 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCountEx: Fine-Grained Counting via Exemplars and Exclusion
Feb 23, 2026This paper presents CountEx, a discriminative visual counting framework designed to address a key limitation of existing prompt-based methods: the inability to explicitly exclude visually similar distractors. While current approaches allow users to specify what to count via inclusion prompts, they often struggle in cluttered scenes with confusable object categories, leading to ambiguity and overcounting. CountEx enables users to express both inclusion and exclusion intent, specifying what to count and what to ignore, through multimodal prompts including natural language descriptions and optional visual exemplars. At the core of CountEx is a novel Discriminative Query Refinement module, which jointly reasons over inclusion and exclusion cues by first identifying shared visual features, then isolating exclusion-specific patterns, and finally applying selective suppression to refine the counting query. To support systematic evaluation of fine-grained counting methods, we introduce CoCount, a benchmark comprising 1,780 videos and 10,086 annotated frames across 97 category pairs. Experiments show that CountEx achieves substantial improvements over state-of-the-art methods for counting objects from both known and novel categories. The data and code are available at https://github.com/bbvisual/CountEx.
Can Current AI Models Count What We Mean, Not What They See? A Benchmark and Systematic Evaluation
Sep 17, 2025Visual counting is a fundamental yet challenging task, especially when users need to count objects of a specific type in complex scenes. While recent models, including class-agnostic counting models and large vision-language models (VLMs), show promise in counting tasks, their ability to perform fine-grained, intent-driven counting remains unclear. In this paper, we introduce PairTally, a benchmark dataset specifically designed to evaluate fine-grained visual counting. Each of the 681 high-resolution images in PairTally contains two object categories, requiring models to distinguish and count based on subtle differences in shape, size, color, or semantics. The dataset includes both inter-category (distinct categories) and intra-category (closely related subcategories) settings, making it suitable for rigorous evaluation of selective counting capabilities. We benchmark a variety of state-of-the-art models, including exemplar-based methods, language-prompted models, and large VLMs. Our results show that despite recent advances, current models struggle to reliably count what users intend, especially in fine-grained and visually ambiguous cases. PairTally provides a new foundation for diagnosing and improving fine-grained visual counting systems.
DualMat: PBR Material Estimation via Coherent Dual-Path Diffusion
Aug 07, 2025We present DualMat, a novel dual-path diffusion framework for estimating Physically Based Rendering (PBR) materials from single images under complex lighting conditions. Our approach operates in two distinct latent spaces: an albedo-optimized path leveraging pretrained visual knowledge through RGB latent space, and a material-specialized path operating in a compact latent space designed for precise metallic and roughness estimation. To ensure coherent predictions between the albedo-optimized and material-specialized paths, we introduce feature distillation during training. We employ rectified flow to enhance efficiency by reducing inference steps while maintaining quality. Our framework extends to high-resolution and multi-view inputs through patch-based estimation and cross-view attention, enabling seamless integration into image-to-3D pipelines. DualMat achieves state-of-the-art performance on both Objaverse and real-world data, significantly outperforming existing methods with up to 28% improvement in albedo estimation and 39% reduction in metallic-roughness prediction errors.
Count What You Want: Exemplar Identification and Few-shot Counting of Human Actions in the Wild
Dec 28, 2023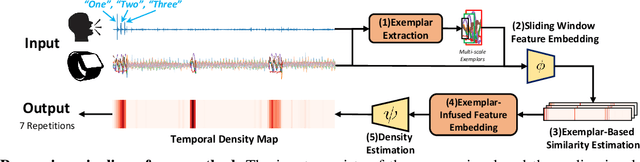
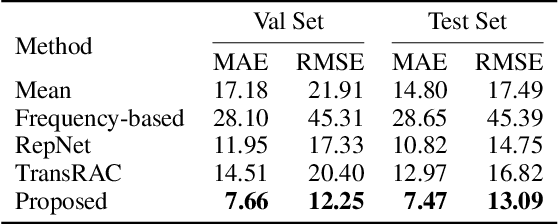
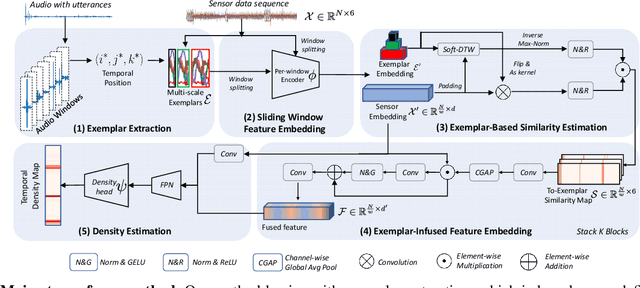

This paper addresses the task of counting human actions of interest using sensor data from wearable devices. We propose a novel exemplar-based framework, allowing users to provide exemplars of the actions they want to count by vocalizing predefined sounds ''one'', ''two'', and ''three''. Our method first localizes temporal positions of these utterances from the audio sequence. These positions serve as the basis for identifying exemplars representing the action class of interest. A similarity map is then computed between the exemplars and the entire sensor data sequence, which is further fed into a density estimation module to generate a sequence of estimated density values. Summing these density values provides the final count. To develop and evaluate our approach, we introduce a diverse and realistic dataset consisting of real-world data from 37 subjects and 50 action categories, encompassing both sensor and audio data. The experiments on this dataset demonstrate the viability of the proposed method in counting instances of actions from new classes and subjects that were not part of the training data. On average, the discrepancy between the predicted count and the ground truth value is 7.47, significantly lower than the errors of the frequency-based and transformer-based methods. Our project, code and dataset can be found at https://github.com/cvlab-stonybrook/ExRAC.
Interactive Class-Agnostic Object Counting
Sep 11, 2023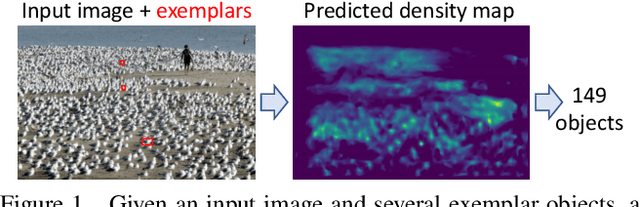
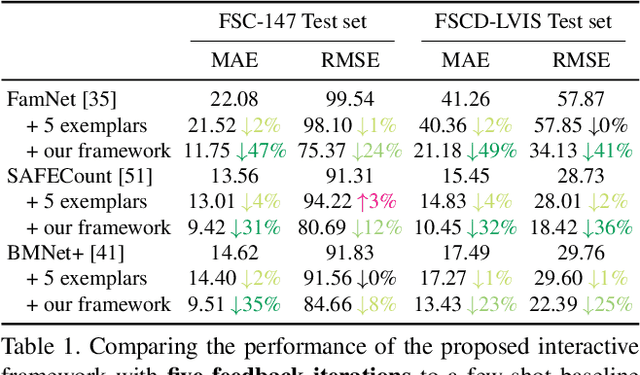
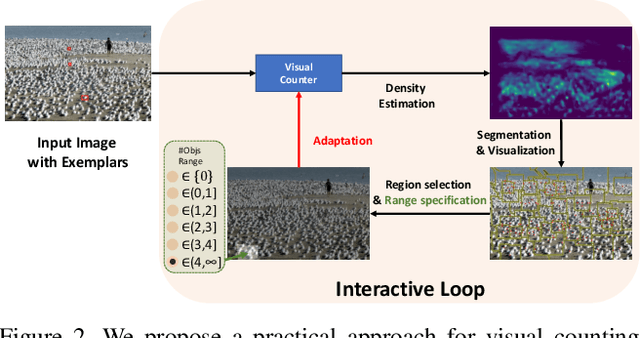
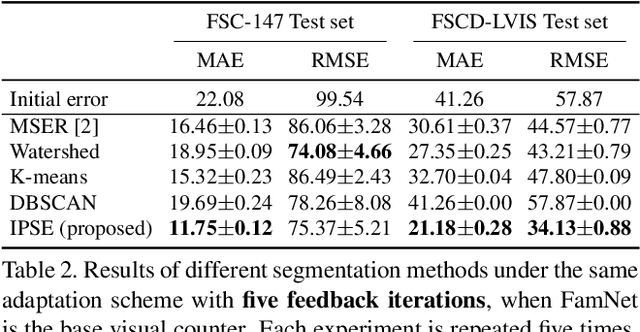
We propose a novel framework for interactive class-agnostic object counting, where a human user can interactively provide feedback to improve the accuracy of a counter. Our framework consists of two main components: a user-friendly visualizer to gather feedback and an efficient mechanism to incorporate it. In each iteration, we produce a density map to show the current prediction result, and we segment it into non-overlapping regions with an easily verifiable number of objects. The user can provide feedback by selecting a region with obvious counting errors and specifying the range for the estimated number of objects within it. To improve the counting result, we develop a novel adaptation loss to force the visual counter to output the predicted count within the user-specified range. For effective and efficient adaptation, we propose a refinement module that can be used with any density-based visual counter, and only the parameters in the refinement module will be updated during adaptation. Our experiments on two challenging class-agnostic object counting benchmarks, FSCD-LVIS and FSC-147, show that our method can reduce the mean absolute error of multiple state-of-the-art visual counters by roughly 30% to 40% with minimal user input. Our project can be found at https://yifehuang97.github.io/ICACountProjectPage/.
The Devil is in the Labels: Noisy Label Correction for Robust Scene Graph Generation
Jun 07, 2022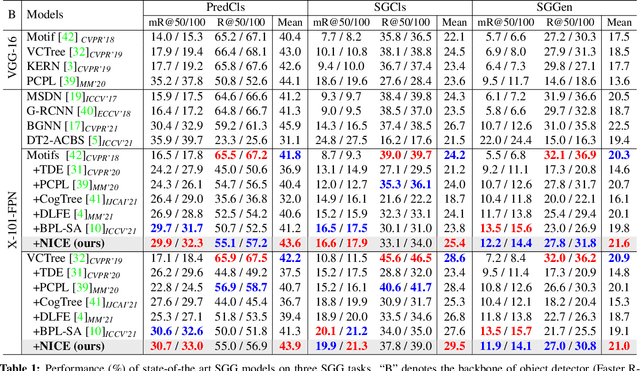
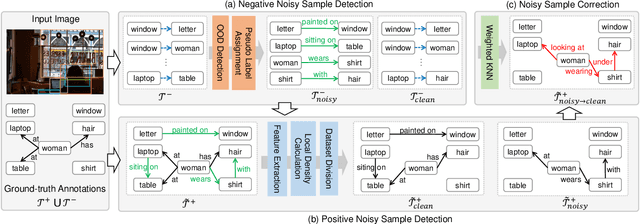
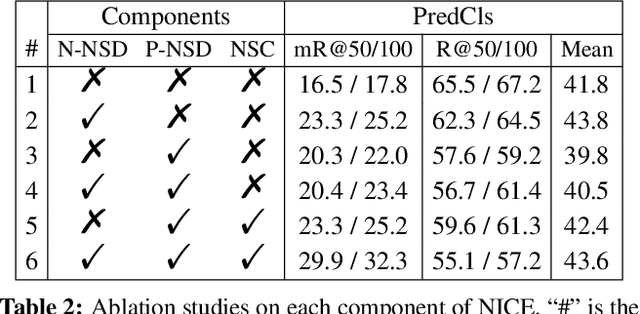
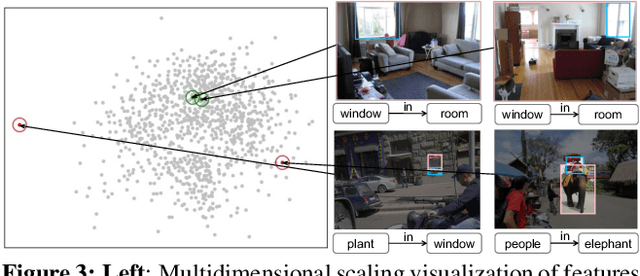
Unbiased SGG has achieved significant progress over recent years. However, almost all existing SGG models have overlooked the ground-truth annotation qualities of prevailing SGG datasets, i.e., they always assume: 1) all the manually annotated positive samples are equally correct; 2) all the un-annotated negative samples are absolutely background. In this paper, we argue that both assumptions are inapplicable to SGG: there are numerous "noisy" groundtruth predicate labels that break these two assumptions, and these noisy samples actually harm the training of unbiased SGG models. To this end, we propose a novel model-agnostic NoIsy label CorrEction strategy for SGG: NICE. NICE can not only detect noisy samples but also reassign more high-quality predicate labels to them. After the NICE training, we can obtain a cleaner version of SGG dataset for model training. Specifically, NICE consists of three components: negative Noisy Sample Detection (Neg-NSD), positive NSD (Pos-NSD), and Noisy Sample Correction (NSC). Firstly, in Neg-NSD, we formulate this task as an out-of-distribution detection problem, and assign pseudo labels to all detected noisy negative samples. Then, in Pos-NSD, we use a clustering-based algorithm to divide all positive samples into multiple sets, and treat the samples in the noisiest set as noisy positive samples. Lastly, in NSC, we use a simple but effective weighted KNN to reassign new predicate labels to noisy positive samples. Extensive results on different backbones and tasks have attested to the effectiveness and generalization abilities of each component of NICE.
Video Relation Detection via Tracklet based Visual Transformer
Aug 19, 2021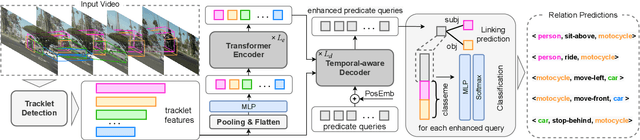

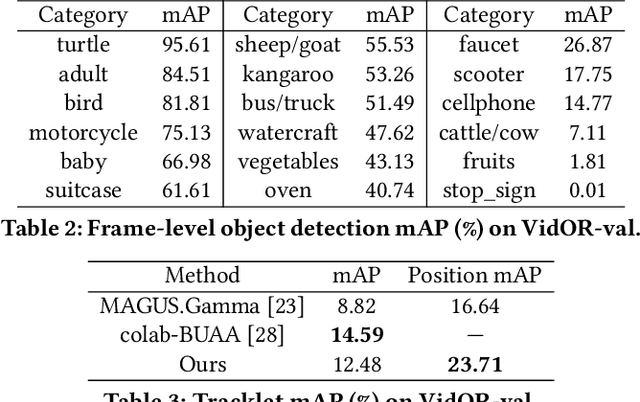
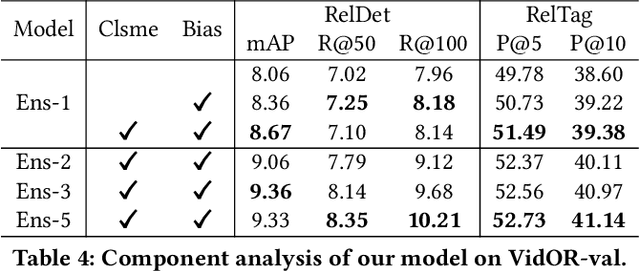
Video Visual Relation Detection (VidVRD), has received significant attention of our community over recent years. In this paper, we apply the state-of-the-art video object tracklet detection pipeline MEGA and deepSORT to generate tracklet proposals. Then we perform VidVRD in a tracklet-based manner without any pre-cutting operations. Specifically, we design a tracklet-based visual Transformer. It contains a temporal-aware decoder which performs feature interactions between the tracklets and learnable predicate query embeddings, and finally predicts the relations. Experimental results strongly demonstrate the superiority of our method, which outperforms other methods by a large margin on the Video Relation Understanding (VRU) Grand Challenge in ACM Multimedia 2021. Codes are released at https://github.com/Dawn-LX/VidVRD-tracklets.
From the Greene--Wu Convolution to Gradient Estimation over Riemannian Manifolds
Aug 17, 2021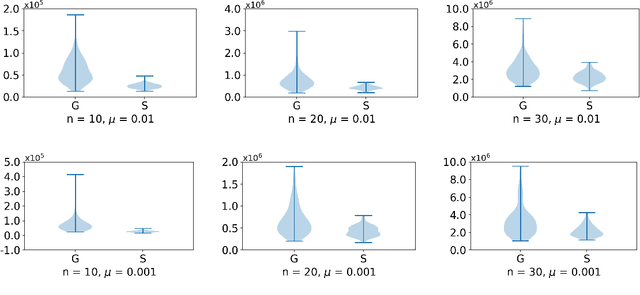
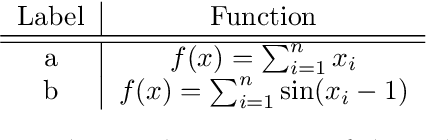
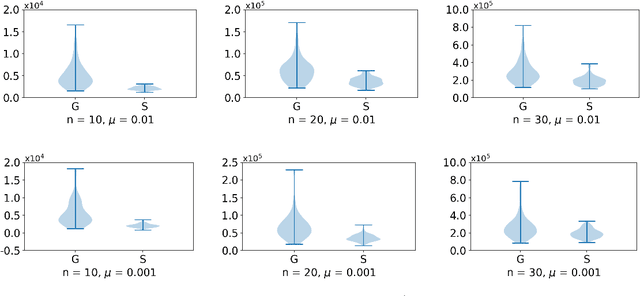
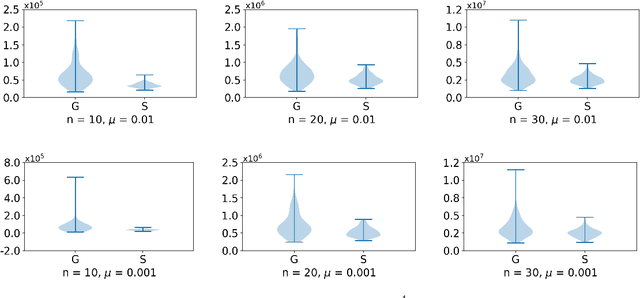
Over a complete Riemannian manifold of finite dimension, Greene and Wu introduced a convolution, known as Greene-Wu (GW) convolution. In this paper, we introduce a reformulation of the GW convolution. Using our reformulation, many properties of the GW convolution can be easily derived, including a new formula for how the curvature of the space would affect the curvature of the function through the GW convolution. Also enabled by our new reformulation, an improved method for gradient estimation over Riemannian manifolds is introduced. Theoretically, our gradient estimation method improves the order of estimation error from $O \left( \left( n + 3 \right)^{3/2} \right)$ to $O \left( n^{3/2} \right)$, where $n$ is the dimension of the manifold. Empirically, our method outperforms the best existing method for gradient estimation over Riemannian manifolds, as evidenced by thorough experimental evaluations.