 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForesight Optimization for Strategic Reasoning in Large Language Models
Apr 16, 2026Reasoning capabilities in large language models (LLMs) have generally advanced significantly. However, it is still challenging for existing reasoning-based LLMs to perform effective decision-making abilities in multi-agent environments, due to the absence of explicit foresight modeling. To this end, strategic reasoning, the most fundamental capability to anticipate the counterpart's behaviors and foresee its possible future actions, has been introduced to alleviate the above issues. Strategic reasoning is fundamental to effective decision-making in multi-agent environments, yet existing reasoning enhancement methods for LLMs do not explicitly capture its foresight nature. In this work, we introduce Foresight Policy Optimization (FoPO) to enhance strategic reasoning in LLMs, which integrates opponent modeling principles into policy optimization, thereby enabling explicit consideration of both self-interest and counterpart influence. Specifically, we construct two curated datasets, namely Cooperative RSA and Competitive Taboo, equipped with well-designed rules and moderate difficulty to facilitate a systematic investigation of FoPO in a self-play framework. Our experiments demonstrate that FoPO significantly enhances strategic reasoning across LLMs of varying sizes and origins. Moreover, models trained with FoPO exhibit strong generalization to out-of-domain strategic scenarios, substantially outperforming standard LLM reasoning optimization baselines.
UI-Copilot: Advancing Long-Horizon GUI Automation via Tool-Integrated Policy Optimization
Apr 15, 2026MLLM-based GUI agents have demonstrated strong capabilities in complex user interface interaction tasks. However, long-horizon scenarios remain challenging, as these agents are burdened with tasks beyond their intrinsic capabilities, suffering from memory degradation, progress confusion, and math hallucination. To address these challenges, we present UI-Copilot, a collaborative framework where the GUI agent focuses on task execution while a lightweight copilot provides on-demand assistance for memory retrieval and numerical computation. We introduce memory decoupling to separate persistent observations from transient execution context, and train the policy agent to selectively invoke the copilot as Retriever or Calculator based on task demands. To enable effective tool invocation learning, we propose Tool-Integrated Policy Optimization (TIPO), which separately optimizes tool selection through single-turn prediction and task execution through on-policy multi-turn rollouts. Experimental results show that UI-Copilot-7B achieves state-of-the-art performance on challenging MemGUI-Bench, outperforming strong 7B-scale GUI agents such as GUI-Owl-7B and UI-TARS-1.5-7B. Moreover, UI-Copilot-7B delivers a 17.1% absolute improvement on AndroidWorld over the base Qwen model, highlighting UI-Copilot's strong generalization to real-world GUI tasks.
Reward Hacking in the Era of Large Models: Mechanisms, Emergent Misalignment, Challenges
Apr 15, 2026Reinforcement Learning from Human Feedback (RLHF) and related alignment paradigms have become central to steering large language models (LLMs) and multimodal large language models (MLLMs) toward human-preferred behaviors. However, these approaches introduce a systemic vulnerability: reward hacking, where models exploit imperfections in learned reward signals to maximize proxy objectives without fulfilling true task intent. As models scale and optimization intensifies, such exploitation manifests as verbosity bias, sycophancy, hallucinated justification, benchmark overfitting, and, in multimodal settings, perception--reasoning decoupling and evaluator manipulation. Recent evidence further suggests that seemingly benign shortcut behaviors can generalize into broader forms of misalignment, including deception and strategic gaming of oversight mechanisms. In this survey, we propose the Proxy Compression Hypothesis (PCH) as a unifying framework for understanding reward hacking. We formalize reward hacking as an emergent consequence of optimizing expressive policies against compressed reward representations of high-dimensional human objectives. Under this view, reward hacking arises from the interaction of objective compression, optimization amplification, and evaluator--policy co-adaptation. This perspective unifies empirical phenomena across RLHF, RLAIF, and RLVR regimes, and explains how local shortcut learning can generalize into broader forms of misalignment, including deception and strategic manipulation of oversight mechanisms. We further organize detection and mitigation strategies according to how they intervene on compression, amplification, or co-adaptation dynamics. By framing reward hacking as a structural instability of proxy-based alignment under scale, we highlight open challenges in scalable oversight, multimodal grounding, and agentic autonomy.
KnowU-Bench: Towards Interactive, Proactive, and Personalized Mobile Agent Evaluation
Apr 09, 2026Personalized mobile agents that infer user preferences and calibrate proactive assistance hold great promise as everyday digital assistants, yet existing benchmarks fail to capture what this requires. Prior work evaluates preference recovery from static histories or intent prediction from fixed contexts. Neither tests whether an agent can elicit missing preferences through interaction, nor whether it can decide when to intervene, seek consent, or remain silent in a live GUI environment. We introduce KnowU-Bench, an online benchmark for personalized mobile agents built on a reproducible Android emulation environment, covering 42 general GUI tasks, 86 personalized tasks, and 64 proactive tasks. Unlike prior work that treats user preferences as static context, KnowU-Bench hides the user profile from the agent and exposes only behavioral logs, forcing genuine preference inference rather than context lookup. To support multi-turn preference elicitation, it instantiates an LLM-driven user simulator grounded in structured profiles, enabling realistic clarification dialogues and proactive consent handling. Beyond personalization, KnowU-Bench provides comprehensive evaluation of the complete proactive decision chain, including grounded GUI execution, consent negotiation, and post-rejection restraint, evaluated through a hybrid protocol combining rule-based verification with LLM-as-a-Judge scoring. Our experiments reveal a striking degradation: agents that excel at explicit task execution fall below 50% under vague instructions requiring user preference inference or intervention calibration, even for frontier models like Claude Sonnet 4.6. The core bottlenecks are not GUI navigation but preference acquisition and intervention calibration, exposing a fundamental gap between competent interface operation and trustworthy personal assistance.
Interpreting and Controlling LLM Reasoning through Integrated Policy Gradient
Feb 03, 2026Large language models (LLMs) demonstrate strong reasoning abilities in solving complex real-world problems. Yet, the internal mechanisms driving these complex reasoning behaviors remain opaque. Existing interpretability approaches targeting reasoning either identify components (e.g., neurons) correlated with special textual patterns, or rely on human-annotated contrastive pairs to derive control vectors. Consequently, current methods struggle to precisely localize complex reasoning mechanisms or capture sequential influence from model internal workings to the reasoning outputs. In this paper, built on outcome-oriented and sequential-influence-aware principles, we focus on identifying components that have sequential contribution to reasoning behavior where outcomes are cumulated by long-range effects. We propose Integrated Policy Gradient (IPG), a novel framework that attributes reasoning behaviors to model's inner components by propagating compound outcome-based signals such as post reasoning accuracy backward through model inference trajectories. Empirical evaluations demonstrate that our approach achieves more precise localization and enables reliable modulation of reasoning behaviors (e.g., reasoning capability, reasoning strength) across diverse reasoning models.
Controllable Memory Usage: Balancing Anchoring and Innovation in Long-Term Human-Agent Interaction
Jan 08, 2026As LLM-based agents are increasingly used in long-term interactions, cumulative memory is critical for enabling personalization and maintaining stylistic consistency. However, most existing systems adopt an ``all-or-nothing'' approach to memory usage: incorporating all relevant past information can lead to \textit{Memory Anchoring}, where the agent is trapped by past interactions, while excluding memory entirely results in under-utilization and the loss of important interaction history. We show that an agent's reliance on memory can be modeled as an explicit and user-controllable dimension. We first introduce a behavioral metric of memory dependence to quantify the influence of past interactions on current outputs. We then propose \textbf{Stee}rable \textbf{M}emory Agent, \texttt{SteeM}, a framework that allows users to dynamically regulate memory reliance, ranging from a fresh-start mode that promotes innovation to a high-fidelity mode that closely follows interaction history. Experiments across different scenarios demonstrate that our approach consistently outperforms conventional prompting and rigid memory masking strategies, yielding a more nuanced and effective control for personalized human-agent collaboration.
Trade in Minutes! Rationality-Driven Agentic System for Quantitative Financial Trading
Oct 06, 2025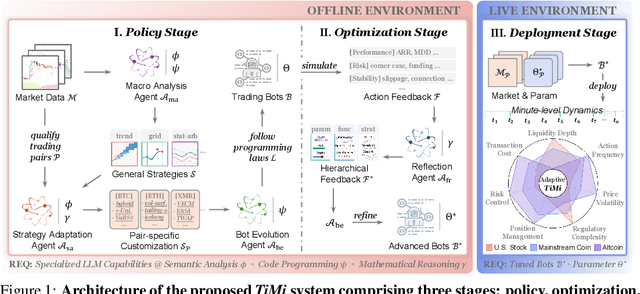
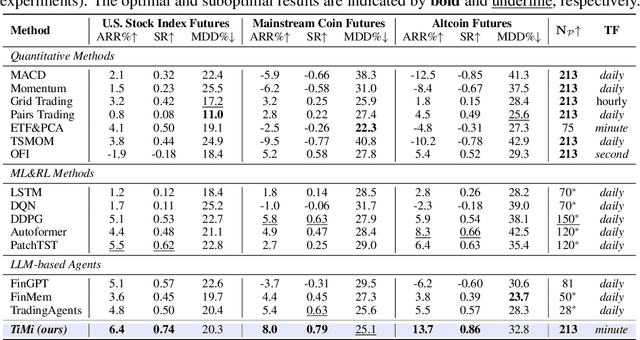
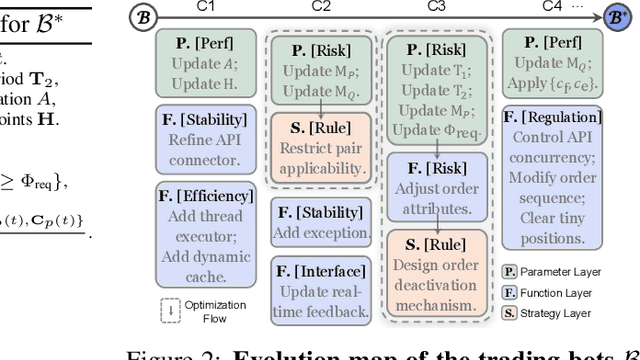
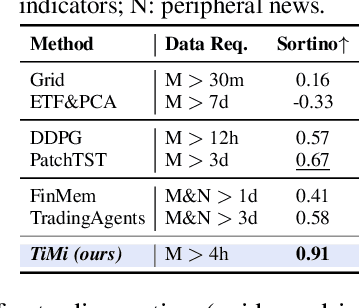
Recent advancements in large language models (LLMs) and agentic systems have shown exceptional decision-making capabilities, revealing significant potential for autonomic finance. Current financial trading agents predominantly simulate anthropomorphic roles that inadvertently introduce emotional biases and rely on peripheral information, while being constrained by the necessity for continuous inference during deployment. In this paper, we pioneer the harmonization of strategic depth in agents with the mechanical rationality essential for quantitative trading. Consequently, we present TiMi (Trade in Minutes), a rationality-driven multi-agent system that architecturally decouples strategy development from minute-level deployment. TiMi leverages specialized LLM capabilities of semantic analysis, code programming, and mathematical reasoning within a comprehensive policy-optimization-deployment chain. Specifically, we propose a two-tier analytical paradigm from macro patterns to micro customization, layered programming design for trading bot implementation, and closed-loop optimization driven by mathematical reflection. Extensive evaluations across 200+ trading pairs in stock and cryptocurrency markets empirically validate the efficacy of TiMi in stable profitability, action efficiency, and risk control under volatile market dynamics.
Linking Process to Outcome: Conditional Reward Modeling for LLM Reasoning
Sep 30, 2025Process Reward Models (PRMs) have emerged as a promising approach to enhance the reasoning capabilities of large language models (LLMs) by guiding their step-by-step reasoning toward a final answer. However, existing PRMs either treat each reasoning step in isolation, failing to capture inter-step dependencies, or struggle to align process rewards with the final outcome. Consequently, the reward signal fails to respect temporal causality in sequential reasoning and faces ambiguous credit assignment. These limitations make downstream models vulnerable to reward hacking and lead to suboptimal performance. In this work, we propose Conditional Reward Modeling (CRM) that frames LLM reasoning as a temporal process leading to a correct answer. The reward of each reasoning step is not only conditioned on the preceding steps but also explicitly linked to the final outcome of the reasoning trajectory. By enforcing conditional probability rules, our design captures the causal relationships among reasoning steps, with the link to the outcome allowing precise attribution of each intermediate step, thereby resolving credit assignment ambiguity. Further, through this consistent probabilistic modeling, the rewards produced by CRM enable more reliable cross-sample comparison. Experiments across Best-of-N sampling, beam search and reinforcement learning demonstrate that CRM consistently outperforms existing reward models, offering a principled framework for enhancing LLM reasoning. In particular, CRM is more robust to reward hacking and delivers stable downstream improvements without relying on verifiable rewards derived from ground truth.
Enhancing User Engagement in Socially-Driven Dialogue through Interactive LLM Alignments
Jun 26, 2025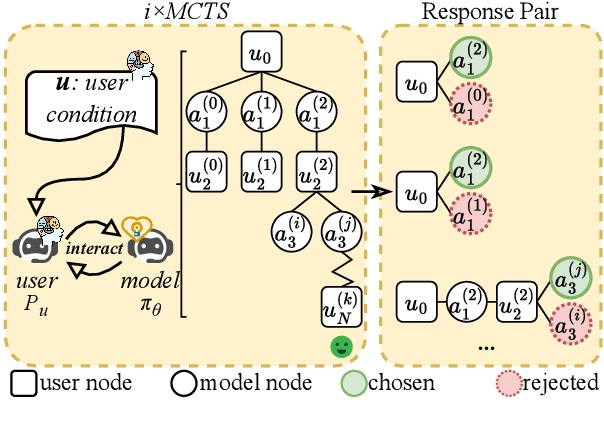

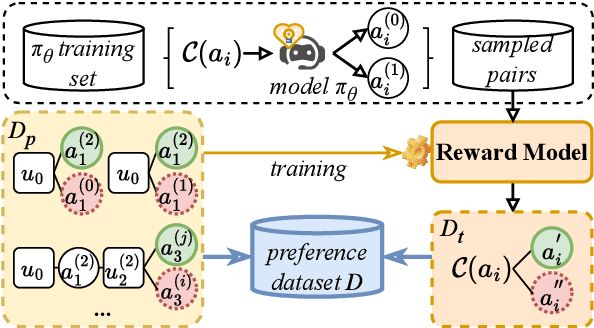

Enhancing user engagement through interactions plays an essential role in socially-driven dialogues. While prior works have optimized models to reason over relevant knowledge or plan a dialogue act flow, the relationship between user engagement and knowledge or dialogue acts is subtle and does not guarantee user engagement in socially-driven dialogues. To this end, we enable interactive LLMs to learn user engagement by leveraging signals from the future development of conversations. Specifically, we adopt a more direct and relevant indicator of user engagement, i.e., the user's reaction related to dialogue intention after the interaction, as a reward to align interactive LLMs. To achieve this, we develop a user simulator to interact with target interactive LLMs and explore interactions between the user and the interactive LLM system via \textit{i$\times$MCTS} (\textit{M}onte \textit{C}arlo \textit{T}ree \textit{S}earch for \textit{i}nteraction). In this way, we collect a dataset containing pairs of higher and lower-quality experiences using \textit{i$\times$MCTS}, and align interactive LLMs for high-level user engagement by direct preference optimization (DPO) accordingly. Experiments conducted on two socially-driven dialogue scenarios (emotional support conversations and persuasion for good) demonstrate that our method effectively enhances user engagement in interactive LLMs.
Mind the Gap: Bridging Thought Leap for Improved Chain-of-Thought Tuning
May 21, 2025Large language models (LLMs) have achieved remarkable progress on mathematical tasks through Chain-of-Thought (CoT) reasoning. However, existing mathematical CoT datasets often suffer from Thought Leaps due to experts omitting intermediate steps, which negatively impacts model learning and generalization. We propose the CoT Thought Leap Bridge Task, which aims to automatically detect leaps and generate missing intermediate reasoning steps to restore the completeness and coherence of CoT. To facilitate this, we constructed a specialized training dataset called ScaleQM+, based on the structured ScaleQuestMath dataset, and trained CoT-Bridge to bridge thought leaps. Through comprehensive experiments on mathematical reasoning benchmarks, we demonstrate that models fine-tuned on bridged datasets consistently outperform those trained on original datasets, with improvements of up to +5.87% on NuminaMath. Our approach effectively enhances distilled data (+3.02%) and provides better starting points for reinforcement learning (+3.1%), functioning as a plug-and-play module compatible with existing optimization techniques. Furthermore, CoT-Bridge demonstrate improved generalization to out-of-domain logical reasoning tasks, confirming that enhancing reasoning completeness yields broadly applicable benefits.