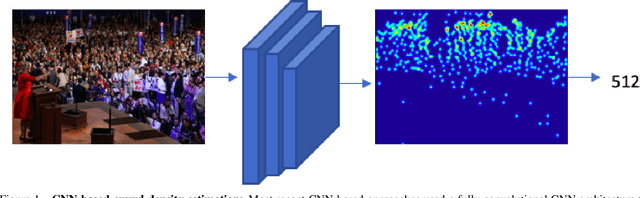
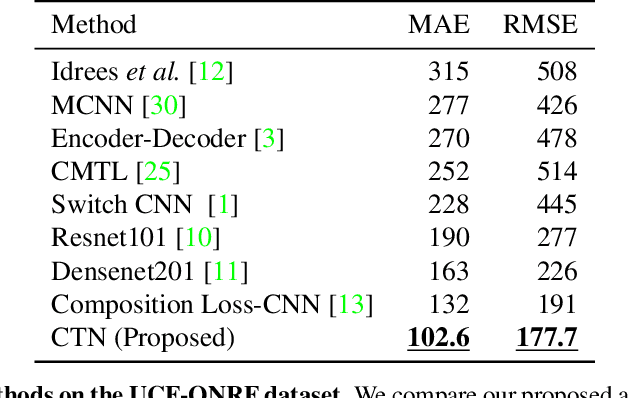
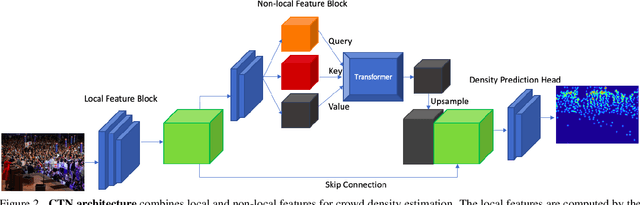

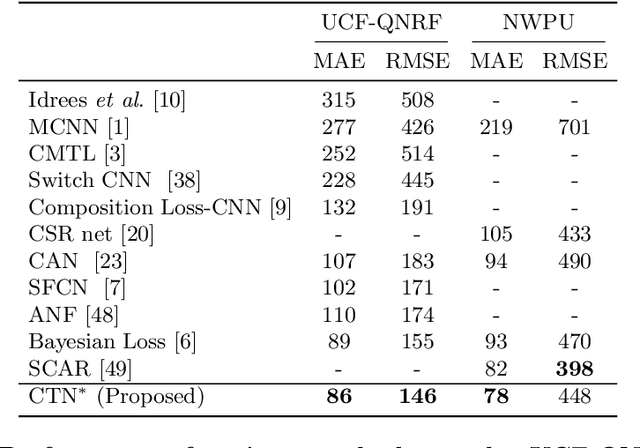
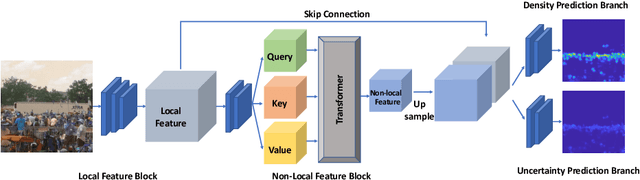
In this paper, we tackle the problem of Crowd Counting, and present a crowd density estimation based approach for obtaining the crowd count. Most of the existing crowd counting approaches rely on local features for estimating the crowd density map. In this work, we investigate the usefulness of combining local with non-local features for crowd counting. We use convolution layers for extracting local features, and a type of self-attention mechanism for extracting non-local features. We combine the local and the non-local features, and use it for estimating crowd density map. We conduct experiments on three publicly available Crowd Counting datasets, and achieve significant improvement over the previous approaches.
Fake Sentence Detection as a Training Task for Sentence Encoding
Aug 24, 2018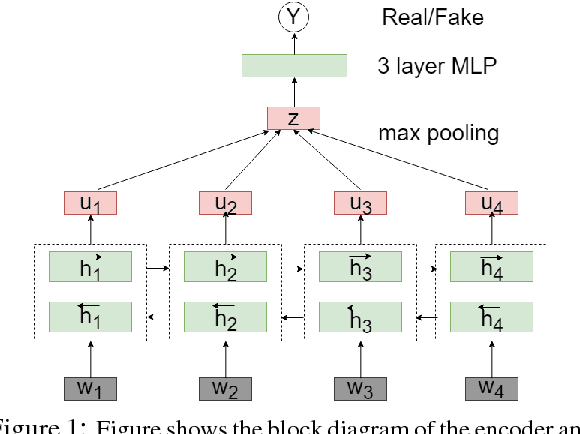
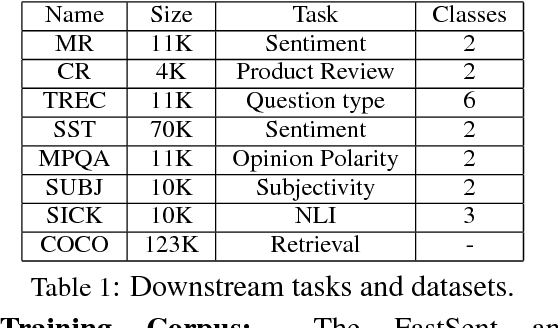


Sentence encoders are typically trained on language modeling tasks with large unlabeled datasets. While these encoders achieve state-of-the-art results on many sentence-level tasks, they are difficult to train with long training cycles. We introduce fake sentence detection as a new training task for learning sentence encoders. We automatically generate fake sentences by corrupting original sentences from a source collection and train the encoders to produce representations that are effective at detecting fake sentences. This binary classification task turns to be quite efficient for training sentence encoders. We compare a basic BiLSTM encoder trained on this task with a strong sentence encoding models (Skipthought and FastSent) trained on a language modeling task. We find that the BiLSTM trains much faster on fake sentence detection (20 hours instead of weeks) using smaller amounts of data (1M instead of 64M sentences). Further analysis shows the learned representations capture many syntactic and semantic properties expected from good sentence representations.
Iterative Crowd Counting
Jul 26, 2018

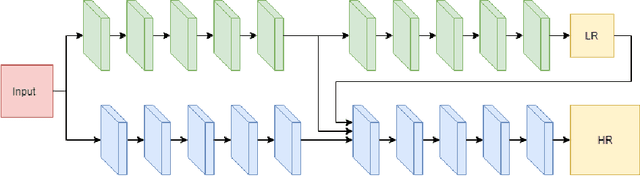

In this work, we tackle the problem of crowd counting in images. We present a Convolutional Neural Network (CNN) based density estimation approach to solve this problem. Predicting a high resolution density map in one go is a challenging task. Hence, we present a two branch CNN architecture for generating high resolution density maps, where the first branch generates a low resolution density map, and the second branch incorporates the low resolution prediction and feature maps from the first branch to generate a high resolution density map. We also propose a multi-stage extension of our approach where each stage in the pipeline utilizes the predictions from all the previous stages. Empirical comparison with the previous state-of-the-art crowd counting methods shows that our method achieves the lowest mean absolute error on three challenging crowd counting benchmarks: Shanghaitech, WorldExpo'10, and UCF datasets.