 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriple Correlations-Guided Label Supplementation for Unbiased Video Scene Graph Generation
Paper and Code
Jul 30, 2023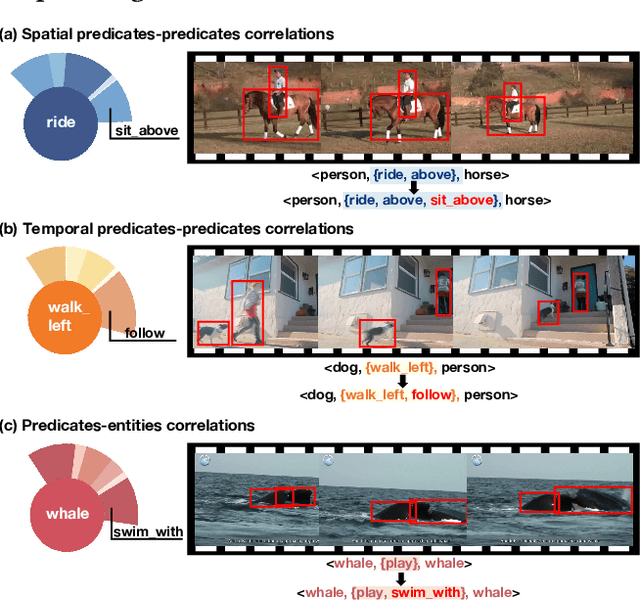

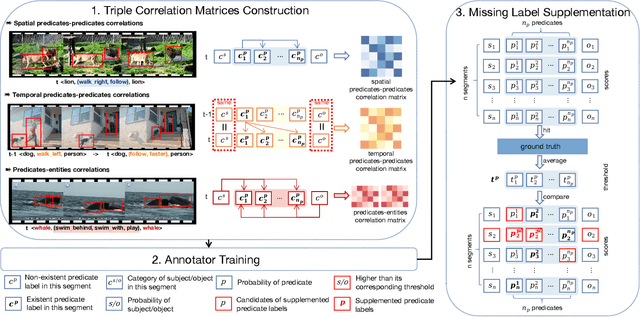
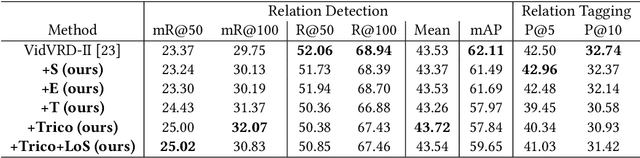
Video-based scene graph generation (VidSGG) is an approach that aims to represent video content in a dynamic graph by identifying visual entities and their relationships. Due to the inherently biased distribution and missing annotations in the training data, current VidSGG methods have been found to perform poorly on less-represented predicates. In this paper, we propose an explicit solution to address this under-explored issue by supplementing missing predicates that should be appear in the ground-truth annotations. Dubbed Trico, our method seeks to supplement the missing predicates by exploring three complementary spatio-temporal correlations. Guided by these correlations, the missing labels can be effectively supplemented thus achieving an unbiased predicate predictions. We validate the effectiveness of Trico on the most widely used VidSGG datasets, i.e., VidVRD and VidOR. Extensive experiments demonstrate the state-of-the-art performance achieved by Trico, particularly on those tail predicates.