 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Begin-of-Video Tokens for Autoregressive Video Diffusion Models
Nov 15, 2025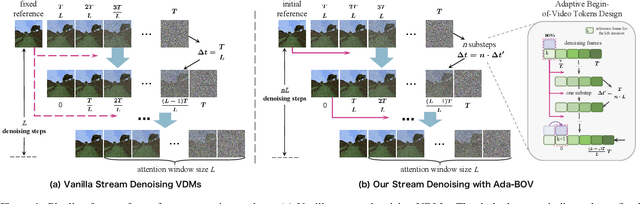
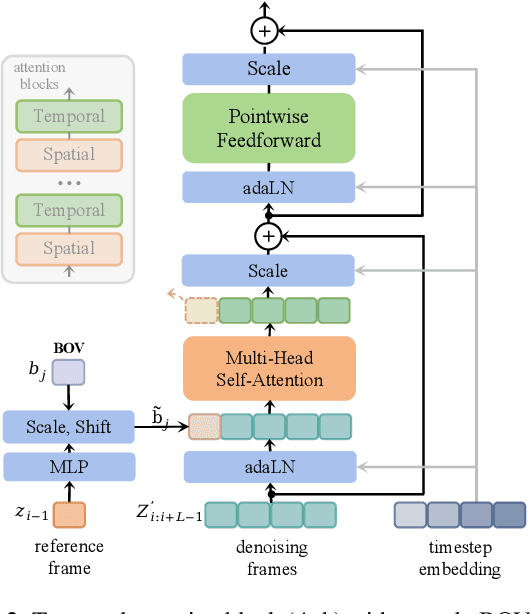
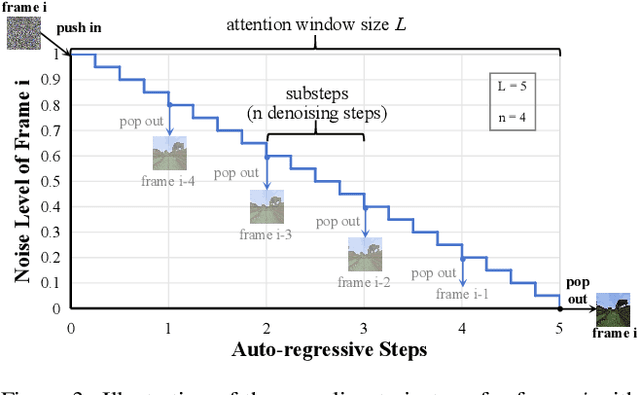

Recent advancements in diffusion-based video generation have produced impressive and high-fidelity short videos. To extend these successes to generate coherent long videos, most video diffusion models (VDMs) generate videos in an autoregressive manner, i.e., generating subsequent frames conditioned on previous ones. There are generally two primary paradigms: chunk-based extension and stream denoising. The former directly concatenates previous clean frames as conditioning, suffering from denoising latency and error accumulation. The latter maintains the denoising sequence with monotonically increasing noise levels. In each denoising iteration, one clean frame is produced while a new pure noise is simultaneously appended, enabling live-stream sampling. However, it struggles with fragile consistency and poor motion dynamics. In this paper, we propose Adaptive Begin-of-Video Tokens (ada-BOV) for autoregressive VDMs. The BOV tokens are special learnable embeddings on VDMs. They adaptively absorb denoised preceding frames via an adaptive-layer-norm-like modulation. This design preserves the global consistency while allowing for flexible conditioning in dynamic scenarios. To ensure the quality of local dynamics essential in modulating BOV tokens, we further propose a refinement strategy for stream denoising. It decouples the sampling trajectory length from the attention window size constraint, leading to improved local guidance and overall imaging quality. We also propose a disturbance-augmented training noise schedule, which balances the convergence speed with model robustness for the stream denoising. Extensive experiments demonstrate that our method achieves compelling qualitative and quantitative results across multiple metrics.
Generalized Visual Relation Detection with Diffusion Models
Apr 16, 2025Visual relation detection (VRD) aims to identify relationships (or interactions) between object pairs in an image. Although recent VRD models have achieved impressive performance, they are all restricted to pre-defined relation categories, while failing to consider the semantic ambiguity characteristic of visual relations. Unlike objects, the appearance of visual relations is always subtle and can be described by multiple predicate words from different perspectives, e.g., ``ride'' can be depicted as ``race'' and ``sit on'', from the sports and spatial position views, respectively. To this end, we propose to model visual relations as continuous embeddings, and design diffusion models to achieve generalized VRD in a conditional generative manner, termed Diff-VRD. We model the diffusion process in a latent space and generate all possible relations in the image as an embedding sequence. During the generation, the visual and text embeddings of subject-object pairs serve as conditional signals and are injected via cross-attention. After the generation, we design a subsequent matching stage to assign the relation words to subject-object pairs by considering their semantic similarities. Benefiting from the diffusion-based generative process, our Diff-VRD is able to generate visual relations beyond the pre-defined category labels of datasets. To properly evaluate this generalized VRD task, we introduce two evaluation metrics, i.e., text-to-image retrieval and SPICE PR Curve inspired by image captioning. Extensive experiments in both human-object interaction (HOI) detection and scene graph generation (SGG) benchmarks attest to the superiority and effectiveness of Diff-VRD.
Towards Better Alignment: Training Diffusion Models with Reinforcement Learning Against Sparse Rewards
Mar 14, 2025Diffusion models have achieved remarkable success in text-to-image generation. However, their practical applications are hindered by the misalignment between generated images and corresponding text prompts. To tackle this issue, reinforcement learning (RL) has been considered for diffusion model fine-tuning. Yet, RL's effectiveness is limited by the challenge of sparse reward, where feedback is only available at the end of the generation process. This makes it difficult to identify which actions during the denoising process contribute positively to the final generated image, potentially leading to ineffective or unnecessary denoising policies. To this end, this paper presents a novel RL-based framework that addresses the sparse reward problem when training diffusion models. Our framework, named $\text{B}^2\text{-DiffuRL}$, employs two strategies: \textbf{B}ackward progressive training and \textbf{B}ranch-based sampling. For one thing, backward progressive training focuses initially on the final timesteps of denoising process and gradually extends the training interval to earlier timesteps, easing the learning difficulty from sparse rewards. For another, we perform branch-based sampling for each training interval. By comparing the samples within the same branch, we can identify how much the policies of the current training interval contribute to the final image, which helps to learn effective policies instead of unnecessary ones. $\text{B}^2\text{-DiffuRL}$ is compatible with existing optimization algorithms. Extensive experiments demonstrate the effectiveness of $\text{B}^2\text{-DiffuRL}$ in improving prompt-image alignment and maintaining diversity in generated images. The code for this work is available.
Ca2-VDM: Efficient Autoregressive Video Diffusion Model with Causal Generation and Cache Sharing
Nov 25, 2024With the advance of diffusion models, today's video generation has achieved impressive quality. To extend the generation length and facilitate real-world applications, a majority of video diffusion models (VDMs) generate videos in an autoregressive manner, i.e., generating subsequent clips conditioned on the last frame(s) of the previous clip. However, existing autoregressive VDMs are highly inefficient and redundant: The model must re-compute all the conditional frames that are overlapped between adjacent clips. This issue is exacerbated when the conditional frames are extended autoregressively to provide the model with long-term context. In such cases, the computational demands increase significantly (i.e., with a quadratic complexity w.r.t. the autoregression step). In this paper, we propose Ca2-VDM, an efficient autoregressive VDM with Causal generation and Cache sharing. For causal generation, it introduces unidirectional feature computation, which ensures that the cache of conditional frames can be precomputed in previous autoregression steps and reused in every subsequent step, eliminating redundant computations. For cache sharing, it shares the cache across all denoising steps to avoid the huge cache storage cost. Extensive experiments demonstrated that our Ca2-VDM achieves state-of-the-art quantitative and qualitative video generation results and significantly improves the generation speed. Code is available at https://github.com/Dawn-LX/CausalCache-VDM
ViD-GPT: Introducing GPT-style Autoregressive Generation in Video Diffusion Models
Jun 16, 2024



With the advance of diffusion models, today's video generation has achieved impressive quality. But generating temporal consistent long videos is still challenging. A majority of video diffusion models (VDMs) generate long videos in an autoregressive manner, i.e., generating subsequent clips conditioned on last frames of previous clip. However, existing approaches all involve bidirectional computations, which restricts the receptive context of each autoregression step, and results in the model lacking long-term dependencies. Inspired from the huge success of large language models (LLMs) and following GPT (generative pre-trained transformer), we bring causal (i.e., unidirectional) generation into VDMs, and use past frames as prompt to generate future frames. For Causal Generation, we introduce causal temporal attention into VDM, which forces each generated frame to depend on its previous frames. For Frame as Prompt, we inject the conditional frames by concatenating them with noisy frames (frames to be generated) along the temporal axis. Consequently, we present Video Diffusion GPT (ViD-GPT). Based on the two key designs, in each autoregression step, it is able to acquire long-term context from prompting frames concatenated by all previously generated frames. Additionally, we bring the kv-cache mechanism to VDMs, which eliminates the redundant computation from overlapped frames, significantly boosting the inference speed. Extensive experiments demonstrate that our ViD-GPT achieves state-of-the-art performance both quantitatively and qualitatively on long video generation. Code will be available at https://github.com/Dawn-LX/Causal-VideoGen.
Triple Correlations-Guided Label Supplementation for Unbiased Video Scene Graph Generation
Jul 30, 2023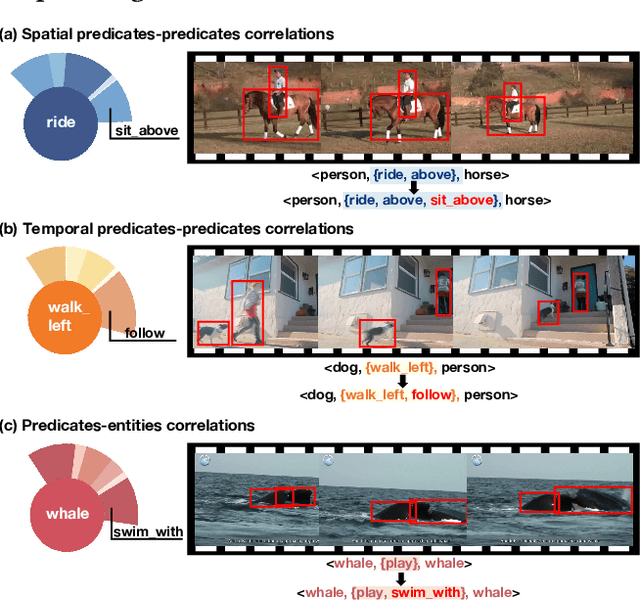

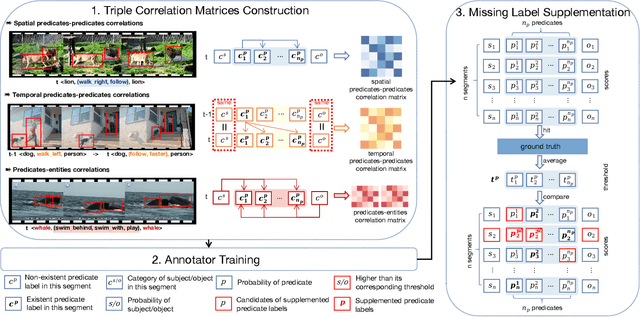
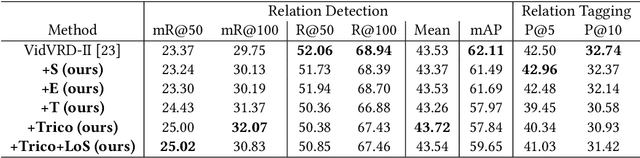
Video-based scene graph generation (VidSGG) is an approach that aims to represent video content in a dynamic graph by identifying visual entities and their relationships. Due to the inherently biased distribution and missing annotations in the training data, current VidSGG methods have been found to perform poorly on less-represented predicates. In this paper, we propose an explicit solution to address this under-explored issue by supplementing missing predicates that should be appear in the ground-truth annotations. Dubbed Trico, our method seeks to supplement the missing predicates by exploring three complementary spatio-temporal correlations. Guided by these correlations, the missing labels can be effectively supplemented thus achieving an unbiased predicate predictions. We validate the effectiveness of Trico on the most widely used VidSGG datasets, i.e., VidVRD and VidOR. Extensive experiments demonstrate the state-of-the-art performance achieved by Trico, particularly on those tail predicates.
Compositional Prompt Tuning with Motion Cues for Open-vocabulary Video Relation Detection
Feb 01, 2023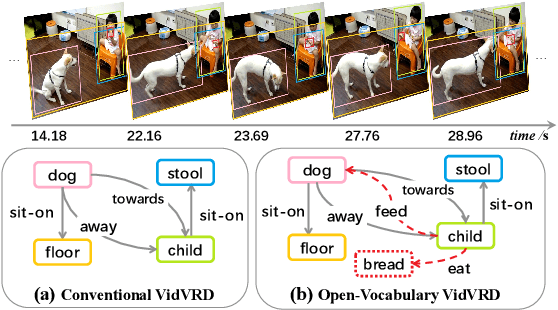
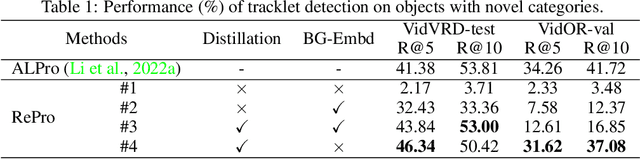

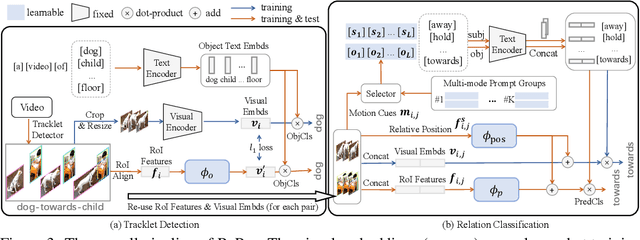
Prompt tuning with large-scale pretrained vision-language models empowers open-vocabulary predictions trained on limited base categories, e.g., object classification and detection. In this paper, we propose compositional prompt tuning with motion cues: an extended prompt tuning paradigm for compositional predictions of video data. In particular, we present Relation Prompt (RePro) for Open-vocabulary Video Visual Relation Detection (Open-VidVRD), where conventional prompt tuning is easily biased to certain subject-object combinations and motion patterns. To this end, RePro addresses the two technical challenges of Open-VidVRD: 1) the prompt tokens should respect the two different semantic roles of subject and object, and 2) the tuning should account for the diverse spatio-temporal motion patterns of the subject-object compositions. Without bells and whistles, our RePro achieves a new state-of-the-art performance on two VidVRD benchmarks of not only the base training object and predicate categories, but also the unseen ones. Extensive ablations also demonstrate the effectiveness of the proposed compositional and multi-mode design of prompts. Code is available at https://github.com/Dawn-LX/OpenVoc-VidVRD.
Rethinking Multi-Modal Alignment in Video Question Answering from Feature and Sample Perspectives
Apr 25, 2022
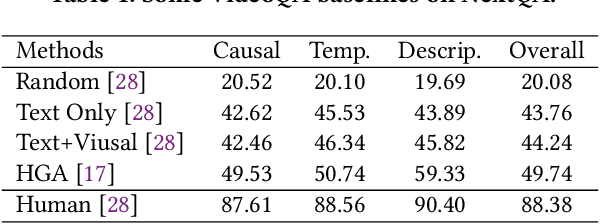
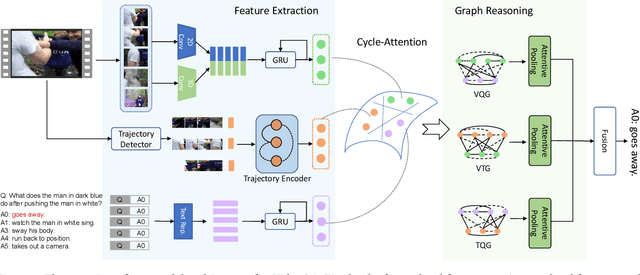
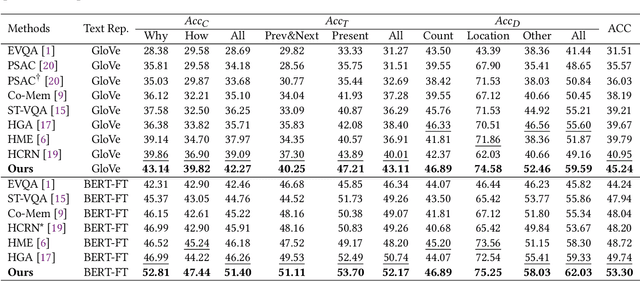
Reasoning about causal and temporal event relations in videos is a new destination of Video Question Answering (VideoQA).The major stumbling block to achieve this purpose is the semantic gap between language and video since they are at different levels of abstraction. Existing efforts mainly focus on designing sophisticated architectures while utilizing frame- or object-level visual representations. In this paper, we reconsider the multi-modal alignment problem in VideoQA from feature and sample perspectives to achieve better performance. From the view of feature,we break down the video into trajectories and first leverage trajectory feature in VideoQA to enhance the alignment between two modalities. Moreover, we adopt a heterogeneous graph architecture and design a hierarchical framework to align both trajectory-level and frame-level visual feature with language feature. In addition, we found that VideoQA models are largely dependent on language priors and always neglect visual-language interactions. Thus, two effective yet portable training augmentation strategies are designed to strengthen the cross-modal correspondence ability of our model from the view of sample. Extensive results show that our method outperforms all the state-of-the-art models on the challenging NExT-QA benchmark, which demonstrates the effectiveness of the proposed method.
Classification-Then-Grounding: Reformulating Video Scene Graphs as Temporal Bipartite Graphs
Dec 08, 2021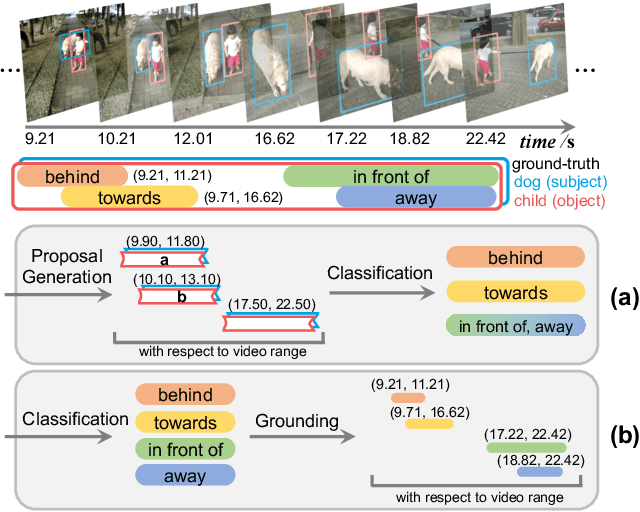
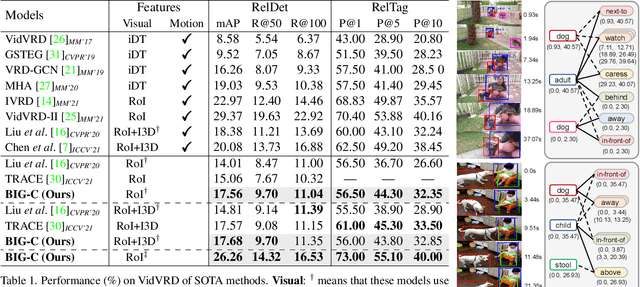
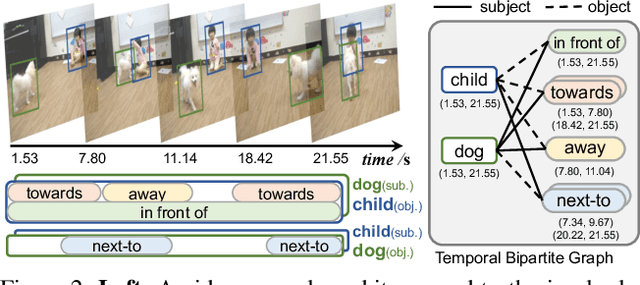
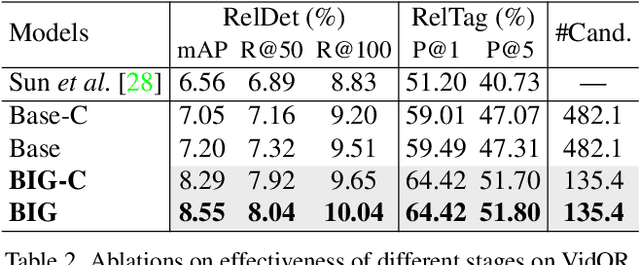
Today's VidSGG models are all proposal-based methods, i.e., they first generate numerous paired subject-object snippets as proposals, and then conduct predicate classification for each proposal. In this paper, we argue that this prevalent proposal-based framework has three inherent drawbacks: 1) The ground-truth predicate labels for proposals are partially correct. 2) They break the high-order relations among different predicate instances of a same subject-object pair. 3) VidSGG performance is upper-bounded by the quality of the proposals. To this end, we propose a new classification-then-grounding framework for VidSGG, which can avoid all the three overlooked drawbacks. Meanwhile, under this framework, we reformulate the video scene graphs as temporal bipartite graphs, where the entities and predicates are two types of nodes with time slots, and the edges denote different semantic roles between these nodes. This formulation takes full advantage of our new framework. Accordingly, we further propose a novel BIpartite Graph based SGG model: BIG. Specifically, BIG consists of two parts: a classification stage and a grounding stage, where the former aims to classify the categories of all the nodes and the edges, and the latter tries to localize the temporal location of each relation instance. Extensive ablations on two VidSGG datasets have attested to the effectiveness of our framework and BIG.
Video Relation Detection via Tracklet based Visual Transformer
Aug 19, 2021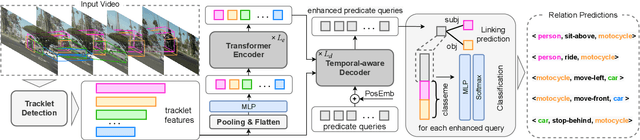

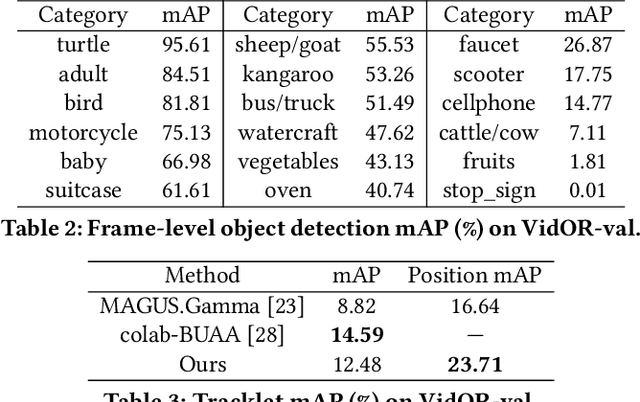
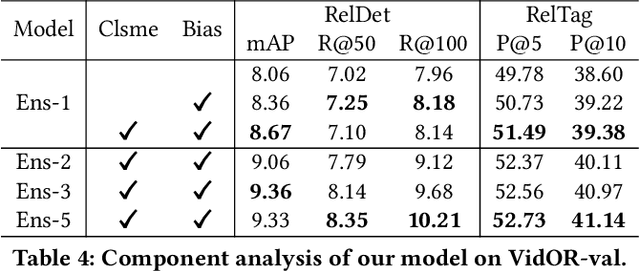
Video Visual Relation Detection (VidVRD), has received significant attention of our community over recent years. In this paper, we apply the state-of-the-art video object tracklet detection pipeline MEGA and deepSORT to generate tracklet proposals. Then we perform VidVRD in a tracklet-based manner without any pre-cutting operations. Specifically, we design a tracklet-based visual Transformer. It contains a temporal-aware decoder which performs feature interactions between the tracklets and learnable predicate query embeddings, and finally predicts the relations. Experimental results strongly demonstrate the superiority of our method, which outperforms other methods by a large margin on the Video Relation Understanding (VRU) Grand Challenge in ACM Multimedia 2021. Codes are released at https://github.com/Dawn-LX/VidVRD-tracklets.