 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInftyThink+: Effective and Efficient Infinite-Horizon Reasoning via Reinforcement Learning
Feb 09, 2026Large reasoning models achieve strong performance by scaling inference-time chain-of-thought, but this paradigm suffers from quadratic cost, context length limits, and degraded reasoning due to lost-in-the-middle effects. Iterative reasoning mitigates these issues by periodically summarizing intermediate thoughts, yet existing methods rely on supervised learning or fixed heuristics and fail to optimize when to summarize, what to preserve, and how to resume reasoning. We propose InftyThink+, an end-to-end reinforcement learning framework that optimizes the entire iterative reasoning trajectory, building on model-controlled iteration boundaries and explicit summarization. InftyThink+ adopts a two-stage training scheme with supervised cold-start followed by trajectory-level reinforcement learning, enabling the model to learn strategic summarization and continuation decisions. Experiments on DeepSeek-R1-Distill-Qwen-1.5B show that InftyThink+ improves accuracy by 21% on AIME24 and outperforms conventional long chain-of-thought reinforcement learning by a clear margin, while also generalizing better to out-of-distribution benchmarks. Moreover, InftyThink+ significantly reduces inference latency and accelerates reinforcement learning training, demonstrating improved reasoning efficiency alongside stronger performance.
Let LLMs Break Free from Overthinking via Self-Braking Tuning
May 21, 2025Large reasoning models (LRMs), such as OpenAI o1 and DeepSeek-R1, have significantly enhanced their reasoning capabilities by generating longer chains of thought, demonstrating outstanding performance across a variety of tasks. However, this performance gain comes at the cost of a substantial increase in redundant reasoning during the generation process, leading to high computational overhead and exacerbating the issue of overthinking. Although numerous existing approaches aim to address the problem of overthinking, they often rely on external interventions. In this paper, we propose a novel framework, Self-Braking Tuning (SBT), which tackles overthinking from the perspective of allowing the model to regulate its own reasoning process, thus eliminating the reliance on external control mechanisms. We construct a set of overthinking identification metrics based on standard answers and design a systematic method to detect redundant reasoning. This method accurately identifies unnecessary steps within the reasoning trajectory and generates training signals for learning self-regulation behaviors. Building on this foundation, we develop a complete strategy for constructing data with adaptive reasoning lengths and introduce an innovative braking prompt mechanism that enables the model to naturally learn when to terminate reasoning at an appropriate point. Experiments across mathematical benchmarks (AIME, AMC, MATH500, GSM8K) demonstrate that our method reduces token consumption by up to 60% while maintaining comparable accuracy to unconstrained models.
VerifyBench: Benchmarking Reference-based Reward Systems for Large Language Models
May 21, 2025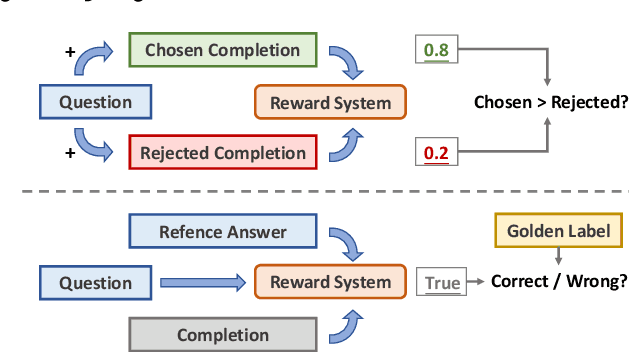
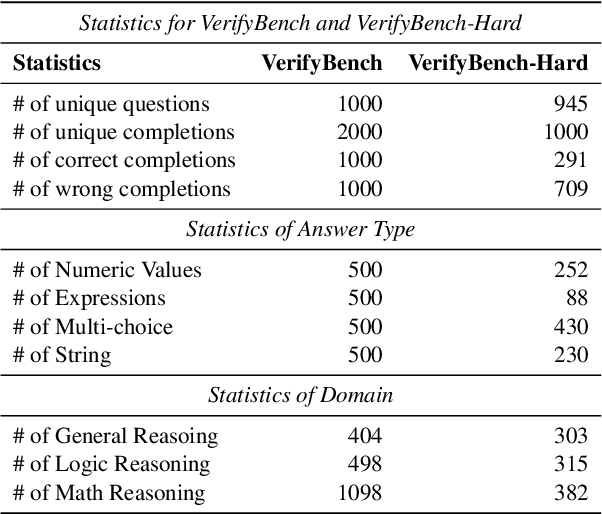
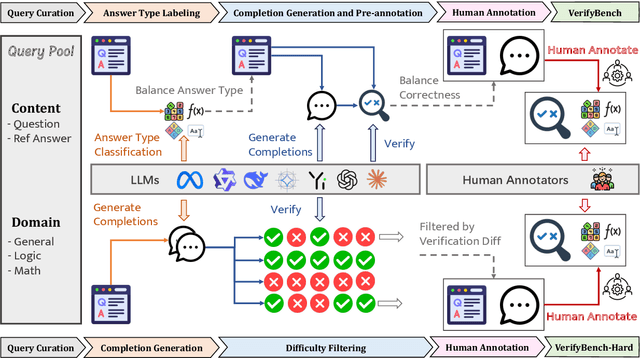
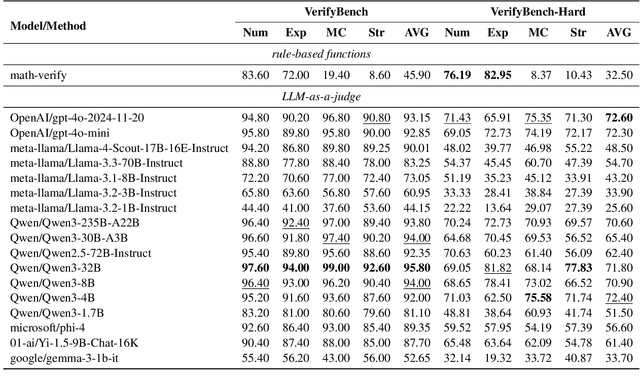
Large reasoning models such as OpenAI o1 and DeepSeek-R1 have achieved remarkable performance in the domain of reasoning. A key component of their training is the incorporation of verifiable rewards within reinforcement learning (RL). However, existing reward benchmarks do not evaluate reference-based reward systems, leaving researchers with limited understanding of the accuracy of verifiers used in RL. In this paper, we introduce two benchmarks, VerifyBench and VerifyBench-Hard, designed to assess the performance of reference-based reward systems. These benchmarks are constructed through meticulous data collection and curation, followed by careful human annotation to ensure high quality. Current models still show considerable room for improvement on both VerifyBench and VerifyBench-Hard, especially smaller-scale models. Furthermore, we conduct a thorough and comprehensive analysis of evaluation results, offering insights for understanding and developing reference-based reward systems. Our proposed benchmarks serve as effective tools for guiding the development of verifier accuracy and the reasoning capabilities of models trained via RL in reasoning tasks.
Structural-Temporal Coupling Anomaly Detection with Dynamic Graph Transformer
May 13, 2025Detecting anomalous edges in dynamic graphs is an important task in many applications over evolving triple-based data, such as social networks, transaction management, and epidemiology. A major challenge with this task is the absence of structural-temporal coupling information, which decreases the ability of the representation to distinguish anomalies from normal instances. Existing methods focus on handling independent structural and temporal features with embedding models, which ignore the deep interaction between these two types of information. In this paper, we propose a structural-temporal coupling anomaly detection architecture with a dynamic graph transformer model. Specifically, we introduce structural and temporal features from two integration levels to provide anomaly-aware graph evolutionary patterns. Then, a dynamic graph transformer enhanced by two-dimensional positional encoding is implemented to capture both discrimination and contextual consistency signals. Extensive experiments on six datasets demonstrate that our method outperforms current state-of-the-art models. Finally, a case study illustrates the strength of our method when applied to a real-world task.
InftyThink: Breaking the Length Limits of Long-Context Reasoning in Large Language Models
Mar 09, 2025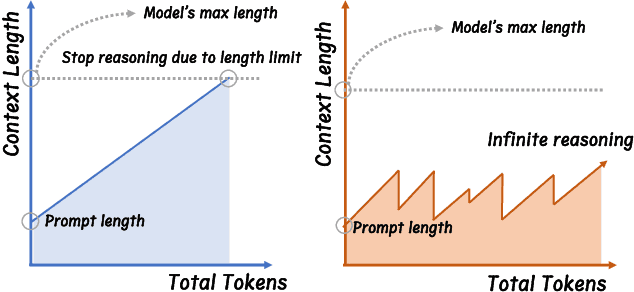



Advanced reasoning in large language models has achieved remarkable performance on challenging tasks, but the prevailing long-context reasoning paradigm faces critical limitations: quadratic computational scaling with sequence length, reasoning constrained by maximum context boundaries, and performance degradation beyond pre-training context windows. Existing approaches primarily compress reasoning chains without addressing the fundamental scaling problem. To overcome these challenges, we introduce InftyThink, a paradigm that transforms monolithic reasoning into an iterative process with intermediate summarization. By interleaving short reasoning segments with concise progress summaries, our approach enables unbounded reasoning depth while maintaining bounded computational costs. This creates a characteristic sawtooth memory pattern that significantly reduces computational complexity compared to traditional approaches. Furthermore, we develop a methodology for reconstructing long-context reasoning datasets into our iterative format, transforming OpenR1-Math into 333K training instances. Experiments across multiple model architectures demonstrate that our approach reduces computational costs while improving performance, with Qwen2.5-Math-7B showing 3-13% improvements across MATH500, AIME24, and GPQA_diamond benchmarks. Our work challenges the assumed trade-off between reasoning depth and computational efficiency, providing a more scalable approach to complex reasoning without architectural modifications.
MathFimer: Enhancing Mathematical Reasoning by Expanding Reasoning Steps through Fill-in-the-Middle Task
Feb 17, 2025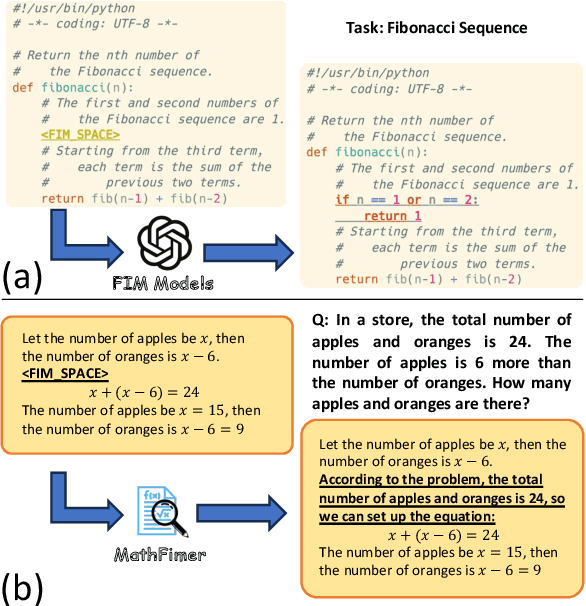
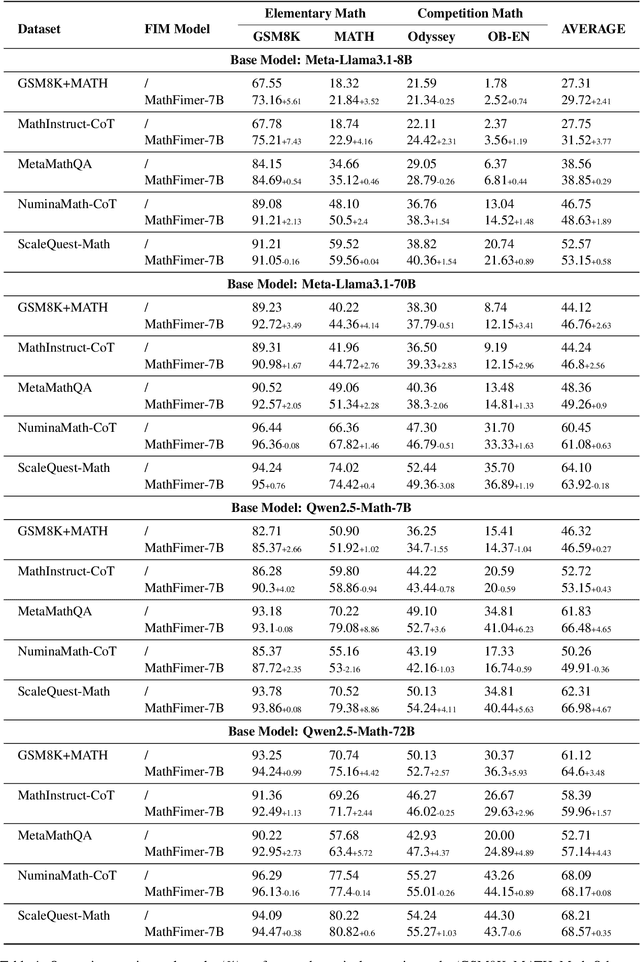
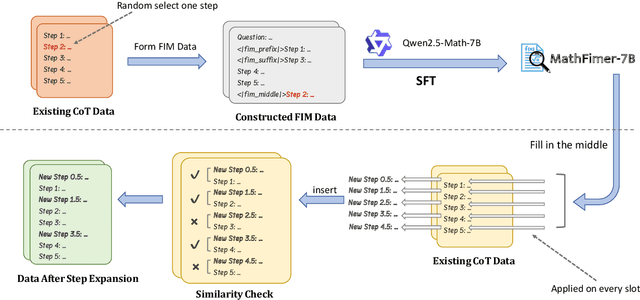
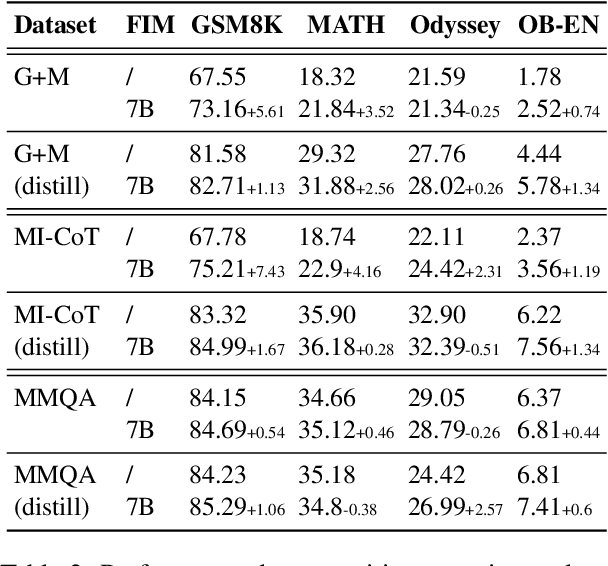
Mathematical reasoning represents a critical frontier in advancing large language models (LLMs). While step-by-step approaches have emerged as the dominant paradigm for mathematical problem-solving in LLMs, the quality of reasoning steps in training data fundamentally constrains the performance of the models. Recent studies has demonstrated that more detailed intermediate steps can enhance model performance, yet existing methods for step expansion either require more powerful external models or incur substantial computational costs. In this paper, we introduce MathFimer, a novel framework for mathematical reasoning step expansion inspired by the "Fill-in-the-middle" task from code completion. By decomposing solution chains into prefix-suffix pairs and training models to reconstruct missing intermediate steps, we develop a specialized model, MathFimer-7B, on our carefully curated NuminaMath-FIM dataset. We then apply these models to enhance existing mathematical reasoning datasets by inserting detailed intermediate steps into their solution chains, creating MathFimer-expanded versions. Through comprehensive experiments on multiple mathematical reasoning datasets, including MathInstruct, MetaMathQA and etc., we demonstrate that models trained on MathFimer-expanded data consistently outperform their counterparts trained on original data across various benchmarks such as GSM8K and MATH. Our approach offers a practical, scalable solution for enhancing mathematical reasoning capabilities in LLMs without relying on powerful external models or expensive inference procedures.
S$^3$c-Math: Spontaneous Step-level Self-correction Makes Large Language Models Better Mathematical Reasoners
Sep 03, 2024



Self-correction is a novel method that can stimulate the potential reasoning abilities of large language models (LLMs). It involves detecting and correcting errors during the inference process when LLMs solve reasoning problems. However, recent works do not regard self-correction as a spontaneous and intrinsic capability of LLMs. Instead, such correction is achieved through post-hoc generation, external knowledge introduction, multi-model collaboration, and similar techniques. In this paper, we propose a series of mathematical LLMs called S$^3$c-Math, which are able to perform Spontaneous Step-level Self-correction for Mathematical reasoning. This capability helps LLMs to recognize whether their ongoing inference tends to contain errors and simultaneously correct these errors to produce a more reliable response. We proposed a method, which employs a step-level sampling approach to construct step-wise self-correction data for achieving such ability. Additionally, we implement a training strategy that uses above constructed data to equip LLMs with spontaneous step-level self-correction capacities. Our data and methods have been demonstrated to be effective across various foundation LLMs, consistently showing significant progress in evaluations on GSM8K, MATH, and other mathematical benchmarks. To the best of our knowledge, we are the first to introduce the spontaneous step-level self-correction ability of LLMs in mathematical reasoning.
Stock Movement Prediction with Multimodal Stable Fusion via Gated Cross-Attention Mechanism
Jun 06, 2024



The accurate prediction of stock movements is crucial for investment strategies. Stock prices are subject to the influence of various forms of information, including financial indicators, sentiment analysis, news documents, and relational structures. Predominant analytical approaches, however, tend to address only unimodal or bimodal sources, neglecting the complexity of multimodal data. Further complicating the landscape are the issues of data sparsity and semantic conflicts between these modalities, which are frequently overlooked by current models, leading to unstable performance and limiting practical applicability. To address these shortcomings, this study introduces a novel architecture, named Multimodal Stable Fusion with Gated Cross-Attention (MSGCA), designed to robustly integrate multimodal input for stock movement prediction. The MSGCA framework consists of three integral components: (1) a trimodal encoding module, responsible for processing indicator sequences, dynamic documents, and a relational graph, and standardizing their feature representations; (2) a cross-feature fusion module, where primary and consistent features guide the multimodal fusion of the three modalities via a pair of gated cross-attention networks; and (3) a prediction module, which refines the fused features through temporal and dimensional reduction to execute precise movement forecasting. Empirical evaluations demonstrate that the MSGCA framework exceeds current leading methods, achieving performance gains of 8.1%, 6.1%, 21.7% and 31.6% on four multimodal datasets, respectively, attributed to its enhanced multimodal fusion stability.
ProSwitch: Knowledge-Guided Language Model Fine-Tuning to Generate Professional and Non-Professional Styled Text
Mar 27, 2024



Large Language Models (LLMs) have demonstrated efficacy in various linguistic applications, including text summarization and controlled text generation. However, studies into their capacity of switching between styles via fine-tuning remain underexplored. This study concentrates on textual professionalism and introduces a novel methodology, named ProSwitch, which equips a language model with the ability to produce both professional and non-professional responses through knowledge-guided instruction tuning. ProSwitch unfolds across three phases: data preparation for gathering domain knowledge and training corpus; instruction tuning for optimizing language models with multiple levels of instruction formats; and comprehensive evaluation for assessing the professionalism discrimination and reference-based quality of generated text. Comparative analysis of ProSwitch against both general and specialized language models reveals that our approach outperforms baselines in switching between professional and non-professional text generation.
Triad: A Framework Leveraging a Multi-Role LLM-based Agent to Solve Knowledge Base Question Answering
Feb 22, 2024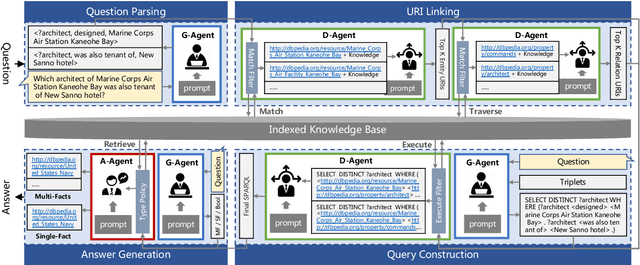

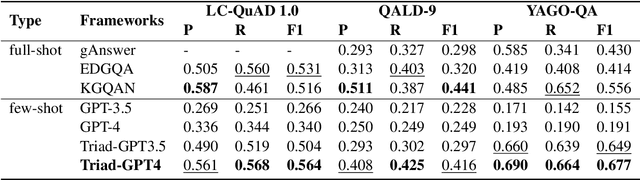
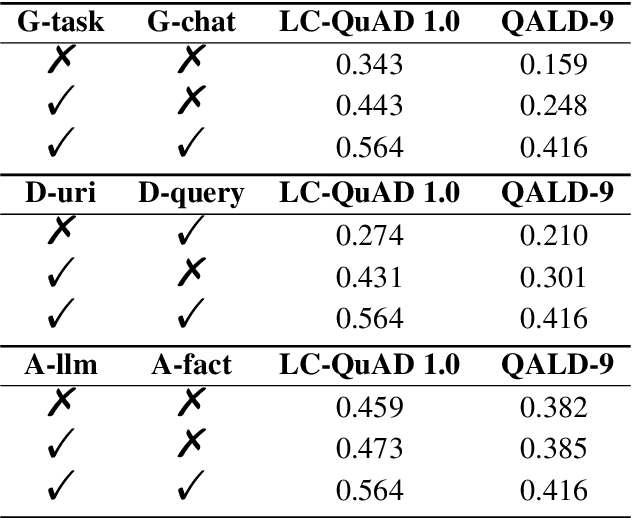
Recent progress with LLM-based agents has shown promising results across various tasks. However, their use in answering questions from knowledge bases remains largely unexplored. Implementing a KBQA system using traditional methods is challenging due to the shortage of task-specific training data and the complexity of creating task-focused model structures. In this paper, we present Triad, a unified framework that utilizes an LLM-based agent with three roles for KBQA tasks. The agent is assigned three roles to tackle different KBQA subtasks: agent as a generalist for mastering various subtasks, as a decision maker for the selection of candidates, and as an advisor for answering questions with knowledge. Our KBQA framework is executed in four phases, involving the collaboration of the agent's multiple roles. We evaluated the performance of our framework using three benchmark datasets, and the results show that our framework outperforms state-of-the-art systems on the LC-QuAD and YAGO-QA benchmarks, yielding F1 scores of 11.8% and 20.7%, respectively.