 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRETHINED: A New Benchmark and Baseline for Real-Time High-Resolution Image Inpainting On Edge Devices
Mar 18, 2025
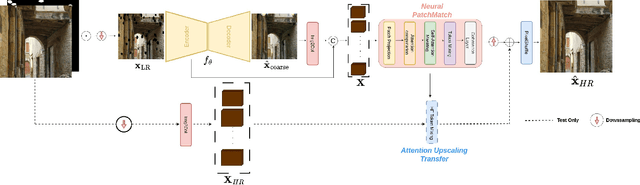


Existing image inpainting methods have shown impressive completion results for low-resolution images. However, most of these algorithms fail at high resolutions and require powerful hardware, limiting their deployment on edge devices. Motivated by this, we propose the first baseline for REal-Time High-resolution image INpainting on Edge Devices (RETHINED) that is able to inpaint at ultra-high-resolution and can run in real-time ($\leq$ 30ms) in a wide variety of mobile devices. A simple, yet effective novel method formed by a lightweight Convolutional Neural Network (CNN) to recover structure, followed by a resolution-agnostic patch replacement mechanism to provide detailed texture. Specially our pipeline leverages the structural capacity of CNN and the high-level detail of patch-based methods, which is a key component for high-resolution image inpainting. To demonstrate the real application of our method, we conduct an extensive analysis on various mobile-friendly devices and demonstrate similar inpainting performance while being $\mathrm{100 \times faster}$ than existing state-of-the-art methods. Furthemore, we realease DF8K-Inpainting, the first free-form mask UHD inpainting dataset.
Joint Reconstruction and Parcellation of Cortical Surfaces
Sep 19, 2022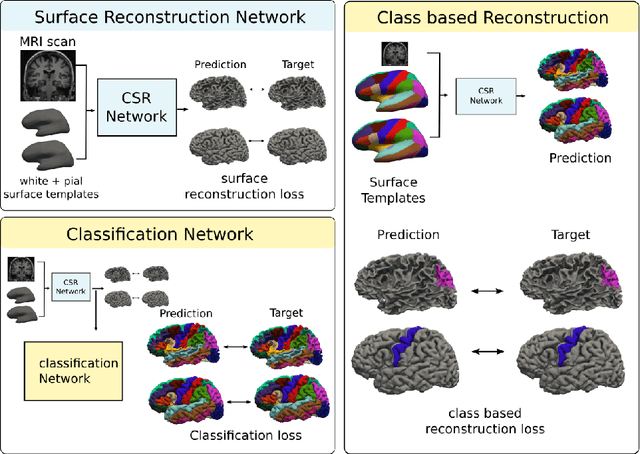
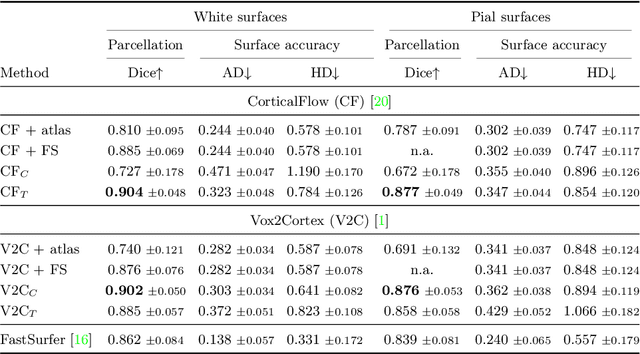
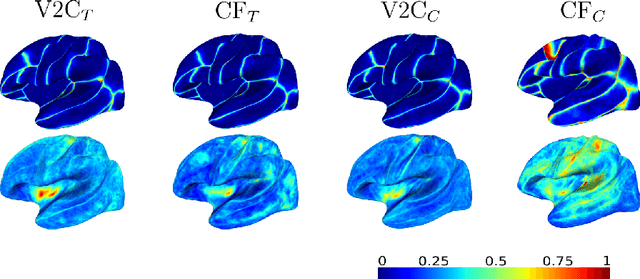
The reconstruction of cerebral cortex surfaces from brain MRI scans is instrumental for the analysis of brain morphology and the detection of cortical thinning in neurodegenerative diseases like Alzheimer's disease (AD). Moreover, for a fine-grained analysis of atrophy patterns, the parcellation of the cortical surfaces into individual brain regions is required. For the former task, powerful deep learning approaches, which provide highly accurate brain surfaces of tissue boundaries from input MRI scans in seconds, have recently been proposed. However, these methods do not come with the ability to provide a parcellation of the reconstructed surfaces. Instead, separate brain-parcellation methods have been developed, which typically consider the cortical surfaces as given, often computed beforehand with FreeSurfer. In this work, we propose two options, one based on a graph classification branch and another based on a novel generic 3D reconstruction loss, to augment template-deformation algorithms such that the surface meshes directly come with an atlas-based brain parcellation. By combining both options with two of the latest cortical surface reconstruction algorithms, we attain highly accurate parcellations with a Dice score of 90.2 (graph classification branch) and 90.4 (novel reconstruction loss) together with state-of-the-art surfaces.
Is a PET all you need? A multi-modal study for Alzheimer's disease using 3D CNNs
Jul 05, 2022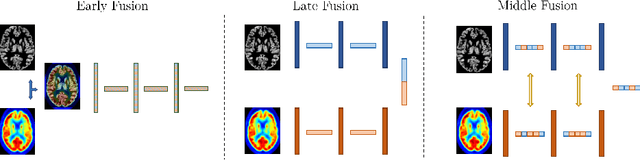
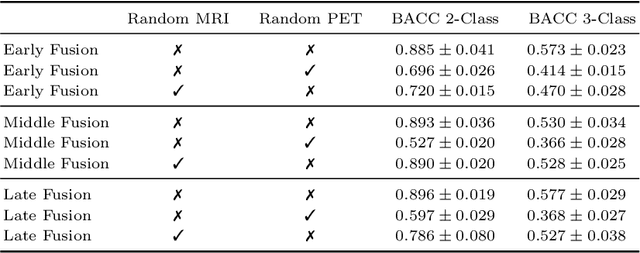

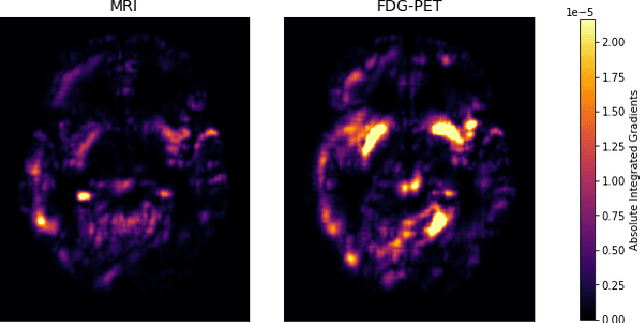
Alzheimer's Disease (AD) is the most common form of dementia and often difficult to diagnose due to the multifactorial etiology of dementia. Recent works on neuroimaging-based computer-aided diagnosis with deep neural networks (DNNs) showed that fusing structural magnetic resonance images (sMRI) and fluorodeoxyglucose positron emission tomography (FDG-PET) leads to improved accuracy in a study population of healthy controls and subjects with AD. However, this result conflicts with the established clinical knowledge that FDG-PET better captures AD-specific pathologies than sMRI. Therefore, we propose a framework for the systematic evaluation of multi-modal DNNs and critically re-evaluate single- and multi-modal DNNs based on FDG-PET and sMRI for binary healthy vs. AD, and three-way healthy/mild cognitive impairment/AD classification. Our experiments demonstrate that a single-modality network using FDG-PET performs better than MRI (accuracy 0.91 vs 0.87) and does not show improvement when combined. This conforms with the established clinical knowledge on AD biomarkers, but raises questions about the true benefit of multi-modal DNNs. We argue that future work on multi-modal fusion should systematically assess the contribution of individual modalities following our proposed evaluation framework. Finally, we encourage the community to go beyond healthy vs. AD classification and focus on differential diagnosis of dementia, where fusing multi-modal image information conforms with a clinical need.
CASHformer: Cognition Aware SHape Transformer for Longitudinal Analysis
Jul 05, 2022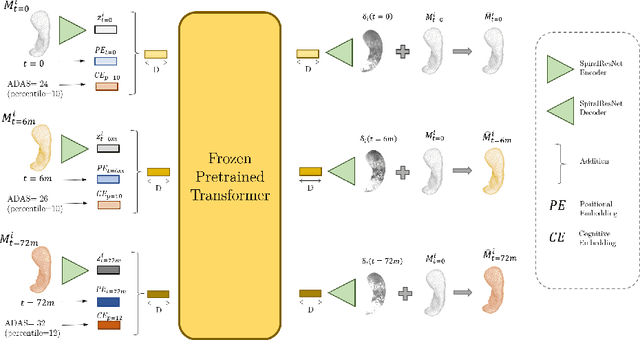
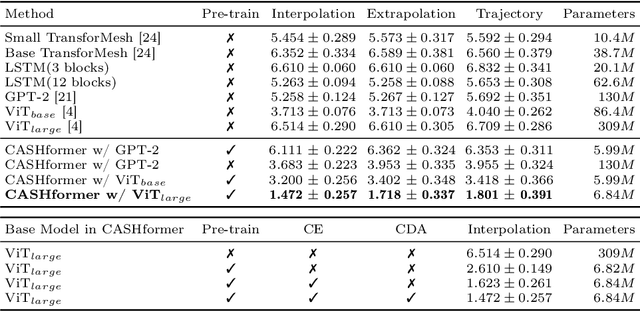
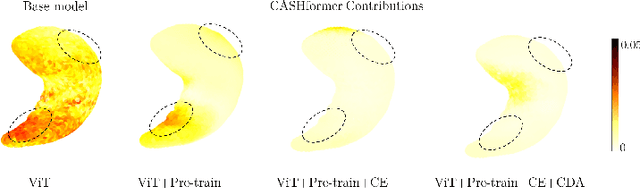
Modeling temporal changes in subcortical structures is crucial for a better understanding of the progression of Alzheimer's disease (AD). Given their flexibility to adapt to heterogeneous sequence lengths, mesh-based transformer architectures have been proposed in the past for predicting hippocampus deformations across time. However, one of the main limitations of transformers is the large amount of trainable parameters, which makes the application on small datasets very challenging. In addition, current methods do not include relevant non-image information that can help to identify AD-related patterns in the progression. To this end, we introduce CASHformer, a transformer-based framework to model longitudinal shape trajectories in AD. CASHformer incorporates the idea of pre-trained transformers as universal compute engines that generalize across a wide range of tasks by freezing most layers during fine-tuning. This reduces the number of parameters by over 90% with respect to the original model and therefore enables the application of large models on small datasets without overfitting. In addition, CASHformer models cognitive decline to reveal AD atrophy patterns in the temporal sequence. Our results show that CASHformer reduces the reconstruction error by 73% compared to previously proposed methods. Moreover, the accuracy of detecting patients progressing to AD increases by 3% with imputing missing longitudinal shape data.
TransforMesh: A Transformer Network for Longitudinal modeling of Anatomical Meshes
Sep 23, 2021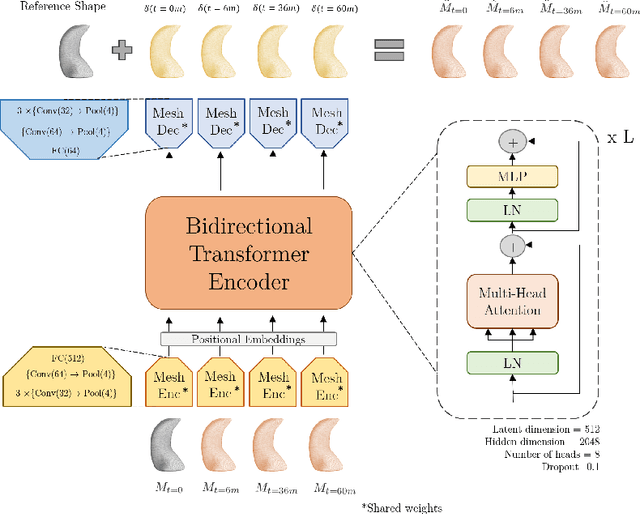
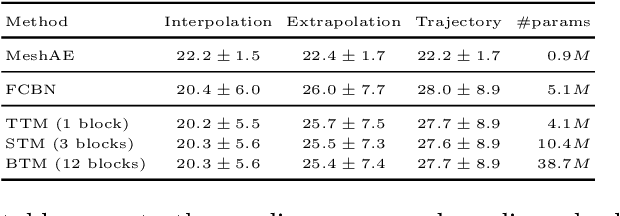
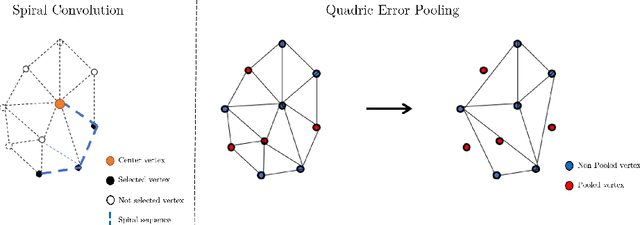
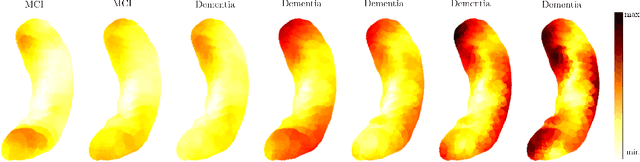
The longitudinal modeling of neuroanatomical changes related to Alzheimer's disease (AD) is crucial for studying the progression of the disease. To this end, we introduce TransforMesh, a spatio-temporal network based on transformers that models longitudinal shape changes on 3D anatomical meshes. While transformer and mesh networks have recently shown impressive performances in natural language processing and computer vision, their application to medical image analysis has been very limited. To the best of our knowledge, this is the first work that combines transformer and mesh networks. Our results show that TransforMesh can model shape trajectories better than other baseline architectures that do not capture temporal dependencies. Moreover, we also explore the capabilities of TransforMesh in detecting structural anomalies of the hippocampus in patients developing AD.
The Medical Segmentation Decathlon
Jun 10, 2021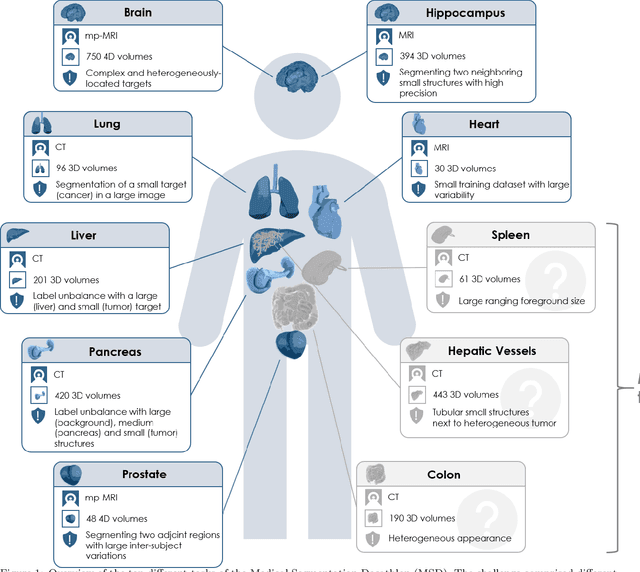
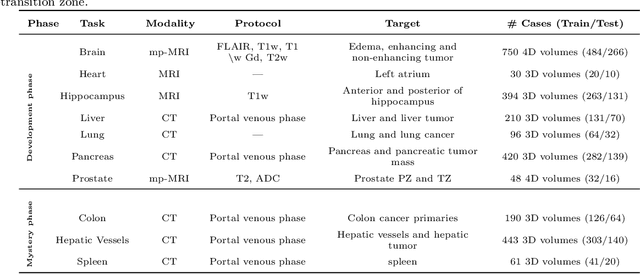
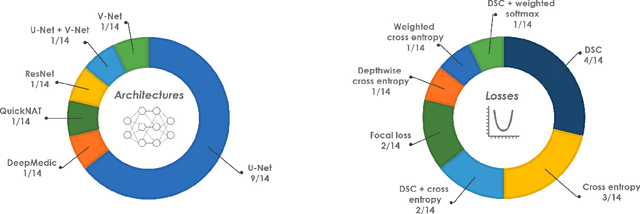
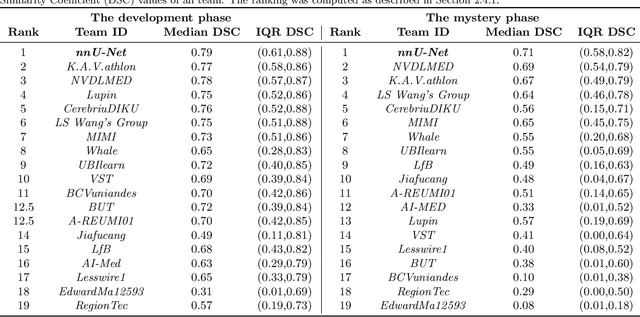
International challenges have become the de facto standard for comparative assessment of image analysis algorithms given a specific task. Segmentation is so far the most widely investigated medical image processing task, but the various segmentation challenges have typically been organized in isolation, such that algorithm development was driven by the need to tackle a single specific clinical problem. We hypothesized that a method capable of performing well on multiple tasks will generalize well to a previously unseen task and potentially outperform a custom-designed solution. To investigate the hypothesis, we organized the Medical Segmentation Decathlon (MSD) - a biomedical image analysis challenge, in which algorithms compete in a multitude of both tasks and modalities. The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data and small objects. The MSD challenge confirmed that algorithms with a consistent good performance on a set of tasks preserved their good average performance on a different set of previously unseen tasks. Moreover, by monitoring the MSD winner for two years, we found that this algorithm continued generalizing well to a wide range of other clinical problems, further confirming our hypothesis. Three main conclusions can be drawn from this study: (1) state-of-the-art image segmentation algorithms are mature, accurate, and generalize well when retrained on unseen tasks; (2) consistent algorithmic performance across multiple tasks is a strong surrogate of algorithmic generalizability; (3) the training of accurate AI segmentation models is now commoditized to non AI experts.
Geometric Deep Learning on Anatomical Meshes for the Prediction of Alzheimer's Disease
Apr 20, 2021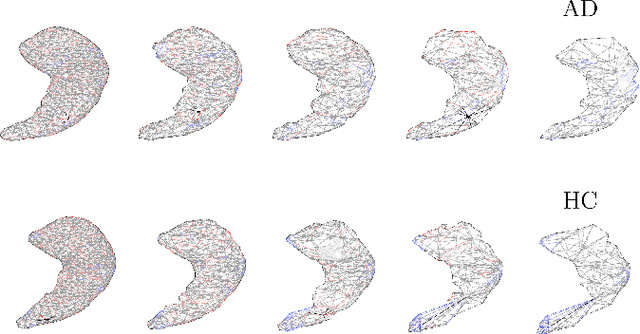

Geometric deep learning can find representations that are optimal for a given task and therefore improve the performance over pre-defined representations. While current work has mainly focused on point representations, meshes also contain connectivity information and are therefore a more comprehensive characterization of the underlying anatomical surface. In this work, we evaluate four recent geometric deep learning approaches that operate on mesh representations. These approaches can be grouped into template-free and template-based approaches, where the template-based methods need a more elaborate pre-processing step with the definition of a common reference template and correspondences. We compare the different networks for the prediction of Alzheimer's disease based on the meshes of the hippocampus. Our results show advantages for template-based methods in terms of accuracy, number of learnable parameters, and training speed. While the template creation may be limiting for some applications, neuroimaging has a long history of building templates with automated tools readily available. Overall, working with meshes is more involved than working with simplistic point clouds, but they also offer new avenues for designing geometric deep learning architectures.
Recalibration of Neural Networks for Point Cloud Analysis
Nov 25, 2020



Spatial and channel re-calibration have become powerful concepts in computer vision. Their ability to capture long-range dependencies is especially useful for those networks that extract local features, such as CNNs. While re-calibration has been widely studied for image analysis, it has not yet been used on shape representations. In this work, we introduce re-calibration modules on deep neural networks for 3D point clouds. We propose a set of re-calibration blocks that extend Squeeze and Excitation blocks and that can be added to any network for 3D point cloud analysis that builds a global descriptor by hierarchically combining features from multiple local neighborhoods. We run two sets of experiments to validate our approach. First, we demonstrate the benefit and versatility of our proposed modules by incorporating them into three state-of-the-art networks for 3D point cloud analysis: PointNet++, DGCNN, and RSCNN. We evaluate each network on two tasks: object classification on ModelNet40, and object part segmentation on ShapeNet. Our results show an improvement of up to 1% in accuracy for ModelNet40 compared to the baseline method. In the second set of experiments, we investigate the benefits of re-calibration blocks on Alzheimer's Disease (AD) diagnosis. Our results demonstrate that our proposed methods yield a 2% increase in accuracy for diagnosing AD and a 2.3% increase in concordance index for predicting AD onset with time-to-event analysis. Concluding, re-calibration improves the accuracy of point cloud architectures, while only minimally increasing the number of parameters.
Discriminative and Generative Models for Anatomical Shape Analysison Point Clouds with Deep Neural Networks
Oct 02, 2020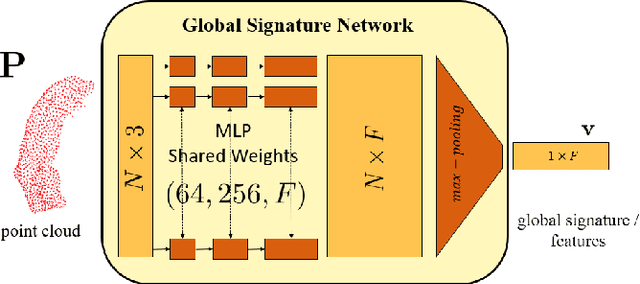
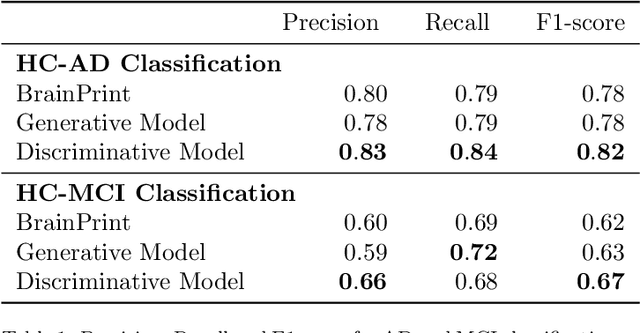
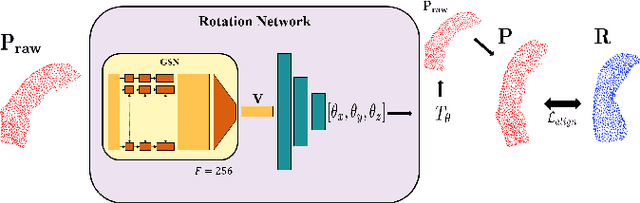
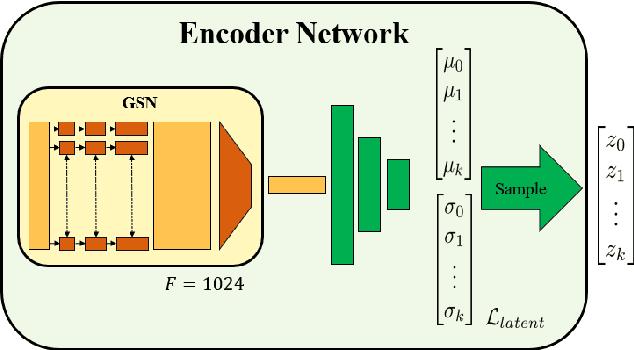
We introduce deep neural networks for the analysis of anatomical shapes that learn a low-dimensional shape representation from the given task, instead of relying on hand-engineered representations. Our framework is modular and consists of several computing blocks that perform fundamental shape processing tasks. The networks operate on unordered point clouds and provide invariance to similarity transformations, avoiding the need to identify point correspondences between shapes. Based on the framework, we assemble a discriminative model for disease classification and age regression, as well as a generative model for the accruate reconstruction of shapes. In particular, we propose a conditional generative model, where the condition vector provides a mechanism to control the generative process. instance, it enables to assess shape variations specific to a particular diagnosis, when passing it as side information. Next to working on single shapes, we introduce an extension for the joint analysis of multiple anatomical structures, where the simultaneous modeling of multiple structures can lead to a more compact encoding and a better understanding of disorders. We demonstrate the advantages of our framework in comprehensive experiments on real and synthetic data. The key insights are that (i) learning a shape representation specific to the given task yields higher performance than alternative shape descriptors, (ii) multi-structure analysis is both more efficient and more accurate than single-structure analysis, and (iii) point clouds generated by our model capture morphological differences associated to Alzheimers disease, to the point that they can be used to train a discriminative model for disease classification. Our framework naturally scales to the analysis of large datasets, giving it the potential to learn characteristic variations in large populations.
Recalibrating 3D ConvNets with Project & Excite
Feb 25, 2020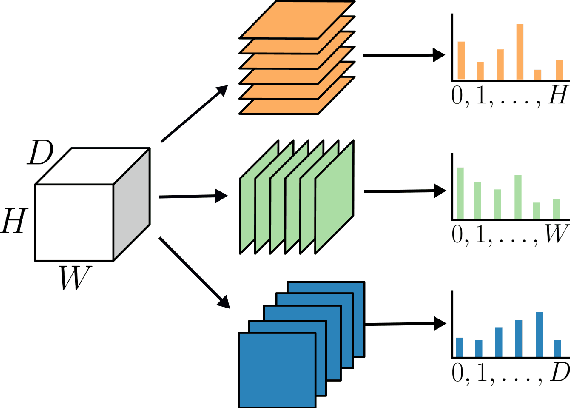

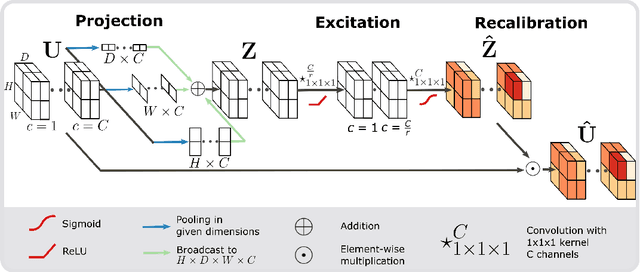
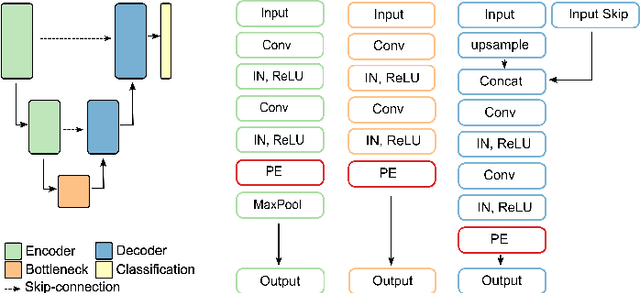
Fully Convolutional Neural Networks (F-CNNs) achieve state-of-the-art performance for segmentation tasks in computer vision and medical imaging. Recently, computational blocks termed squeeze and excitation (SE) have been introduced to recalibrate F-CNN feature maps both channel- and spatial-wise, boosting segmentation performance while only minimally increasing the model complexity. So far, the development of SE blocks has focused on 2D architectures. For volumetric medical images, however, 3D F-CNNs are a natural choice. In this article, we extend existing 2D recalibration methods to 3D and propose a generic compress-process-recalibrate pipeline for easy comparison of such blocks. We further introduce Project & Excite (PE) modules, customized for 3D networks. In contrast to existing modules, Project \& Excite does not perform global average pooling but compresses feature maps along different spatial dimensions of the tensor separately to retain more spatial information that is subsequently used in the excitation step. We evaluate the modules on two challenging tasks, whole-brain segmentation of MRI scans and whole-body segmentation of CT scans. We demonstrate that PE modules can be easily integrated into 3D F-CNNs, boosting performance up to 0.3 in Dice Score and outperforming 3D extensions of other recalibration blocks, while only marginally increasing the model complexity. Our code is publicly available on https://github.com/ai-med/squeeze_and_excitation .