 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretrained Domain-Specific Language Model for General Information Retrieval Tasks in the AEC Domain
Paper and Code
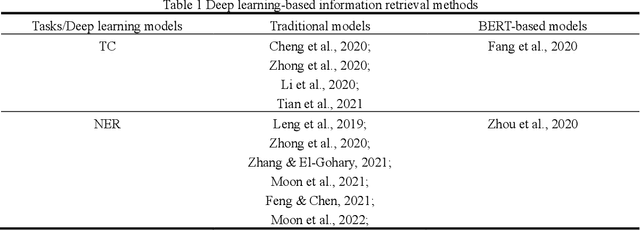
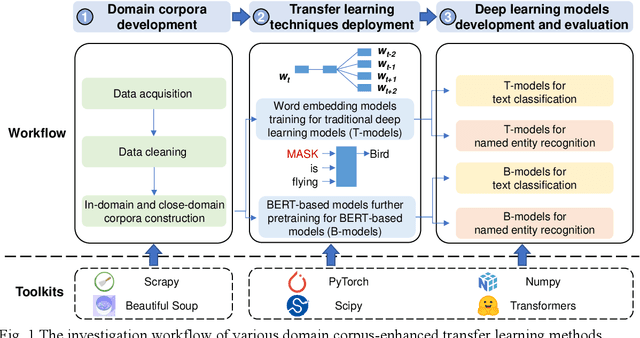
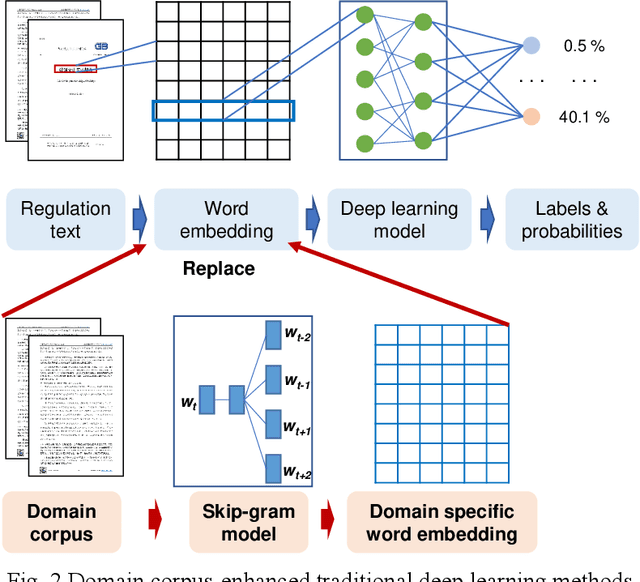

As an essential task for the architecture, engineering, and construction (AEC) industry, information retrieval (IR) from unstructured textual data based on natural language processing (NLP) is gaining increasing attention. Although various deep learning (DL) models for IR tasks have been investigated in the AEC domain, it is still unclear how domain corpora and domain-specific pretrained DL models can improve performance in various IR tasks. To this end, this work systematically explores the impacts of domain corpora and various transfer learning techniques on the performance of DL models for IR tasks and proposes a pretrained domain-specific language model for the AEC domain. First, both in-domain and close-domain corpora are developed. Then, two types of pretrained models, including traditional wording embedding models and BERT-based models, are pretrained based on various domain corpora and transfer learning strategies. Finally, several widely used DL models for IR tasks are further trained and tested based on various configurations and pretrained models. The result shows that domain corpora have opposite effects on traditional word embedding models for text classification and named entity recognition tasks but can further improve the performance of BERT-based models in all tasks. Meanwhile, BERT-based models dramatically outperform traditional methods in all IR tasks, with maximum improvements of 5.4% and 10.1% in the F1 score, respectively. This research contributes to the body of knowledge in two ways: 1) demonstrating the advantages of domain corpora and pretrained DL models and 2) opening the first domain-specific dataset and pretrained language model for the AEC domain, to the best of our knowledge. Thus, this work sheds light on the adoption and application of pretrained models in the AEC domain.