 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRETHINED: A New Benchmark and Baseline for Real-Time High-Resolution Image Inpainting On Edge Devices
Mar 18, 2025
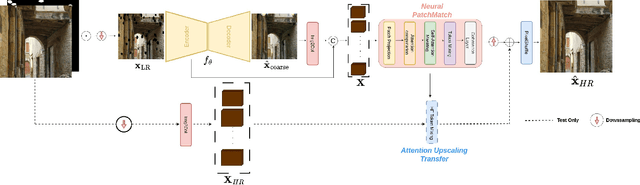


Existing image inpainting methods have shown impressive completion results for low-resolution images. However, most of these algorithms fail at high resolutions and require powerful hardware, limiting their deployment on edge devices. Motivated by this, we propose the first baseline for REal-Time High-resolution image INpainting on Edge Devices (RETHINED) that is able to inpaint at ultra-high-resolution and can run in real-time ($\leq$ 30ms) in a wide variety of mobile devices. A simple, yet effective novel method formed by a lightweight Convolutional Neural Network (CNN) to recover structure, followed by a resolution-agnostic patch replacement mechanism to provide detailed texture. Specially our pipeline leverages the structural capacity of CNN and the high-level detail of patch-based methods, which is a key component for high-resolution image inpainting. To demonstrate the real application of our method, we conduct an extensive analysis on various mobile-friendly devices and demonstrate similar inpainting performance while being $\mathrm{100 \times faster}$ than existing state-of-the-art methods. Furthemore, we realease DF8K-Inpainting, the first free-form mask UHD inpainting dataset.
SGSST: Scaling Gaussian Splatting StyleTransfer
Dec 04, 2024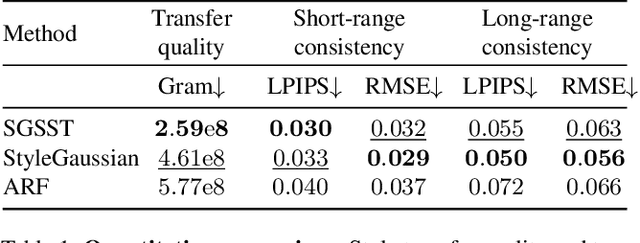
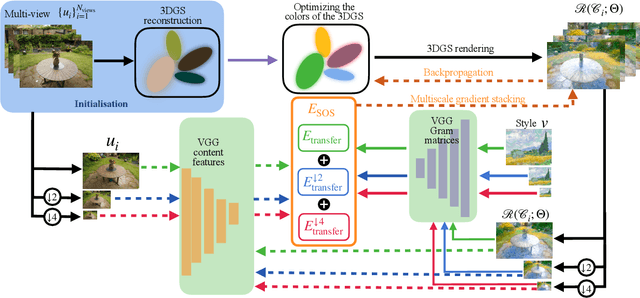


Applying style transfer to a full 3D environment is a challenging task that has seen many developments since the advent of neural rendering. 3D Gaussian splatting (3DGS) has recently pushed further many limits of neural rendering in terms of training speed and reconstruction quality. This work introduces SGSST: Scaling Gaussian Splatting Style Transfer, an optimization-based method to apply style transfer to pretrained 3DGS scenes. We demonstrate that a new multiscale loss based on global neural statistics, that we name SOS for Simultaneously Optimized Scales, enables style transfer to ultra-high resolution 3D scenes. Not only SGSST pioneers 3D scene style transfer at such high image resolutions, it also produces superior visual quality as assessed by thorough qualitative, quantitative and perceptual comparisons.
Adapting MIMO video restoration networks to low latency constraints
Aug 22, 2024


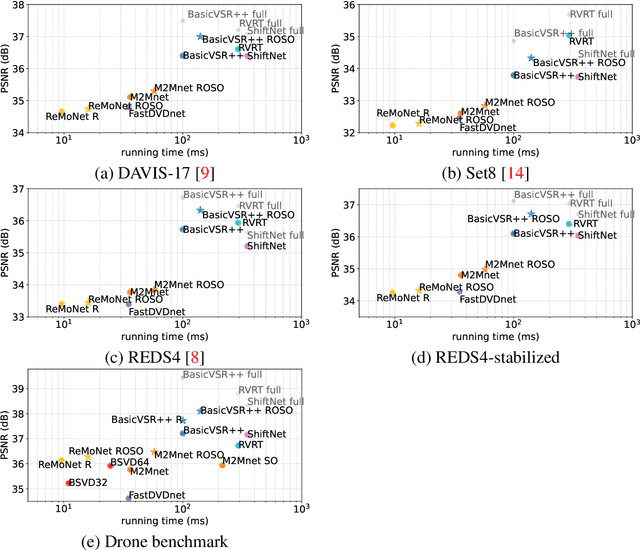
MIMO (multiple input, multiple output) approaches are a recent trend in neural network architectures for video restoration problems, where each network evaluation produces multiple output frames. The video is split into non-overlapping stacks of frames that are processed independently, resulting in a very appealing trade-off between output quality and computational cost. In this work we focus on the low-latency setting by limiting the number of available future frames. We find that MIMO architectures suffer from problems that have received little attention so far, namely (1) the performance drops significantly due to the reduced temporal receptive field, particularly for frames at the borders of the stack, (2) there are strong temporal discontinuities at stack transitions which induce a step-wise motion artifact. We propose two simple solutions to alleviate these problems: recurrence across MIMO stacks to boost the output quality by implicitly increasing the temporal receptive field, and overlapping of the output stacks to smooth the temporal discontinuity at stack transitions. These modifications can be applied to any MIMO architecture. We test them on three state-of-the-art video denoising networks with different computational cost. The proposed contributions result in a new state-of-the-art for low-latency networks, both in terms of reconstruction error and temporal consistency. As an additional contribution, we introduce a new benchmark consisting of drone footage that highlights temporal consistency issues that are not apparent in the standard benchmarks.
On The Role of Alias and Band-Shift for Sentinel-2 Super-Resolution
Feb 22, 2023
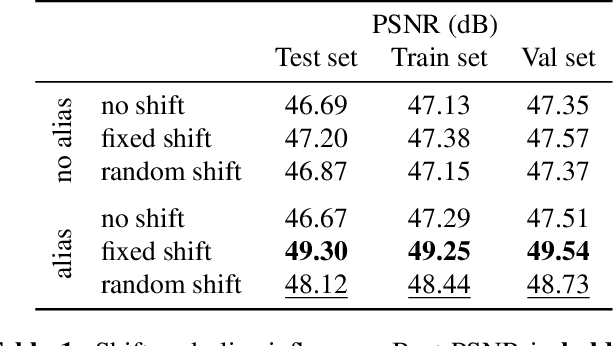


In this work, we study the problem of single-image super-resolution (SISR) of Sentinel-2 imagery. We show that thanks to its unique sensor specification, namely the inter-band shift and alias, that deep-learning methods are able to recover fine details. By training a model using a simple $L_1$ loss, results are free of hallucinated details. For this study, we build a dataset of pairs of images Sentinel-2/PlanetScope to train and evaluate our super-resolution (SR) model.
Scaling Painting Style Transfer
Dec 27, 2022

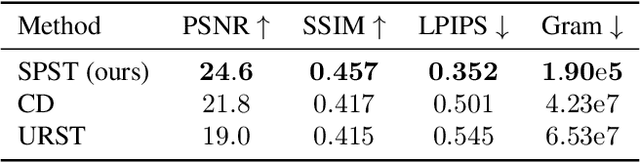
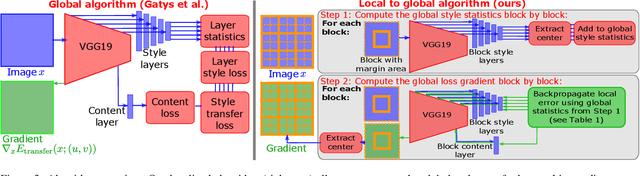
Neural style transfer is a deep learning technique that produces an unprecedentedly rich style transfer from a style image to a content image and is particularly impressive when it comes to transferring style from a painting to an image. It was originally achieved by solving an optimization problem to match the global style statistics of the style image while preserving the local geometric features of the content image. The two main drawbacks of this original approach is that it is computationally expensive and that the resolution of the output images is limited by high GPU memory requirements. Many solutions have been proposed to both accelerate neural style transfer and increase its resolution, but they all compromise the quality of the produced images. Indeed, transferring the style of a painting is a complex task involving features at different scales, from the color palette and compositional style to the fine brushstrokes and texture of the canvas. This paper provides a solution to solve the original global optimization for ultra-high resolution images, enabling multiscale style transfer at unprecedented image sizes. This is achieved by spatially localizing the computation of each forward and backward passes through the VGG network. Extensive qualitative and quantitative comparisons show that our method produces a style transfer of unmatched quality for such high resolution painting styles.
Photorealistic Facial Wrinkles Removal
Nov 03, 2022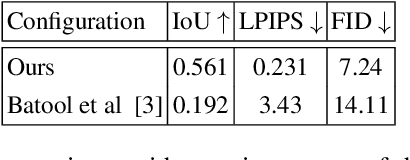

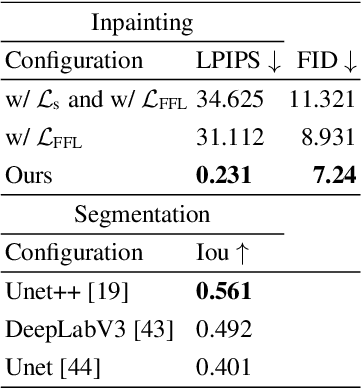
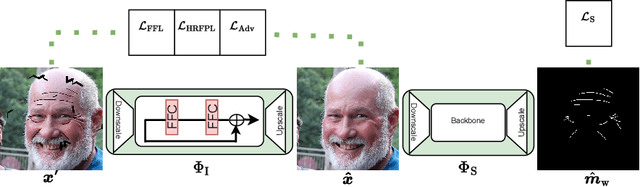
Editing and retouching facial attributes is a complex task that usually requires human artists to obtain photo-realistic results. Its applications are numerous and can be found in several contexts such as cosmetics or digital media retouching, to name a few. Recently, advancements in conditional generative modeling have shown astonishing results at modifying facial attributes in a realistic manner. However, current methods are still prone to artifacts, and focus on modifying global attributes like age and gender, or local mid-sized attributes like glasses or moustaches. In this work, we revisit a two-stage approach for retouching facial wrinkles and obtain results with unprecedented realism. First, a state of the art wrinkle segmentation network is used to detect the wrinkles within the facial region. Then, an inpainting module is used to remove the detected wrinkles, filling them in with a texture that is statistically consistent with the surrounding skin. To achieve this, we introduce a novel loss term that reuses the wrinkle segmentation network to penalize those regions that still contain wrinkles after the inpainting. We evaluate our method qualitatively and quantitatively, showing state of the art results for the task of wrinkle removal. Moreover, we introduce the first high-resolution dataset, named FFHQ-Wrinkles, to evaluate wrinkle detection methods.
Analysis of Different Losses for Deep Learning Image Colorization
Apr 06, 2022
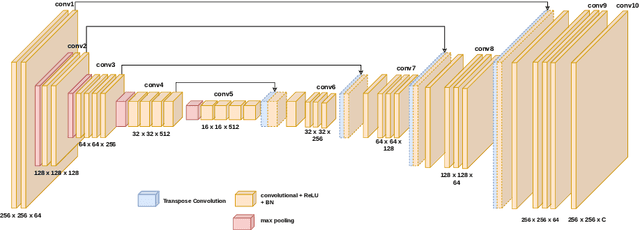
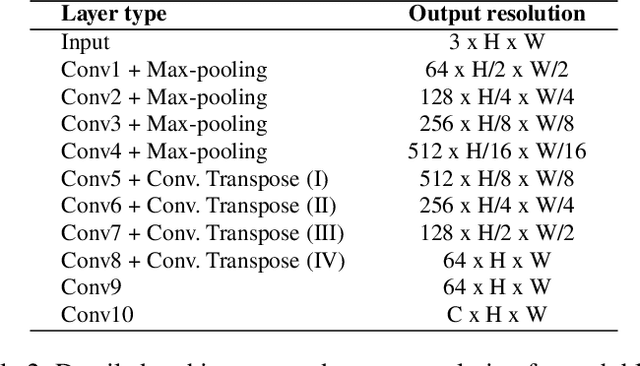

Image colorization aims to add color information to a grayscale image in a realistic way. Recent methods mostly rely on deep learning strategies. While learning to automatically colorize an image, one can define well-suited objective functions related to the desired color output. Some of them are based on a specific type of error between the predicted image and ground truth one, while other losses rely on the comparison of perceptual properties. But, is the choice of the objective function that crucial, i.e., does it play an important role in the results? In this chapter, we aim to answer this question by analyzing the impact of the loss function on the estimated colorization results. To that goal, we review the different losses and evaluation metrics that are used in the literature. We then train a baseline network with several of the reviewed objective functions: classic L1 and L2 losses, as well as more complex combinations such as Wasserstein GAN and VGG-based LPIPS loss. Quantitative results show that the models trained with VGG-based LPIPS provide overall slightly better results for most evaluation metrics. Qualitative results exhibit more vivid colors when with Wasserstein GAN plus the L2 loss or again with the VGG-based LPIPS. Finally, the convenience of quantitative user studies is also discussed to overcome the difficulty of properly assessing on colorized images, notably for the case of old archive photographs where no ground truth is available.
Influence of Color Spaces for Deep Learning Image Colorization
Apr 06, 2022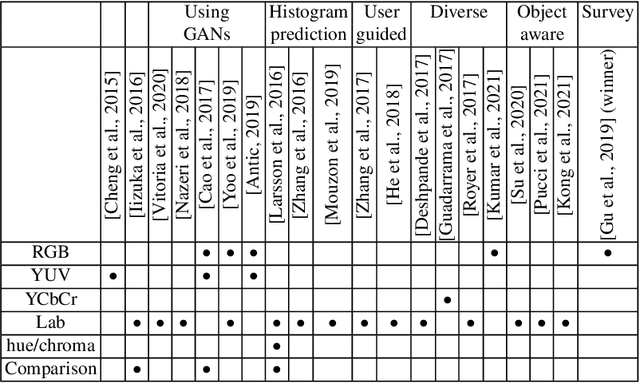

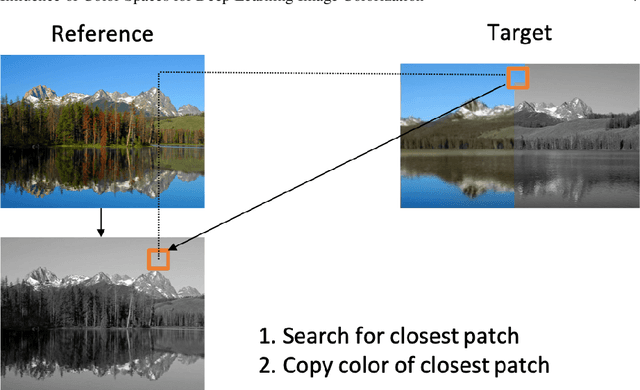
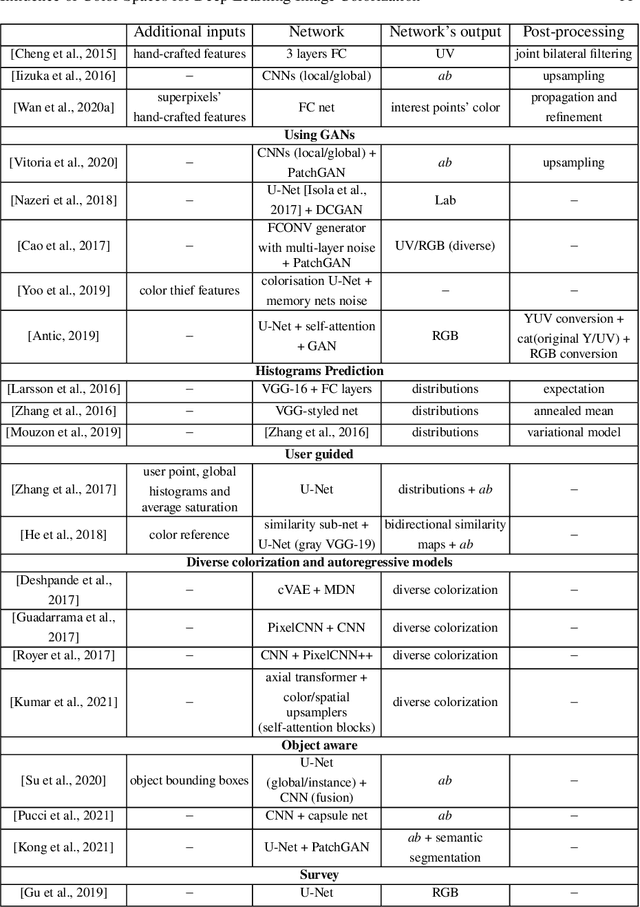
Colorization is a process that converts a grayscale image into a color one that looks as natural as possible. Over the years this task has received a lot of attention. Existing colorization methods rely on different color spaces: RGB, YUV, Lab, etc. In this chapter, we aim to study their influence on the results obtained by training a deep neural network, to answer the question: "Is it crucial to correctly choose the right color space in deep-learning based colorization?". First, we briefly summarize the literature and, in particular, deep learning-based methods. We then compare the results obtained with the same deep neural network architecture with RGB, YUV and Lab color spaces. Qualitative and quantitative analysis do not conclude similarly on which color space is better. We then show the importance of carefully designing the architecture and evaluation protocols depending on the types of images that are being processed and their specificities: strong/small contours, few/many objects, recent/archive images.
ChromaGAN: An Adversarial Approach for Picture Colorization
Jul 23, 2019
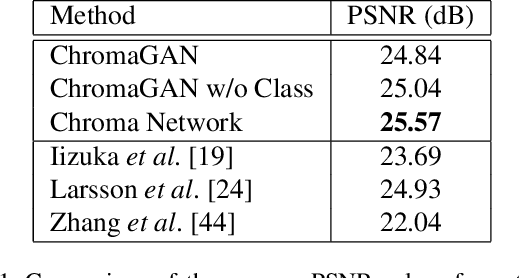


The colorization of grayscale images is an ill-posed problem, with multiple correct solutions. In this paper, an adversarial learning approach is proposed. A generator network is used to infer the chromaticity of a given grayscale image. The same network also performs a semantic classification of the image. This network is framed in an adversarial model that learns to colorize by incorporating perceptual and semantic understanding of color and class distributions. The model is trained via a fully self-supervised strategy. Qualitative and quantitative results show the capacity of the proposed method to colorize images in a realistic way, achieving top-tier performances relative to the state-of-the-art.
A survey of exemplar-based texture synthesis
Nov 24, 2017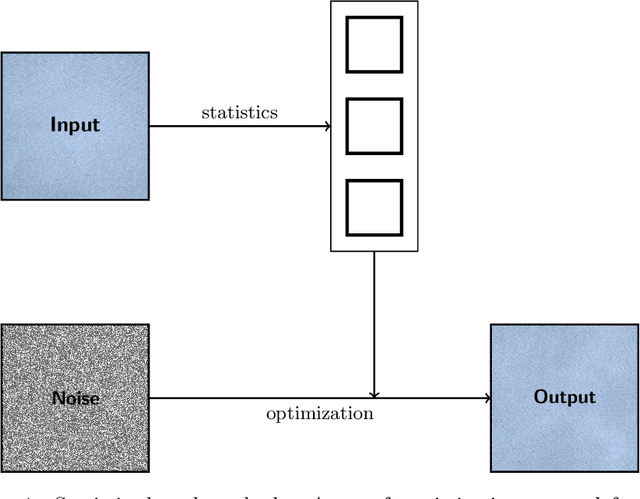

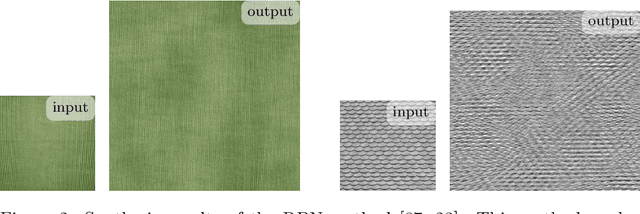

Exemplar-based texture synthesis is the process of generating, from an input sample, new texture images of arbitrary size and which are perceptually equivalent to the sample. The two main approaches are statistics-based methods and patch re-arrangement methods. In the first class, a texture is characterized by a statistical signature; then, a random sampling conditioned to this signature produces genuinely different texture images. The second class boils down to a clever "copy-paste" procedure, which stitches together large regions of the sample. Hybrid methods try to combine ideas from both approaches to avoid their hurdles. The recent approaches using convolutional neural networks fit to this classification, some being statistical and others performing patch re-arrangement in the feature space. They produce impressive synthesis on various kinds of textures. Nevertheless, we found that most real textures are organized at multiple scales, with global structures revealed at coarse scales and highly varying details at finer ones. Thus, when confronted with large natural images of textures the results of state-of-the-art methods degrade rapidly, and the problem of modeling them remains wide open.