 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuakeBERT: Accurate Classification of Social Media Texts for Rapid Earthquake Impact Assessment
May 06, 2024

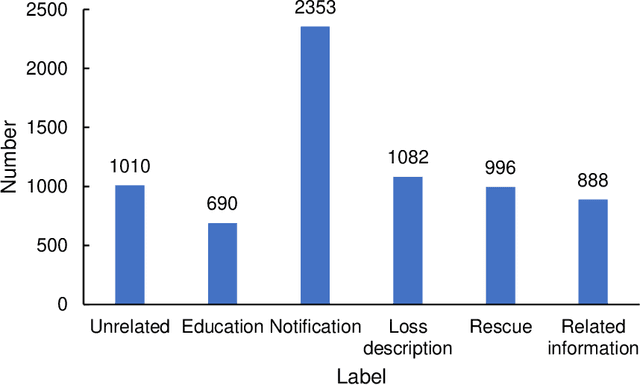
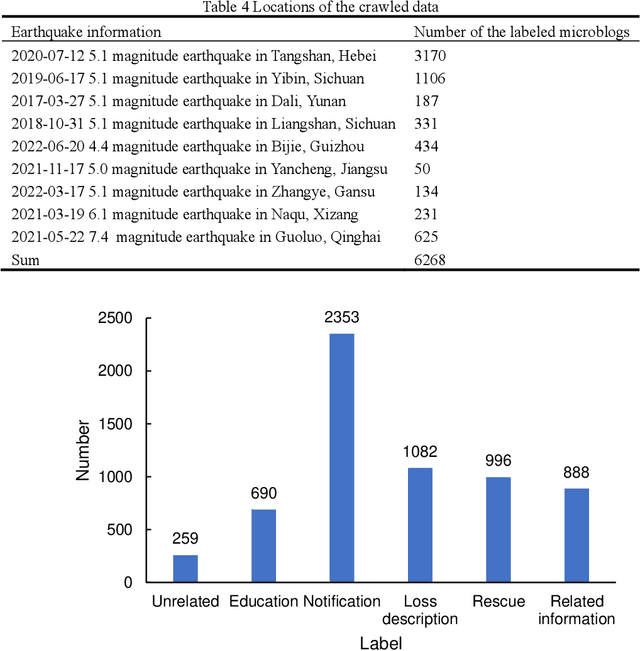
Social media aids disaster response but suffers from noise, hindering accurate impact assessment and decision making for resilient cities, which few studies considered. To address the problem, this study proposes the first domain-specific LLM model and an integrated method for rapid earthquake impact assessment. First, a few categories are introduced to classify and filter microblogs considering their relationship to the physical and social impacts of earthquakes, and a dataset comprising 7282 earthquake-related microblogs from twenty earthquakes in different locations is developed as well. Then, with a systematic analysis of various influential factors, QuakeBERT, a domain-specific large language model (LLM), is developed and fine-tuned for accurate classification and filtering of microblogs. Meanwhile, an integrated method integrating public opinion trend analysis, sentiment analysis, and keyword-based physical impact quantification is introduced to assess both the physical and social impacts of earthquakes based on social media texts. Experiments show that data diversity and data volume dominate the performance of QuakeBERT and increase the macro average F1 score by 27%, while the best classification model QuakeBERT outperforms the CNN- or RNN-based models by improving the macro average F1 score from 60.87% to 84.33%. Finally, the proposed approach is applied to assess two earthquakes with the same magnitude and focal depth. Results show that the proposed approach can effectively enhance the impact assessment process by accurate detection of noisy microblogs, which enables effective post-disaster emergency responses to create more resilient cities.
A Text Classification-Based Approach for Evaluating and Enhancing the Machine Interpretability of Building Codes
Sep 24, 2023

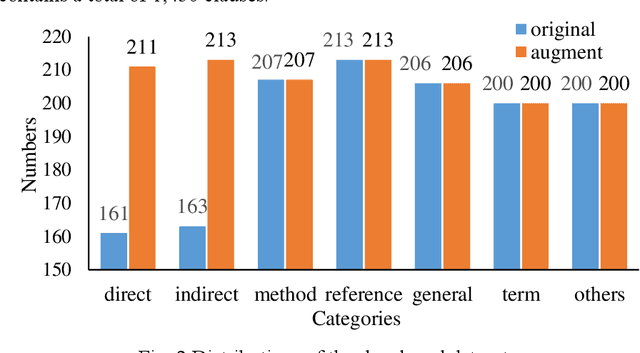
Interpreting regulatory documents or building codes into computer-processable formats is essential for the intelligent design and construction of buildings and infrastructures. Although automated rule interpretation (ARI) methods have been investigated for years, most of them highly depend on the early and manual filtering of interpretable clauses from a building code. While few of them considered machine interpretability, which represents the potential to be transformed into a computer-processable format, from both clause- and document-level. Therefore, this research aims to propose a novel approach to automatically evaluate and enhance the machine interpretability of single clause and building codes. First, a few categories are introduced to classify each clause in a building code considering the requirements for rule interpretation, and a dataset is developed for model training. Then, an efficient text classification model is developed based on a pretrained domain-specific language model and transfer learning techniques. Finally, a quantitative evaluation method is proposed to assess the overall interpretability of building codes. Experiments show that the proposed text classification algorithm outperforms the existing CNN- or RNN-based methods, improving the F1-score from 72.16% to 93.60%. It is also illustrated that the proposed classification method can enhance downstream ARI methods with an improvement of 4%. Furthermore, analyzing the results of more than 150 building codes in China showed that their average interpretability is 34.40%, which implies that it is still hard to fully transform the entire regulatory document into computer-processable formats. It is also argued that the interpretability of building codes should be further improved both from the human side and the machine side.
LLM-FuncMapper: Function Identification for Interpreting Complex Clauses in Building Codes via LLM
Aug 17, 2023As a vital stage of automated rule checking (ARC), rule interpretation of regulatory texts requires considerable effort. However, interpreting regulatory clauses with implicit properties or complex computational logic is still challenging due to the lack of domain knowledge and limited expressibility of conventional logic representations. Thus, LLM-FuncMapper, an approach to identifying predefined functions needed to interpret various regulatory clauses based on the large language model (LLM), is proposed. First, by systematically analysis of building codes, a series of atomic functions are defined to capture shared computational logics of implicit properties and complex constraints, creating a database of common blocks for interpreting regulatory clauses. Then, a prompt template with the chain of thought is developed and further enhanced with a classification-based tuning strategy, to enable common LLMs for effective function identification. Finally, the proposed approach is validated with statistical analysis, experiments, and proof of concept. Statistical analysis reveals a long-tail distribution and high expressibility of the developed function database, with which almost 100% of computer-processible clauses can be interpreted and represented as computer-executable codes. Experiments show that LLM-FuncMapper achieve promising results in identifying relevant predefined functions for rule interpretation. Further proof of concept in automated rule interpretation also demonstrates the possibility of LLM-FuncMapper in interpreting complex regulatory clauses. To the best of our knowledge, this study is the first attempt to introduce LLM for understanding and interpreting complex regulatory clauses, which may shed light on further adoption of LLM in the construction domain.
Pretrained Domain-Specific Language Model for General Information Retrieval Tasks in the AEC Domain
Mar 09, 2022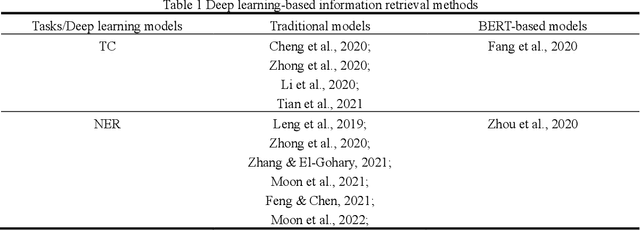
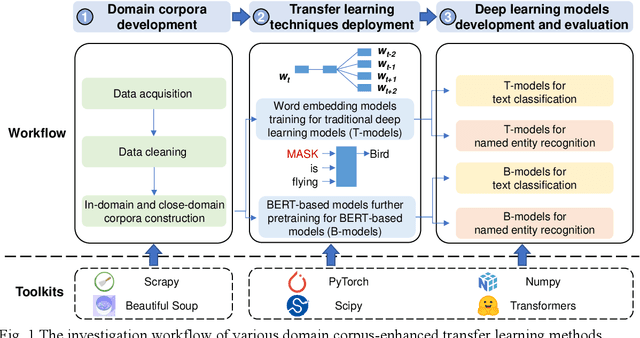
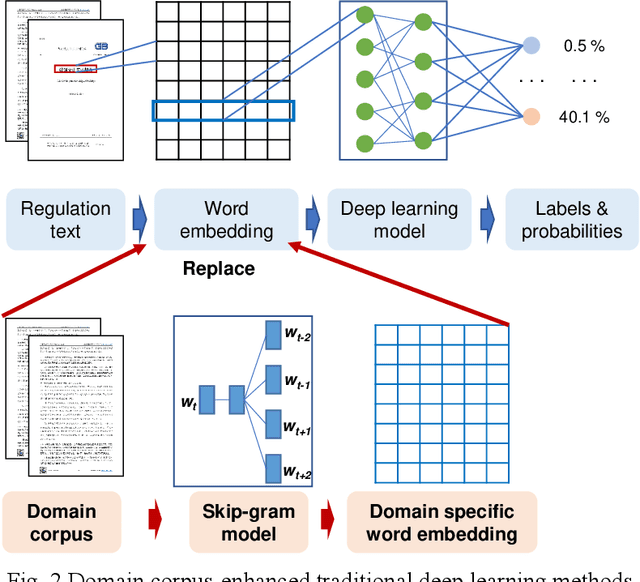

As an essential task for the architecture, engineering, and construction (AEC) industry, information retrieval (IR) from unstructured textual data based on natural language processing (NLP) is gaining increasing attention. Although various deep learning (DL) models for IR tasks have been investigated in the AEC domain, it is still unclear how domain corpora and domain-specific pretrained DL models can improve performance in various IR tasks. To this end, this work systematically explores the impacts of domain corpora and various transfer learning techniques on the performance of DL models for IR tasks and proposes a pretrained domain-specific language model for the AEC domain. First, both in-domain and close-domain corpora are developed. Then, two types of pretrained models, including traditional wording embedding models and BERT-based models, are pretrained based on various domain corpora and transfer learning strategies. Finally, several widely used DL models for IR tasks are further trained and tested based on various configurations and pretrained models. The result shows that domain corpora have opposite effects on traditional word embedding models for text classification and named entity recognition tasks but can further improve the performance of BERT-based models in all tasks. Meanwhile, BERT-based models dramatically outperform traditional methods in all IR tasks, with maximum improvements of 5.4% and 10.1% in the F1 score, respectively. This research contributes to the body of knowledge in two ways: 1) demonstrating the advantages of domain corpora and pretrained DL models and 2) opening the first domain-specific dataset and pretrained language model for the AEC domain, to the best of our knowledge. Thus, this work sheds light on the adoption and application of pretrained models in the AEC domain.