 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Confusion Expression in Large Language Models: Leveraging World Models toward Better Social Reasoning
Oct 09, 2025While large language models (LLMs) excel in mathematical and code reasoning, we observe they struggle with social reasoning tasks, exhibiting cognitive confusion, logical inconsistencies, and conflation between objective world states and subjective belief states. Through deteiled analysis of DeepSeek-R1's reasoning trajectories, we find that LLMs frequently encounter reasoning impasses and tend to output contradictory terms like "tricky" and "confused" when processing scenarios with multiple participants and timelines, leading to erroneous reasoning or infinite loops. The core issue is their inability to disentangle objective reality from agents' subjective beliefs. To address this, we propose an adaptive world model-enhanced reasoning mechanism that constructs a dynamic textual world model to track entity states and temporal sequences. It dynamically monitors reasoning trajectories for confusion indicators and promptly intervenes by providing clear world state descriptions, helping models navigate through cognitive dilemmas. The mechanism mimics how humans use implicit world models to distinguish between external events and internal beliefs. Evaluations on three social benchmarks demonstrate significant improvements in accuracy (e.g., +10% in Hi-ToM) while reducing computational costs (up to 33.8% token reduction), offering a simple yet effective solution for deploying LLMs in social contexts.
Cooper: Co-Optimizing Policy and Reward Models in Reinforcement Learning for Large Language Models
Aug 07, 2025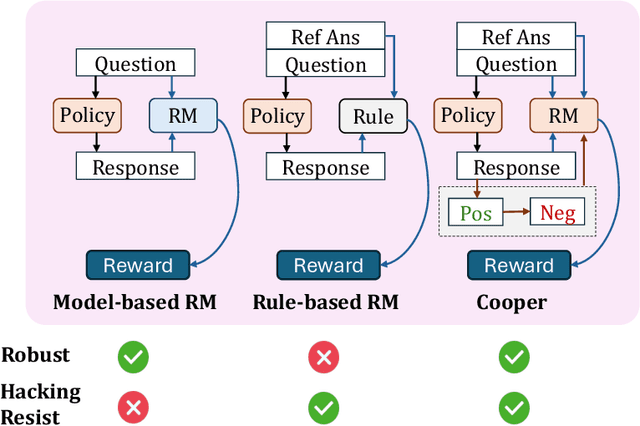



Large language models (LLMs) have demonstrated remarkable performance in reasoning tasks, where reinforcement learning (RL) serves as a key algorithm for enhancing their reasoning capabilities. Currently, there are two mainstream reward paradigms: model-based rewards and rule-based rewards. However, both approaches suffer from limitations: rule-based rewards lack robustness, while model-based rewards are vulnerable to reward hacking. To address these issues, we propose Cooper(Co-optimizing Policy Model and Reward Model), a RL framework that jointly optimizes both the policy model and the reward model. Cooper leverages the high precision of rule-based rewards when identifying correct responses, and dynamically constructs and selects positive-negative sample pairs for continued training the reward model. This design enhances robustness and mitigates the risk of reward hacking. To further support Cooper, we introduce a hybrid annotation strategy that efficiently and accurately generates training data for the reward model. We also propose a reference-based reward modeling paradigm, where the reward model takes a reference answer as input. Based on this design, we train a reward model named VerifyRM, which achieves higher accuracy on VerifyBench compared to other models of the same size. We conduct reinforcement learning using both VerifyRM and Cooper. Our experiments show that Cooper not only alleviates reward hacking but also improves end-to-end RL performance, for instance, achieving a 0.54% gain in average accuracy on Qwen2.5-1.5B-Instruct. Our findings demonstrate that dynamically updating reward model is an effective way to combat reward hacking, providing a reference for better integrating reward models into RL.
TimeHC-RL: Temporal-aware Hierarchical Cognitive Reinforcement Learning for Enhancing LLMs' Social Intelligence
May 30, 2025Recently, Large Language Models (LLMs) have made significant progress in IQ-related domains that require careful thinking, such as mathematics and coding. However, enhancing LLMs' cognitive development in social domains, particularly from a post-training perspective, remains underexplored. Recognizing that the social world follows a distinct timeline and requires a richer blend of cognitive modes (from intuitive reactions (System 1) and surface-level thinking to deliberate thinking (System 2)) than mathematics, which primarily relies on System 2 cognition (careful, step-by-step reasoning), we introduce Temporal-aware Hierarchical Cognitive Reinforcement Learning (TimeHC-RL) for enhancing LLMs' social intelligence. In our experiments, we systematically explore improving LLMs' social intelligence and validate the effectiveness of the TimeHC-RL method, through five other post-training paradigms and two test-time intervention paradigms on eight datasets with diverse data patterns. Experimental results reveal the superiority of our proposed TimeHC-RL method compared to the widely adopted System 2 RL method. It gives the 7B backbone model wings, enabling it to rival the performance of advanced models like DeepSeek-R1 and OpenAI-O3. Additionally, the systematic exploration from post-training and test-time interventions perspectives to improve LLMs' social intelligence has uncovered several valuable insights.
ViewSpatial-Bench: Evaluating Multi-perspective Spatial Localization in Vision-Language Models
May 27, 2025



Vision-language models (VLMs) have demonstrated remarkable capabilities in understanding and reasoning about visual content, but significant challenges persist in tasks requiring cross-viewpoint understanding and spatial reasoning. We identify a critical limitation: current VLMs excel primarily at egocentric spatial reasoning (from the camera's perspective) but fail to generalize to allocentric viewpoints when required to adopt another entity's spatial frame of reference. We introduce ViewSpatial-Bench, the first comprehensive benchmark designed specifically for multi-viewpoint spatial localization recognition evaluation across five distinct task types, supported by an automated 3D annotation pipeline that generates precise directional labels. Comprehensive evaluation of diverse VLMs on ViewSpatial-Bench reveals a significant performance disparity: models demonstrate reasonable performance on camera-perspective tasks but exhibit reduced accuracy when reasoning from a human viewpoint. By fine-tuning VLMs on our multi-perspective spatial dataset, we achieve an overall performance improvement of 46.24% across tasks, highlighting the efficacy of our approach. Our work establishes a crucial benchmark for spatial intelligence in embodied AI systems and provides empirical evidence that modeling 3D spatial relationships enhances VLMs' corresponding spatial comprehension capabilities.
Mind the Gap: Bridging Thought Leap for Improved Chain-of-Thought Tuning
May 21, 2025Large language models (LLMs) have achieved remarkable progress on mathematical tasks through Chain-of-Thought (CoT) reasoning. However, existing mathematical CoT datasets often suffer from Thought Leaps due to experts omitting intermediate steps, which negatively impacts model learning and generalization. We propose the CoT Thought Leap Bridge Task, which aims to automatically detect leaps and generate missing intermediate reasoning steps to restore the completeness and coherence of CoT. To facilitate this, we constructed a specialized training dataset called ScaleQM+, based on the structured ScaleQuestMath dataset, and trained CoT-Bridge to bridge thought leaps. Through comprehensive experiments on mathematical reasoning benchmarks, we demonstrate that models fine-tuned on bridged datasets consistently outperform those trained on original datasets, with improvements of up to +5.87% on NuminaMath. Our approach effectively enhances distilled data (+3.02%) and provides better starting points for reinforcement learning (+3.1%), functioning as a plug-and-play module compatible with existing optimization techniques. Furthermore, CoT-Bridge demonstrate improved generalization to out-of-domain logical reasoning tasks, confirming that enhancing reasoning completeness yields broadly applicable benefits.
Embodied-Reasoner: Synergizing Visual Search, Reasoning, and Action for Embodied Interactive Tasks
Mar 27, 2025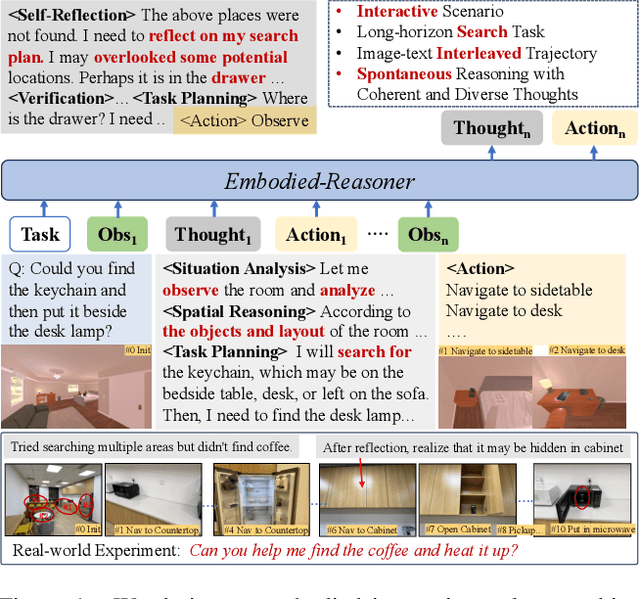

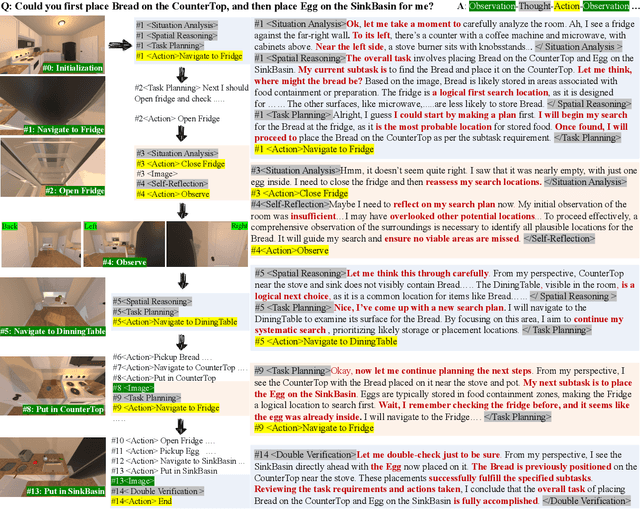
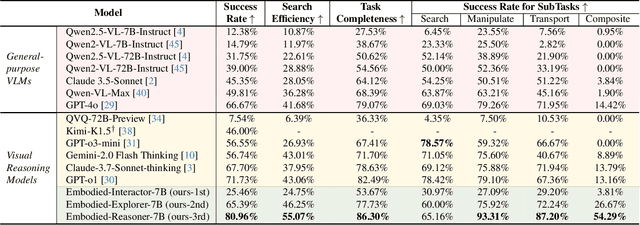
Recent advances in deep thinking models have demonstrated remarkable reasoning capabilities on mathematical and coding tasks. However, their effectiveness in embodied domains which require continuous interaction with environments through image action interleaved trajectories remains largely -unexplored. We present Embodied Reasoner, a model that extends o1 style reasoning to interactive embodied search tasks. Unlike mathematical reasoning that relies primarily on logical deduction, embodied scenarios demand spatial understanding, temporal reasoning, and ongoing self-reflection based on interaction history. To address these challenges, we synthesize 9.3k coherent Observation-Thought-Action trajectories containing 64k interactive images and 90k diverse thinking processes (analysis, spatial reasoning, reflection, planning, and verification). We develop a three-stage training pipeline that progressively enhances the model's capabilities through imitation learning, self-exploration via rejection sampling, and self-correction through reflection tuning. The evaluation shows that our model significantly outperforms those advanced visual reasoning models, e.g., it exceeds OpenAI o1, o3-mini, and Claude-3.7 by +9\%, 24\%, and +13\%. Analysis reveals our model exhibits fewer repeated searches and logical inconsistencies, with particular advantages in complex long-horizon tasks. Real-world environments also show our superiority while exhibiting fewer repeated searches and logical inconsistency cases.
Think Twice, Click Once: Enhancing GUI Grounding via Fast and Slow Systems
Mar 09, 2025Humans can flexibly switch between different modes of thinking based on task complexity: from rapid intuitive judgments to in-depth analytical understanding. However, current Graphical User Interface (GUI) grounding systems which locate interface elements based on natural language instructions rely solely on immediate prediction without reasoning, struggling to understand complex interface layouts with nested structures and hierarchical relationships, limiting their effectiveness on complex interfaces. Inspired by human dual-system cognition, we present Focus, a novel GUI grounding framework that combines fast prediction with systematic analysis. The framework dynamically switches between rapid and deliberate processing through an adaptive system switching based on task complexity, optimizing both efficiency and accuracy. Focus decomposes grounding into progressive stages: interface summarization, visual focused analysis, and precise coordinate prediction. This structured decomposition enables systematic understanding of both interface layouts and visual relationships. Extensive experiments show that Focus achieves state-of-the-art performance using only 300K of the training data with a 2B parameter model compared to existing approaches. Focus demonstrates superior performance particularly in complex GUI scenarios, achieving 77.4% average accuracy on ScreenSpot and 13.3% on the more challenging ScreenSpot-Pro. Our analysis reveals the effectiveness of this dual-system approach while demonstrating its potential for improving complex GUI interaction scenarios.
GaVaMoE: Gaussian-Variational Gated Mixture of Experts for Explainable Recommendation
Oct 15, 2024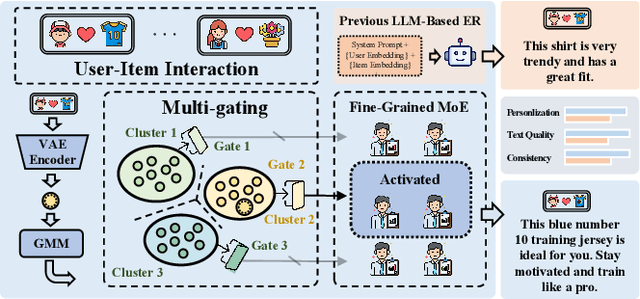
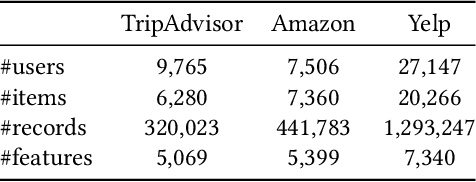
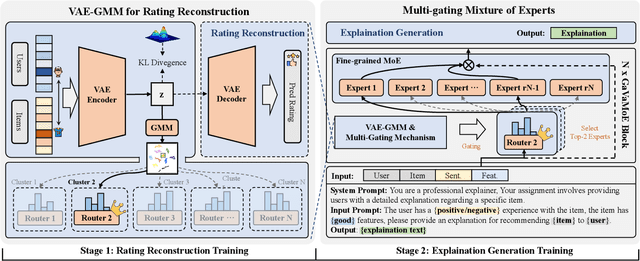
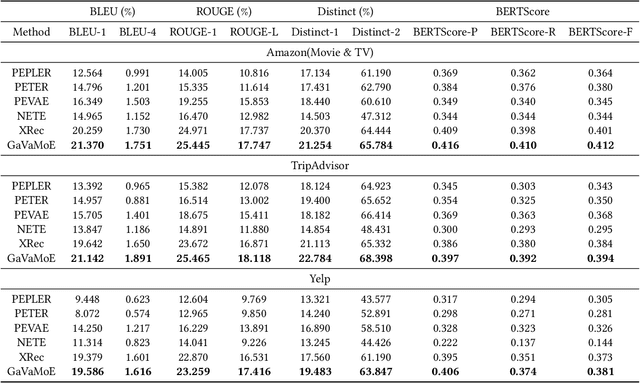
Large language model-based explainable recommendation (LLM-based ER) systems show promise in generating human-like explanations for recommendations. However, they face challenges in modeling user-item collaborative preferences, personalizing explanations, and handling sparse user-item interactions. To address these issues, we propose GaVaMoE, a novel Gaussian-Variational Gated Mixture of Experts framework for explainable recommendation. GaVaMoE introduces two key components: (1) a rating reconstruction module that employs Variational Autoencoder (VAE) with a Gaussian Mixture Model (GMM) to capture complex user-item collaborative preferences, serving as a pre-trained multi-gating mechanism; and (2) a set of fine-grained expert models coupled with the multi-gating mechanism for generating highly personalized explanations. The VAE component models latent factors in user-item interactions, while the GMM clusters users with similar behaviors. Each cluster corresponds to a gate in the multi-gating mechanism, routing user-item pairs to appropriate expert models. This architecture enables GaVaMoE to generate tailored explanations for specific user types and preferences, mitigating data sparsity by leveraging user similarities. Extensive experiments on three real-world datasets demonstrate that GaVaMoE significantly outperforms existing methods in explanation quality, personalization, and consistency. Notably, GaVaMoE exhibits robust performance in scenarios with sparse user-item interactions, maintaining high-quality explanations even for users with limited historical data.
Entering Real Social World! Benchmarking the Theory of Mind and Socialization Capabilities of LLMs from a First-person Perspective
Oct 08, 2024



In the social world, humans possess the capability to infer and reason about others mental states (such as emotions, beliefs, and intentions), known as the Theory of Mind (ToM). Simultaneously, humans own mental states evolve in response to social situations, a capability we refer to as socialization. Together, these capabilities form the foundation of human social interaction. In the era of artificial intelligence (AI), especially with the development of large language models (LLMs), we raise an intriguing question: How do LLMs perform in terms of ToM and socialization capabilities? And more broadly, can these AI models truly enter and navigate the real social world? Existing research evaluating LLMs ToM and socialization capabilities by positioning LLMs as passive observers from a third person perspective, rather than as active participants. However, compared to the third-person perspective, observing and understanding the world from an egocentric first person perspective is a natural approach for both humans and AI agents. The ToM and socialization capabilities of LLMs from a first person perspective, a crucial attribute for advancing embodied AI agents, remain unexplored. To answer the aforementioned questions and bridge the research gap, we introduce EgoSocialArena, a novel framework designed to evaluate and investigate the ToM and socialization capabilities of LLMs from a first person perspective. It encompasses two evaluation environments: static environment and interactive environment, with seven scenarios: Daily Life, Counterfactual, New World, Blackjack, Number Guessing, and Limit Texas Hold em, totaling 2,195 data entries. With EgoSocialArena, we have conducted a comprehensive evaluation of nine advanced LLMs and observed some key insights regarding the future development of LLMs as well as the capabilities levels of the most advanced LLMs currently available.
Multimodal Self-Instruct: Synthetic Abstract Image and Visual Reasoning Instruction Using Language Model
Jul 10, 2024
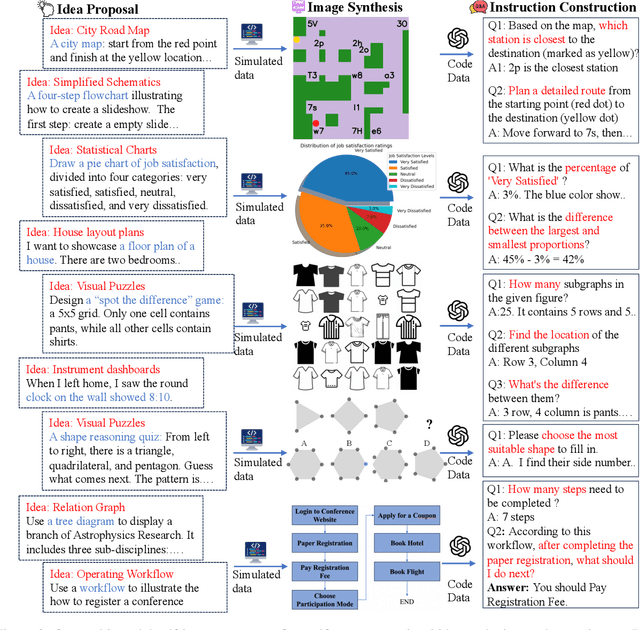
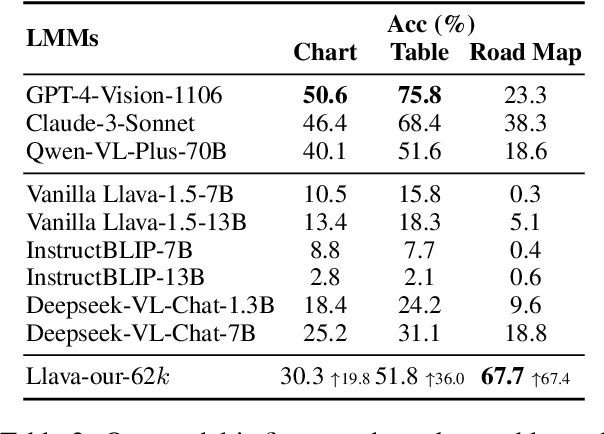
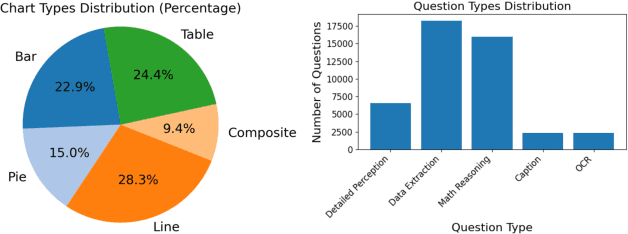
Although most current large multimodal models (LMMs) can already understand photos of natural scenes and portraits, their understanding of abstract images, e.g., charts, maps, or layouts, and visual reasoning capabilities remains quite rudimentary. They often struggle with simple daily tasks, such as reading time from a clock, understanding a flowchart, or planning a route using a road map. In light of this, we design a multi-modal self-instruct, utilizing large language models and their code capabilities to synthesize massive abstract images and visual reasoning instructions across daily scenarios. Our strategy effortlessly creates a multimodal benchmark with 11,193 instructions for eight visual scenarios: charts, tables, simulated maps, dashboards, flowcharts, relation graphs, floor plans, and visual puzzles. \textbf{This benchmark, constructed with simple lines and geometric elements, exposes the shortcomings of most advanced LMMs} like Claude-3.5-Sonnet and GPT-4o in abstract image understanding, spatial relations reasoning, and visual element induction. Besides, to verify the quality of our synthetic data, we fine-tune an LMM using 62,476 synthetic chart, table and road map instructions. The results demonstrate improved chart understanding and map navigation performance, and also demonstrate potential benefits for other visual reasoning tasks. Our code is available at: \url{https://github.com/zwq2018/Multi-modal-Self-instruct}.