 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-BIM: developing large language model for BIM-based design with domain-specific benchmark and dataset
Feb 24, 2026As the construction industry advances toward digital transformation, BIM (Building Information Modeling)-based design has become a key driver supporting intelligent construction. Despite Large Language Models (LLMs) have shown potential in promoting BIM-based design, the lack of specific datasets and LLM evaluation benchmarks has significantly hindered the performance of LLMs. Therefore, this paper addresses this gap by proposing: 1) an evaluation benchmark for BIM-based design together with corresponding quantitative indicators to evaluate the performance of LLMs, 2) a method for generating textual data from BIM and constructing corresponding BIM-derived datasets for LLM evaluation and fine-tuning, and 3) a fine-tuning strategy to adapt LLMs for BIM-based design. Results demonstrate that the proposed domain-specific benchmark effectively and comprehensively assesses LLM capabilities, highlighting that general LLMs are still incompetent for domain-specific tasks. Meanwhile, with the proposed benchmark and datasets, Qwen-BIM is developed and achieves a 21.0% average increase in G-Eval score compared to the base LLM model. Notably, with only 14B parameters, performance of Qwen-BIM is comparable to that of general LLMs with 671B parameters for BIM-based design tasks. Overall, this study develops the first domain-specific LLM for BIM-based design by introducing a comprehensive benchmark and high-quality dataset, which provide a solid foundation for developing BIM-related LLMs in various fields.
SatAOI: Delimitating Area of Interest for Swing-Arm Troweling Robot for Construction
May 08, 2025In concrete troweling for building construction, robots can significantly reduce workload and improve automation level. However, as a primary task of coverage path planning (CPP) for troweling, delimitating area of interest (AOI) in complex scenes is still challenging, especially for swing-arm robots with more complex working modes. Thus, this research proposes an algorithm to delimitate AOI for swing-arm troweling robot (SatAOI algorithm). By analyzing characteristics of the robot and obstacle maps, mathematical models and collision principles are established. On this basis, SatAOI algorithm achieves AOI delimitation by global search and collision detection. Experiments on different obstacle maps indicate that AOI can be effectively delimitated in scenes under different complexity, and the algorithm can fully consider the connectivity of obstacle maps. This research serves as a foundation for CPP algorithm and full process simulation of swing-arm troweling robots.
Impact of color and mixing proportion of synthetic point clouds on semantic segmentation
Dec 26, 2024



Semantic segmentation of point clouds is essential for understanding the built environment, and a large amount of high-quality data is required for training deep learning models. Despite synthetic point clouds (SPC) having the potential to compensate for the shortage of real data, how to exploit the benefits of SPC is still open. Therefore, this study systematically investigates how color and mixing proportion of SPC impact semantic segmentation for the first time. First, a new method to mimic the scanning process and generate SPC based on BIM is proposed, to create a synthetic dataset with consistent colors of BIM (UniSPC) and a synthetic dataset with real colors (RealSPC) respectively. Subsequently, by integrating with the S3DIS dataset, further experiments on PointNet, PointNet++, and DGCNN are conducted. Meanwhile, benchmark experiments and new evaluation metrics are introduced to better evaluate the performance of different models. Experiments show that synthetic color significantly impacts model performance, the performance for common components of the models trained with pure RealSPC is comparable to models with real data, and RealSPC contributes average improvements of 14.1% on overall accuracy and 7.3% on mIoU than UniSPC. Furthermore, the proportion of SPC also has a significant impact on the performance. In mixing training experiments, adding more than 70% SPC achieves an average of 3.9% on overall accuracy and 3.4% on mIoU better than benchmark on three models. It is also revealed that for large flat elements such as floors, ceilings, and walls, the SPC can even replace real point clouds without compromising model performance.
What makes a good BIM design: quantitative linking between design behavior and quality
Nov 14, 2024



In the Architecture Engineering & Construction (AEC) industry, how design behaviors impact design quality remains unclear. This study proposes a novel approach, which, for the first time, identifies and quantitatively describes the relationship between design behaviors and quality of design based on Building Information Modeling (BIM). Real-time collection and log mining are integrated to collect raw data of design behaviors. Feature engineering and various machine learning models are then utilized for quantitative modeling and interpretation. Results confirm an existing quantifiable relationship which can be learned by various models. The best-performing model using Extremely Random Trees achieved an R2 value of 0.88 on the test set. Behavioral features related to designer's skill level and changes of design intentions are identified to have significant impacts on design quality. These findings deepen our understanding of the design process and help forming BIM designs with better quality.
QuakeBERT: Accurate Classification of Social Media Texts for Rapid Earthquake Impact Assessment
May 06, 2024

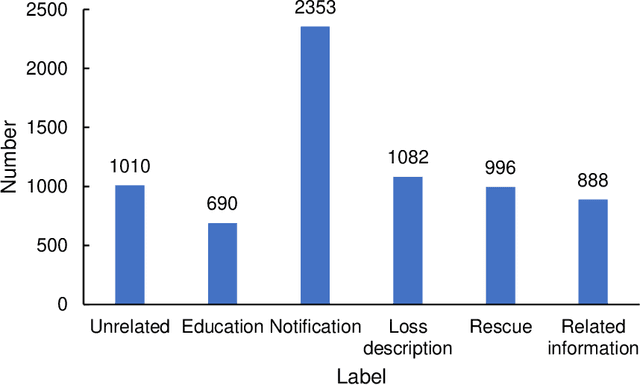
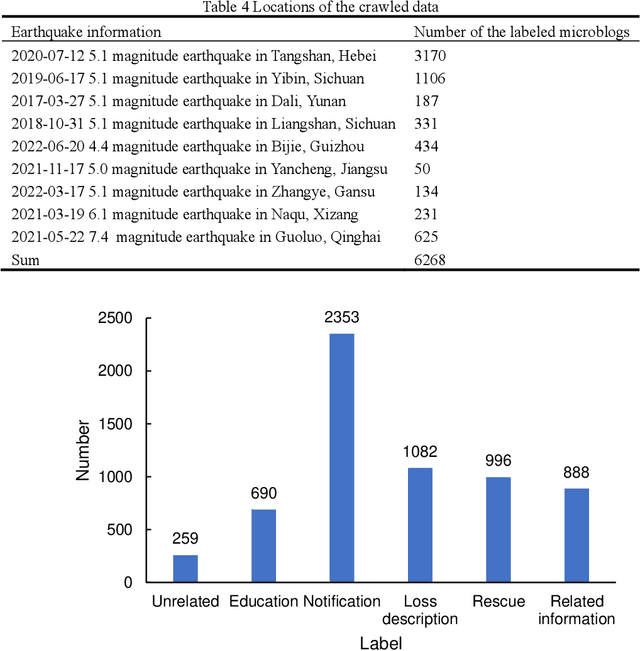
Social media aids disaster response but suffers from noise, hindering accurate impact assessment and decision making for resilient cities, which few studies considered. To address the problem, this study proposes the first domain-specific LLM model and an integrated method for rapid earthquake impact assessment. First, a few categories are introduced to classify and filter microblogs considering their relationship to the physical and social impacts of earthquakes, and a dataset comprising 7282 earthquake-related microblogs from twenty earthquakes in different locations is developed as well. Then, with a systematic analysis of various influential factors, QuakeBERT, a domain-specific large language model (LLM), is developed and fine-tuned for accurate classification and filtering of microblogs. Meanwhile, an integrated method integrating public opinion trend analysis, sentiment analysis, and keyword-based physical impact quantification is introduced to assess both the physical and social impacts of earthquakes based on social media texts. Experiments show that data diversity and data volume dominate the performance of QuakeBERT and increase the macro average F1 score by 27%, while the best classification model QuakeBERT outperforms the CNN- or RNN-based models by improving the macro average F1 score from 60.87% to 84.33%. Finally, the proposed approach is applied to assess two earthquakes with the same magnitude and focal depth. Results show that the proposed approach can effectively enhance the impact assessment process by accurate detection of noisy microblogs, which enables effective post-disaster emergency responses to create more resilient cities.
A Text Classification-Based Approach for Evaluating and Enhancing the Machine Interpretability of Building Codes
Sep 24, 2023

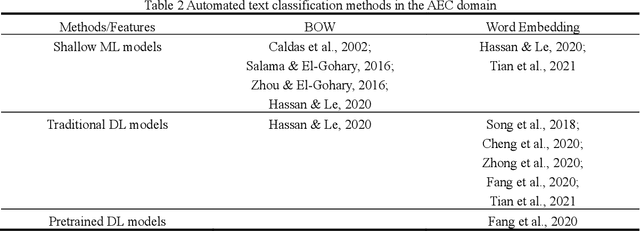
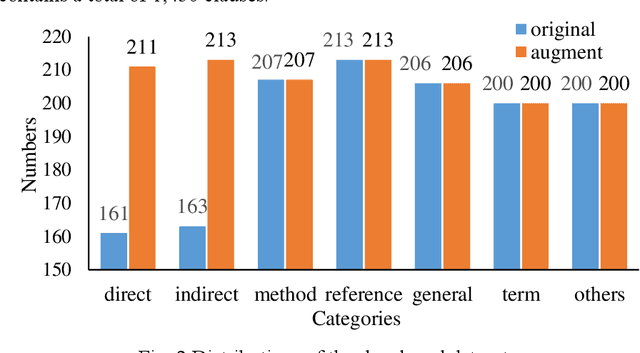
Interpreting regulatory documents or building codes into computer-processable formats is essential for the intelligent design and construction of buildings and infrastructures. Although automated rule interpretation (ARI) methods have been investigated for years, most of them highly depend on the early and manual filtering of interpretable clauses from a building code. While few of them considered machine interpretability, which represents the potential to be transformed into a computer-processable format, from both clause- and document-level. Therefore, this research aims to propose a novel approach to automatically evaluate and enhance the machine interpretability of single clause and building codes. First, a few categories are introduced to classify each clause in a building code considering the requirements for rule interpretation, and a dataset is developed for model training. Then, an efficient text classification model is developed based on a pretrained domain-specific language model and transfer learning techniques. Finally, a quantitative evaluation method is proposed to assess the overall interpretability of building codes. Experiments show that the proposed text classification algorithm outperforms the existing CNN- or RNN-based methods, improving the F1-score from 72.16% to 93.60%. It is also illustrated that the proposed classification method can enhance downstream ARI methods with an improvement of 4%. Furthermore, analyzing the results of more than 150 building codes in China showed that their average interpretability is 34.40%, which implies that it is still hard to fully transform the entire regulatory document into computer-processable formats. It is also argued that the interpretability of building codes should be further improved both from the human side and the machine side.
LLM-FuncMapper: Function Identification for Interpreting Complex Clauses in Building Codes via LLM
Aug 17, 2023As a vital stage of automated rule checking (ARC), rule interpretation of regulatory texts requires considerable effort. However, interpreting regulatory clauses with implicit properties or complex computational logic is still challenging due to the lack of domain knowledge and limited expressibility of conventional logic representations. Thus, LLM-FuncMapper, an approach to identifying predefined functions needed to interpret various regulatory clauses based on the large language model (LLM), is proposed. First, by systematically analysis of building codes, a series of atomic functions are defined to capture shared computational logics of implicit properties and complex constraints, creating a database of common blocks for interpreting regulatory clauses. Then, a prompt template with the chain of thought is developed and further enhanced with a classification-based tuning strategy, to enable common LLMs for effective function identification. Finally, the proposed approach is validated with statistical analysis, experiments, and proof of concept. Statistical analysis reveals a long-tail distribution and high expressibility of the developed function database, with which almost 100% of computer-processible clauses can be interpreted and represented as computer-executable codes. Experiments show that LLM-FuncMapper achieve promising results in identifying relevant predefined functions for rule interpretation. Further proof of concept in automated rule interpretation also demonstrates the possibility of LLM-FuncMapper in interpreting complex regulatory clauses. To the best of our knowledge, this study is the first attempt to introduce LLM for understanding and interpreting complex regulatory clauses, which may shed light on further adoption of LLM in the construction domain.
A Multilayer Perceptron-based Fast Sunlight Assessment for the Conceptual Design of Residential Neighborhoods under Chinese Policy
Aug 15, 2023In Chinese building codes, it is required that residential buildings receive a minimum number of hours of natural, direct sunlight on a specified winter day, which represents the worst sunlight condition in a year. This requirement is a prerequisite for obtaining a building permit during the conceptual design of a residential project. Thus, officially sanctioned software is usually used to assess the sunlight performance of buildings. These software programs predict sunlight hours based on repeated shading calculations, which is time-consuming. This paper proposed a multilayer perceptron-based method, a one-stage prediction approach, which outputs a shading time interval caused by the inputted cuboid-form building. The sunlight hours of a site can be obtained by calculating the union of the sunlight time intervals (complement of shading time interval) of all the buildings. Three numerical experiments, i.e., horizontal level and slope analysis, and simulation-based optimization are carried out; the results show that the method reduces the computation time to 1/84~1/50 with 96.5%~98% accuracies. A residential neighborhood layout planning plug-in for Rhino 7/Grasshopper is also developed based on the proposed model. This paper indicates that deep learning techniques can be adopted to accelerate sunlight hour simulations at the conceptual design phase.
Adaptive Control of Resource Flow to Optimize Construction Work and Cash Flow via Online Deep Reinforcement Learning
Jul 20, 2023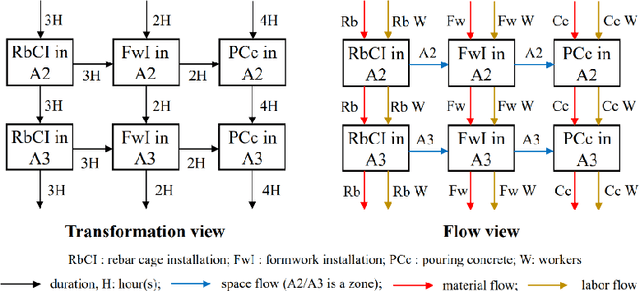
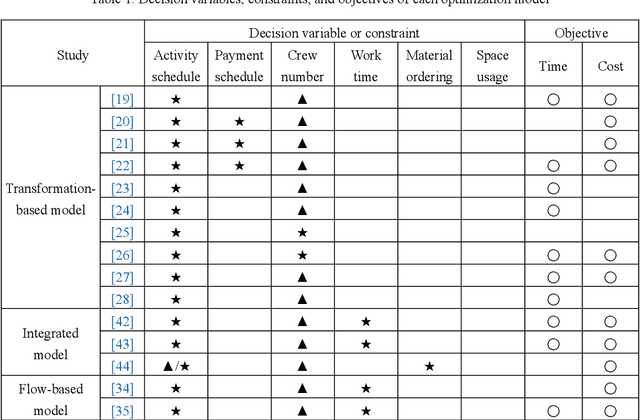
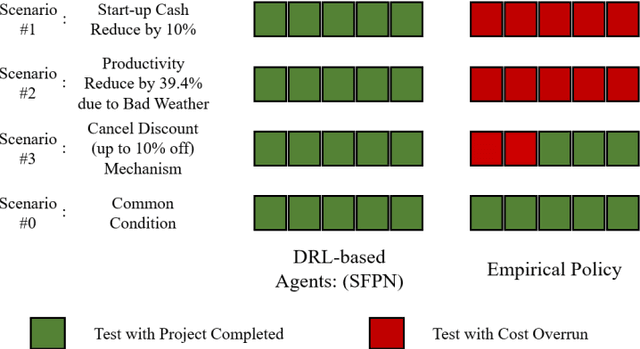

Due to complexity and dynamics of construction work, resource, and cash flows, poor management of them usually leads to time and cost overruns, bankruptcy, even project failure. Existing approaches in construction failed to achieve optimal control of resource flow in a dynamic environment with uncertainty. Therefore, this paper introducess a model and method to adaptive control the resource flows to optimize the work and cash flows of construction projects. First, a mathematical model based on a partially observable Markov decision process is established to formulate the complex interactions of construction work, resource, and cash flows as well as uncertainty and variability of diverse influence factors. Meanwhile, to efficiently find the optimal solutions, a deep reinforcement learning (DRL) based method is introduced to realize the continuous adaptive optimal control of labor and material flows, thereby optimizing the work and cash flows. To assist the training process of DRL, a simulator based on discrete event simulation is also developed to mimic the dynamic features and external environments of a project. Experiments in simulated scenarios illustrate that our method outperforms the vanilla empirical method and genetic algorithm, possesses remarkable capability in diverse projects and external environments, and a hybrid agent of DRL and empirical method leads to the best result. This paper contributes to adaptive control and optimization of coupled work, resource, and cash flows, and may serve as a step stone for adopting DRL technology in construction project management.
Automatic Design Method of Building Pipeline Layout Based on Deep Reinforcement Learning
May 18, 2023The layout design of pipelines is a critical task in the construction industry. Currently, pipeline layout is designed manually by engineers, which is time-consuming and laborious. Automating and streamlining this process can reduce the burden on engineers and save time. In this paper, we propose a method for generating three-dimensional layout of pipelines based on deep reinforcement learning (DRL). Firstly, we abstract the geometric features of space to establish a training environment and define reward functions based on three constraints: pipeline length, elbow, and installation distance. Next, we collect data through interactions between the agent and the environment and train the DRL model. Finally, we use the well-trained DRL model to automatically design a single pipeline. Our results demonstrate that DRL models can complete the pipeline layout task in space in a much shorter time than traditional algorithms while ensuring high-quality layout outcomes.