 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFake Sentence Detection as a Training Task for Sentence Encoding
Paper and Code
Aug 24, 2018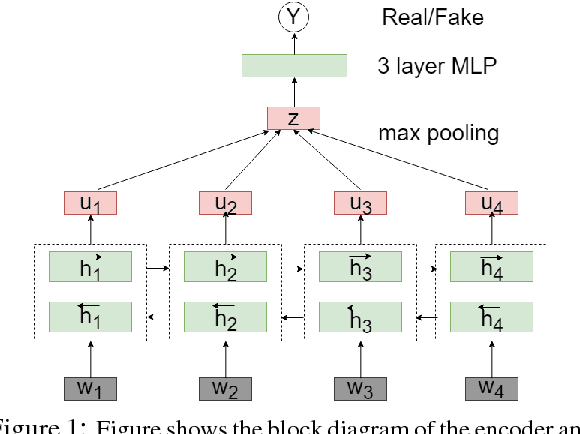
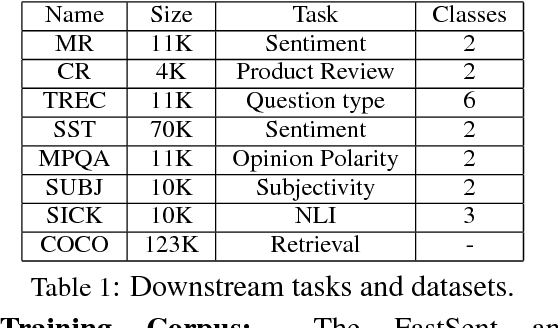


Sentence encoders are typically trained on language modeling tasks with large unlabeled datasets. While these encoders achieve state-of-the-art results on many sentence-level tasks, they are difficult to train with long training cycles. We introduce fake sentence detection as a new training task for learning sentence encoders. We automatically generate fake sentences by corrupting original sentences from a source collection and train the encoders to produce representations that are effective at detecting fake sentences. This binary classification task turns to be quite efficient for training sentence encoders. We compare a basic BiLSTM encoder trained on this task with a strong sentence encoding models (Skipthought and FastSent) trained on a language modeling task. We find that the BiLSTM trains much faster on fake sentence detection (20 hours instead of weeks) using smaller amounts of data (1M instead of 64M sentences). Further analysis shows the learned representations capture many syntactic and semantic properties expected from good sentence representations.