 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Device Training of PV Power Forecasting Models in a Smart Meter for Grid Edge Intelligence
Jul 09, 2025In this paper, an edge-side model training study is conducted on a resource-limited smart meter. The motivation of grid-edge intelligence and the concept of on-device training are introduced. Then, the technical preparation steps for on-device training are described. A case study on the task of photovoltaic power forecasting is presented, where two representative machine learning models are investigated: a gradient boosting tree model and a recurrent neural network model. To adapt to the resource-limited situation in the smart meter, "mixed"- and "reduced"-precision training schemes are also devised. Experiment results demonstrate the feasibility of economically achieving grid-edge intelligence via the existing advanced metering infrastructures.
TimeHC-RL: Temporal-aware Hierarchical Cognitive Reinforcement Learning for Enhancing LLMs' Social Intelligence
May 30, 2025Recently, Large Language Models (LLMs) have made significant progress in IQ-related domains that require careful thinking, such as mathematics and coding. However, enhancing LLMs' cognitive development in social domains, particularly from a post-training perspective, remains underexplored. Recognizing that the social world follows a distinct timeline and requires a richer blend of cognitive modes (from intuitive reactions (System 1) and surface-level thinking to deliberate thinking (System 2)) than mathematics, which primarily relies on System 2 cognition (careful, step-by-step reasoning), we introduce Temporal-aware Hierarchical Cognitive Reinforcement Learning (TimeHC-RL) for enhancing LLMs' social intelligence. In our experiments, we systematically explore improving LLMs' social intelligence and validate the effectiveness of the TimeHC-RL method, through five other post-training paradigms and two test-time intervention paradigms on eight datasets with diverse data patterns. Experimental results reveal the superiority of our proposed TimeHC-RL method compared to the widely adopted System 2 RL method. It gives the 7B backbone model wings, enabling it to rival the performance of advanced models like DeepSeek-R1 and OpenAI-O3. Additionally, the systematic exploration from post-training and test-time interventions perspectives to improve LLMs' social intelligence has uncovered several valuable insights.
Embodied-Reasoner: Synergizing Visual Search, Reasoning, and Action for Embodied Interactive Tasks
Mar 27, 2025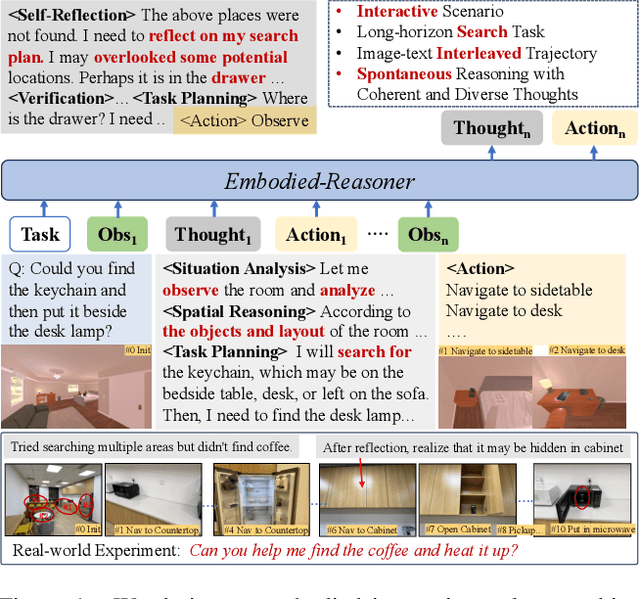

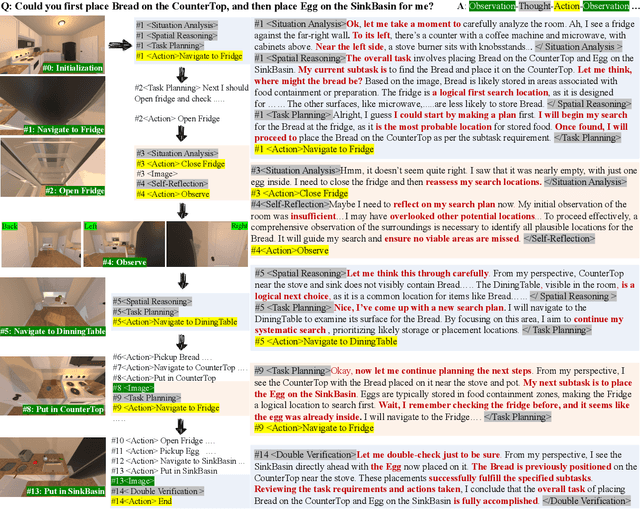
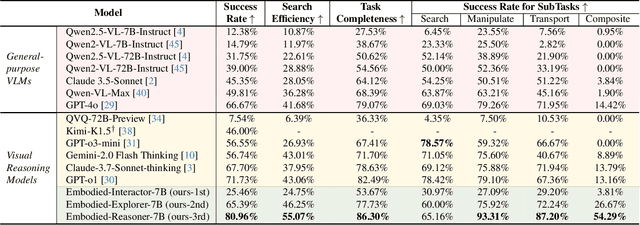
Recent advances in deep thinking models have demonstrated remarkable reasoning capabilities on mathematical and coding tasks. However, their effectiveness in embodied domains which require continuous interaction with environments through image action interleaved trajectories remains largely -unexplored. We present Embodied Reasoner, a model that extends o1 style reasoning to interactive embodied search tasks. Unlike mathematical reasoning that relies primarily on logical deduction, embodied scenarios demand spatial understanding, temporal reasoning, and ongoing self-reflection based on interaction history. To address these challenges, we synthesize 9.3k coherent Observation-Thought-Action trajectories containing 64k interactive images and 90k diverse thinking processes (analysis, spatial reasoning, reflection, planning, and verification). We develop a three-stage training pipeline that progressively enhances the model's capabilities through imitation learning, self-exploration via rejection sampling, and self-correction through reflection tuning. The evaluation shows that our model significantly outperforms those advanced visual reasoning models, e.g., it exceeds OpenAI o1, o3-mini, and Claude-3.7 by +9\%, 24\%, and +13\%. Analysis reveals our model exhibits fewer repeated searches and logical inconsistencies, with particular advantages in complex long-horizon tasks. Real-world environments also show our superiority while exhibiting fewer repeated searches and logical inconsistency cases.
AskToAct: Enhancing LLMs Tool Use via Self-Correcting Clarification
Mar 03, 2025Large language models (LLMs) have demonstrated remarkable capabilities in tool learning. In real-world scenarios, user queries are often ambiguous and incomplete, requiring effective clarification. However, existing interactive clarification approaches face two critical limitations: reliance on manually constructed datasets and lack of error correction mechanisms during multi-turn clarification. We present AskToAct, which addresses these challenges by exploiting the structural mapping between queries and their tool invocation solutions. Our key insight is that tool parameters naturally represent explicit user intents. By systematically removing key parameters from queries while retaining them as ground truth, we enable automated construction of high-quality training data. We further enhance model robustness by fine-tuning on error-correction augmented data using selective masking mechanism, enabling dynamic error detection during clarification interactions. Comprehensive experiments demonstrate that AskToAct significantly outperforms existing approaches, achieving above 79% accuracy in recovering critical unspecified intents and enhancing clarification efficiency by an average of 48.34% while maintaining high accuracy in tool invocation. Our framework exhibits robust performance across varying complexity levels and successfully generalizes to entirely unseen APIs without additional training, achieving performance comparable to GPT-4 with substantially fewer computational resources.
Adapting MIMO video restoration networks to low latency constraints
Aug 22, 2024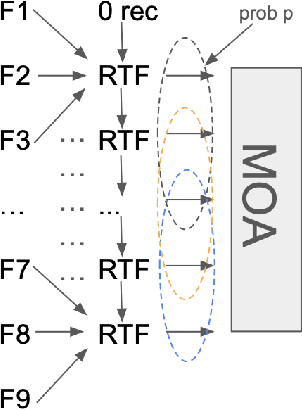


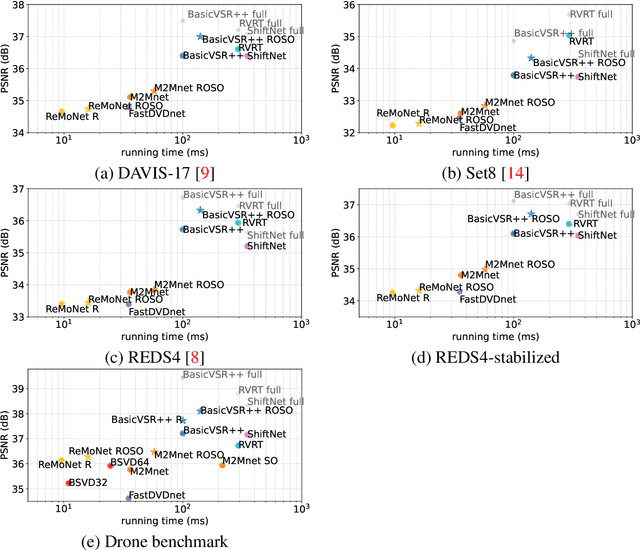
MIMO (multiple input, multiple output) approaches are a recent trend in neural network architectures for video restoration problems, where each network evaluation produces multiple output frames. The video is split into non-overlapping stacks of frames that are processed independently, resulting in a very appealing trade-off between output quality and computational cost. In this work we focus on the low-latency setting by limiting the number of available future frames. We find that MIMO architectures suffer from problems that have received little attention so far, namely (1) the performance drops significantly due to the reduced temporal receptive field, particularly for frames at the borders of the stack, (2) there are strong temporal discontinuities at stack transitions which induce a step-wise motion artifact. We propose two simple solutions to alleviate these problems: recurrence across MIMO stacks to boost the output quality by implicitly increasing the temporal receptive field, and overlapping of the output stacks to smooth the temporal discontinuity at stack transitions. These modifications can be applied to any MIMO architecture. We test them on three state-of-the-art video denoising networks with different computational cost. The proposed contributions result in a new state-of-the-art for low-latency networks, both in terms of reconstruction error and temporal consistency. As an additional contribution, we introduce a new benchmark consisting of drone footage that highlights temporal consistency issues that are not apparent in the standard benchmarks.
QuakeBERT: Accurate Classification of Social Media Texts for Rapid Earthquake Impact Assessment
May 06, 2024

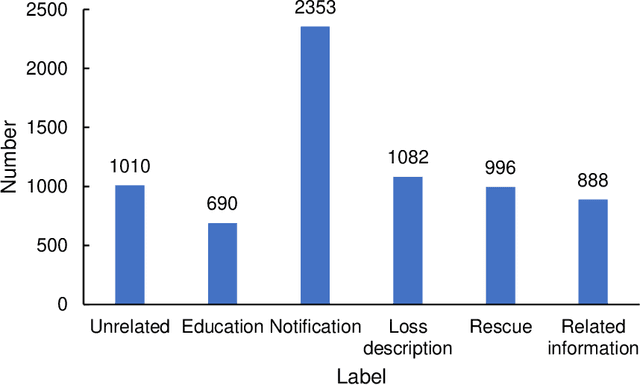
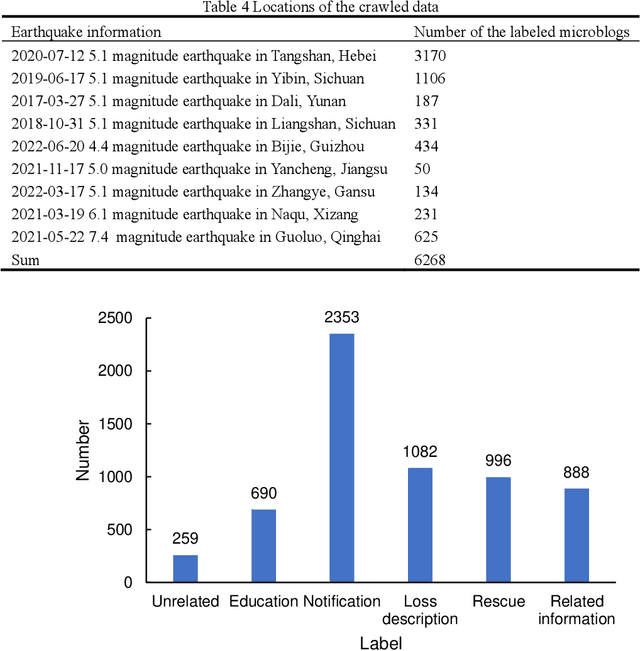
Social media aids disaster response but suffers from noise, hindering accurate impact assessment and decision making for resilient cities, which few studies considered. To address the problem, this study proposes the first domain-specific LLM model and an integrated method for rapid earthquake impact assessment. First, a few categories are introduced to classify and filter microblogs considering their relationship to the physical and social impacts of earthquakes, and a dataset comprising 7282 earthquake-related microblogs from twenty earthquakes in different locations is developed as well. Then, with a systematic analysis of various influential factors, QuakeBERT, a domain-specific large language model (LLM), is developed and fine-tuned for accurate classification and filtering of microblogs. Meanwhile, an integrated method integrating public opinion trend analysis, sentiment analysis, and keyword-based physical impact quantification is introduced to assess both the physical and social impacts of earthquakes based on social media texts. Experiments show that data diversity and data volume dominate the performance of QuakeBERT and increase the macro average F1 score by 27%, while the best classification model QuakeBERT outperforms the CNN- or RNN-based models by improving the macro average F1 score from 60.87% to 84.33%. Finally, the proposed approach is applied to assess two earthquakes with the same magnitude and focal depth. Results show that the proposed approach can effectively enhance the impact assessment process by accurate detection of noisy microblogs, which enables effective post-disaster emergency responses to create more resilient cities.
A Text Classification-Based Approach for Evaluating and Enhancing the Machine Interpretability of Building Codes
Sep 24, 2023

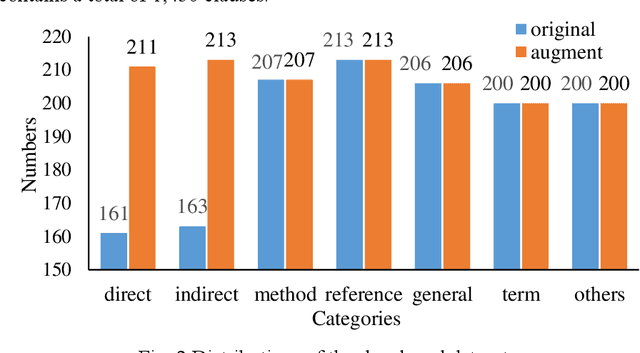
Interpreting regulatory documents or building codes into computer-processable formats is essential for the intelligent design and construction of buildings and infrastructures. Although automated rule interpretation (ARI) methods have been investigated for years, most of them highly depend on the early and manual filtering of interpretable clauses from a building code. While few of them considered machine interpretability, which represents the potential to be transformed into a computer-processable format, from both clause- and document-level. Therefore, this research aims to propose a novel approach to automatically evaluate and enhance the machine interpretability of single clause and building codes. First, a few categories are introduced to classify each clause in a building code considering the requirements for rule interpretation, and a dataset is developed for model training. Then, an efficient text classification model is developed based on a pretrained domain-specific language model and transfer learning techniques. Finally, a quantitative evaluation method is proposed to assess the overall interpretability of building codes. Experiments show that the proposed text classification algorithm outperforms the existing CNN- or RNN-based methods, improving the F1-score from 72.16% to 93.60%. It is also illustrated that the proposed classification method can enhance downstream ARI methods with an improvement of 4%. Furthermore, analyzing the results of more than 150 building codes in China showed that their average interpretability is 34.40%, which implies that it is still hard to fully transform the entire regulatory document into computer-processable formats. It is also argued that the interpretability of building codes should be further improved both from the human side and the machine side.
LLM-FuncMapper: Function Identification for Interpreting Complex Clauses in Building Codes via LLM
Aug 17, 2023As a vital stage of automated rule checking (ARC), rule interpretation of regulatory texts requires considerable effort. However, interpreting regulatory clauses with implicit properties or complex computational logic is still challenging due to the lack of domain knowledge and limited expressibility of conventional logic representations. Thus, LLM-FuncMapper, an approach to identifying predefined functions needed to interpret various regulatory clauses based on the large language model (LLM), is proposed. First, by systematically analysis of building codes, a series of atomic functions are defined to capture shared computational logics of implicit properties and complex constraints, creating a database of common blocks for interpreting regulatory clauses. Then, a prompt template with the chain of thought is developed and further enhanced with a classification-based tuning strategy, to enable common LLMs for effective function identification. Finally, the proposed approach is validated with statistical analysis, experiments, and proof of concept. Statistical analysis reveals a long-tail distribution and high expressibility of the developed function database, with which almost 100% of computer-processible clauses can be interpreted and represented as computer-executable codes. Experiments show that LLM-FuncMapper achieve promising results in identifying relevant predefined functions for rule interpretation. Further proof of concept in automated rule interpretation also demonstrates the possibility of LLM-FuncMapper in interpreting complex regulatory clauses. To the best of our knowledge, this study is the first attempt to introduce LLM for understanding and interpreting complex regulatory clauses, which may shed light on further adoption of LLM in the construction domain.
Automatic Design Method of Building Pipeline Layout Based on Deep Reinforcement Learning
May 18, 2023The layout design of pipelines is a critical task in the construction industry. Currently, pipeline layout is designed manually by engineers, which is time-consuming and laborious. Automating and streamlining this process can reduce the burden on engineers and save time. In this paper, we propose a method for generating three-dimensional layout of pipelines based on deep reinforcement learning (DRL). Firstly, we abstract the geometric features of space to establish a training environment and define reward functions based on three constraints: pipeline length, elbow, and installation distance. Next, we collect data through interactions between the agent and the environment and train the DRL model. Finally, we use the well-trained DRL model to automatically design a single pipeline. Our results demonstrate that DRL models can complete the pipeline layout task in space in a much shorter time than traditional algorithms while ensuring high-quality layout outcomes.
Text Mining-Based Patent Analysis for Automated Rule Checking in AEC
Dec 12, 2022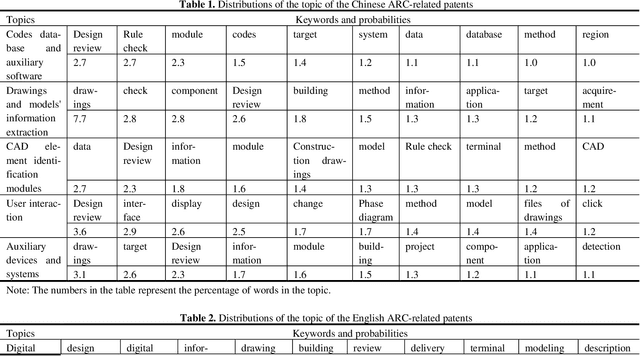
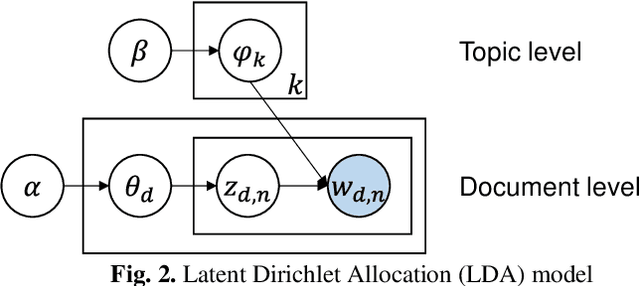
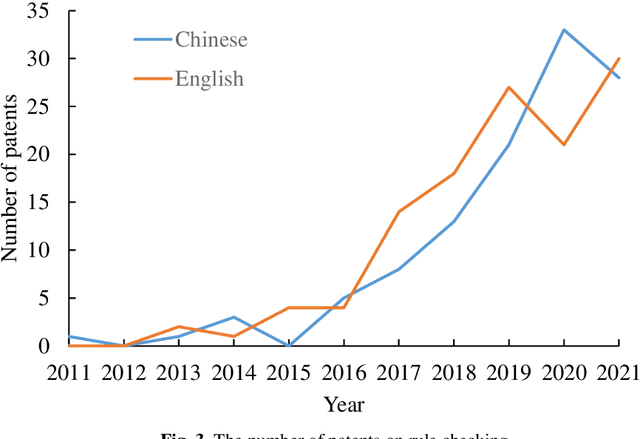

Automated rule checking (ARC), which is expected to promote the efficiency of the compliance checking process in the architecture, engineering, and construction (AEC) industry, is gaining increasing attention. Throwing light on the ARC application hotspots and forecasting its trends are useful to the related research and drive innovations. Therefore, this study takes the patents from the database of the Derwent Innovations Index database (DII) and China national knowledge infrastructure (CNKI) as data sources and then carried out a three-step analysis including (1) quantitative characteristics (i.e., annual distribution analysis) of patents, (2) identification of ARC topics using a latent Dirichlet allocation (LDA) and, (3) SNA-based co-occurrence analysis of ARC topics. The results show that the research hotspots and trends of Chinese and English patents are different. The contributions of this study have three aspects: (1) an approach to a comprehensive analysis of patents by integrating multiple text mining methods (i.e., SNA and LDA) is introduced ; (2) the application hotspots and development trends of ARC are reviewed based on patent analysis; and (3) a signpost for technological development and innovation of ARC is provided.