 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning From Routine Histology Improves Risk Stratification for Biochemical Recurrence in Prostate Cancer
Mar 15, 2026Accurate prediction of biochemical recurrence (BCR) after radical prostatectomy is critical for guiding adjuvant treatment and surveillance decisions in prostate cancer. However, existing clinicopathological risk models reduce complex morphology to relatively coarse descriptors, leaving substantial prognostic information embedded in routine histopathology underexplored. We present a deep learning-based biomarker that predicts continuous, patient-specific risk of BCR directly from H&E-stained whole-slide prostatectomy specimens. Trained end-to-end on time-to-event outcomes and evaluated across four independent international cohorts, our model demonstrates robust generalization across institutions and patient populations. When integrated with the CAPRA-S clinical risk score, the deep learning risk score consistently improved discrimination for BCR, increasing concordance indices from 0.725-0.772 to 0.749-0.788 across cohorts. To support clinical interpretability, outcome-grounded analyses revealed subtle histomorphological patterns associated with recurrence risk that are not captured by conventional clinicopathological risk scores. This multicohort study demonstrates that deep learning applied to routine prostate histopathology can deliver reproducible and clinically generalizable biomarkers that augment postoperative risk stratification, with potential to support personalized management of prostate cancer in real-world clinical settings.
Designing UNICORN: a Unified Benchmark for Imaging in Computational Pathology, Radiology, and Natural Language
Mar 03, 2026Medical foundation models show promise to learn broadly generalizable features from large, diverse datasets. This could be the base for reliable cross-modality generalization and rapid adaptation to new, task-specific goals, with only a few task-specific examples. Yet, evidence for this is limited by the lack of public, standardized, and reproducible evaluation frameworks, as existing public benchmarks are often fragmented across task-, organ-, or modality-specific settings, limiting assessment of cross-task generalization. We introduce UNICORN, a public benchmark designed to systematically evaluate medical foundation models under a unified protocol. To isolate representation quality, we built the benchmark on a novel two-step framework that decouples model inference from task-specific evaluation based on standardized few-shot adaptation. As a central design choice, we constructed indirectly accessible sequestered test sets derived from clinically relevant cohorts, along with standardized evaluation code and a submission interface on an open benchmarking platform. Performance is aggregated into a single UNICORN Score, a new metric that we introduce to support direct comparison of foundation models across diverse medical domains, modalities, and task types. The UNICORN test dataset includes data from more than 2,400 patients, including over 3,700 vision cases and over 2,400 clinical reports collected from 17 institutions across eight countries. The benchmark spans eight anatomical regions and four imaging modalities. Both task-specific and aggregated leaderboards enable accessible, standardized, and reproducible evaluation. By standardizing multi-task, multi-modality assessment, UNICORN establishes a foundation for reproducible benchmarking of medical foundation models. Data, baseline methods, and the evaluation platform are publicly available via unicorn.grand-challenge.org.
Democratizing Pathology Co-Pilots: An Open Pipeline and Dataset for Whole-Slide Vision-Language Modelling
Dec 19, 2025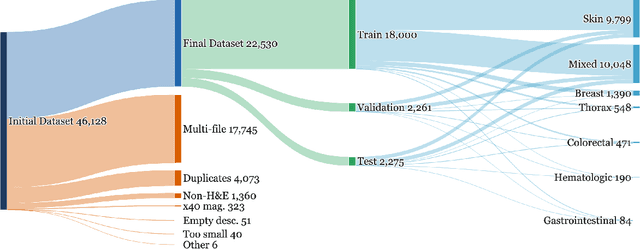
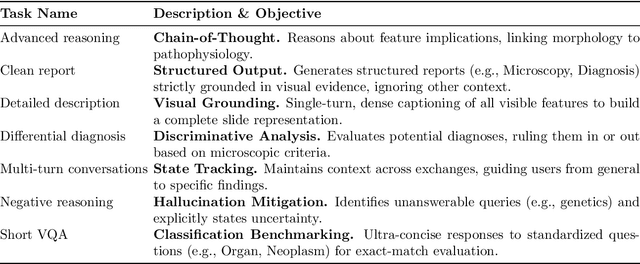
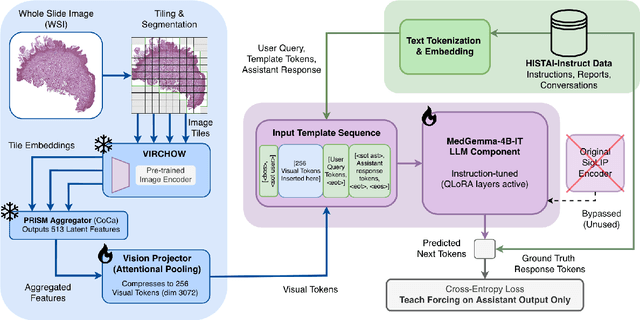
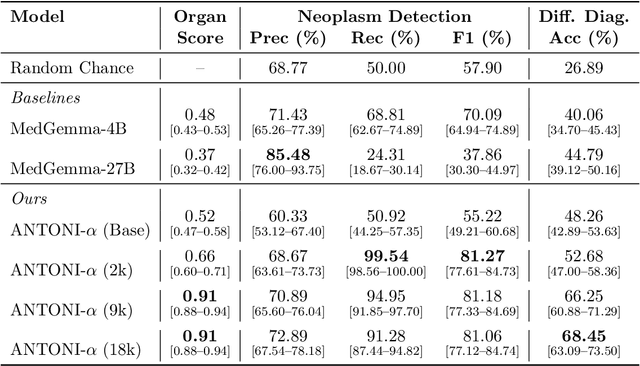
Vision-language models (VLMs) have the potential to become co-pilots for pathologists. However, most VLMs either focus on small regions of interest within whole-slide images, provide only static slide-level outputs, or rely on data that is not publicly available, limiting reproducibility. Furthermore, training data containing WSIs paired with detailed clinical reports is scarce, restricting progress toward transparent and generalisable VLMs. We address these limitations with three main contributions. First, we introduce Polysome, a standardised tool for synthetic instruction generation. Second, we apply Polysome to the public HISTAI dataset, generating HISTAI-Instruct, a large whole-slide instruction tuning dataset spanning 24,259 slides and over 1.1 million instruction-response pairs. Finally, we use HISTAI-Instruct to train ANTONI-α, a VLM capable of visual-question answering (VQA). We show that ANTONI-α outperforms MedGemma on WSI-level VQA tasks of tissue identification, neoplasm detection, and differential diagnosis. We also compare the performance of multiple incarnations of ANTONI-α trained with different amounts of data. All methods, data, and code are publicly available.
Prototype-Based Multiple Instance Learning for Gigapixel Whole Slide Image Classification
Mar 11, 2025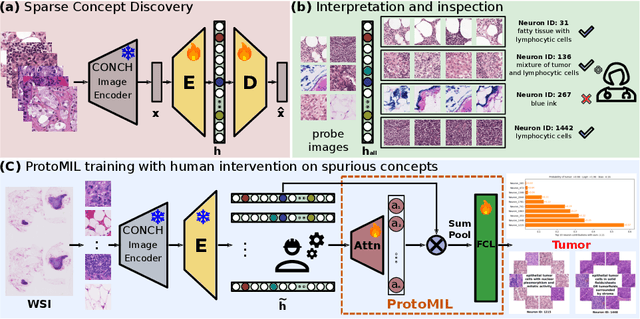
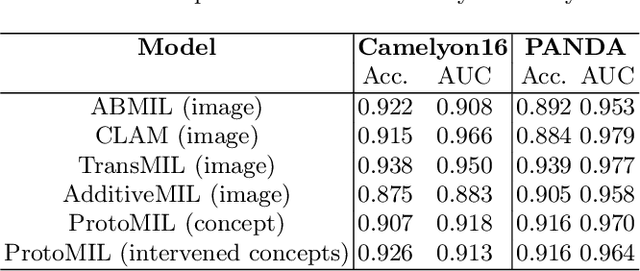
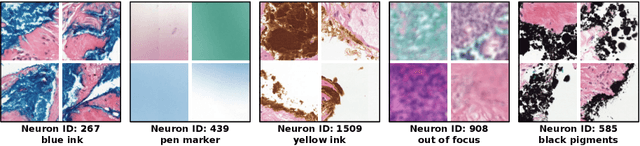
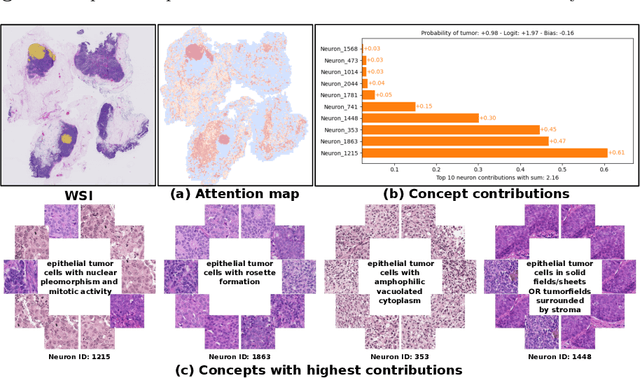
Multiple Instance Learning (MIL) methods have succeeded remarkably in histopathology whole slide image (WSI) analysis. However, most MIL models only offer attention-based explanations that do not faithfully capture the model's decision mechanism and do not allow human-model interaction. To address these limitations, we introduce ProtoMIL, an inherently interpretable MIL model for WSI analysis that offers user-friendly explanations and supports human intervention. Our approach employs a sparse autoencoder to discover human-interpretable concepts from the image feature space, which are then used to train ProtoMIL. The model represents predictions as linear combinations of concepts, making the decision process transparent. Furthermore, ProtoMIL allows users to perform model interventions by altering the input concepts. Experiments on two widely used pathology datasets demonstrate that ProtoMIL achieves a classification performance comparable to state-of-the-art MIL models while offering intuitively understandable explanations. Moreover, we demonstrate that our method can eliminate reliance on diagnostically irrelevant information via human intervention, guiding the model toward being right for the right reason. Code will be publicly available at https://github.com/ss-sun/ProtoMIL.
Label-free Concept Based Multiple Instance Learning for Gigapixel Histopathology
Jan 06, 2025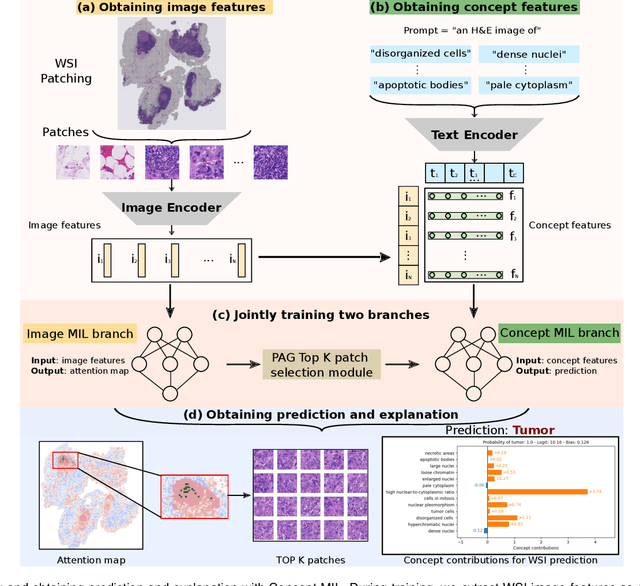
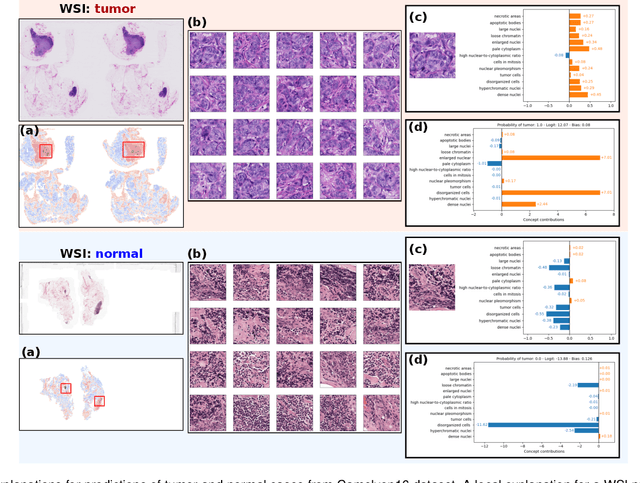
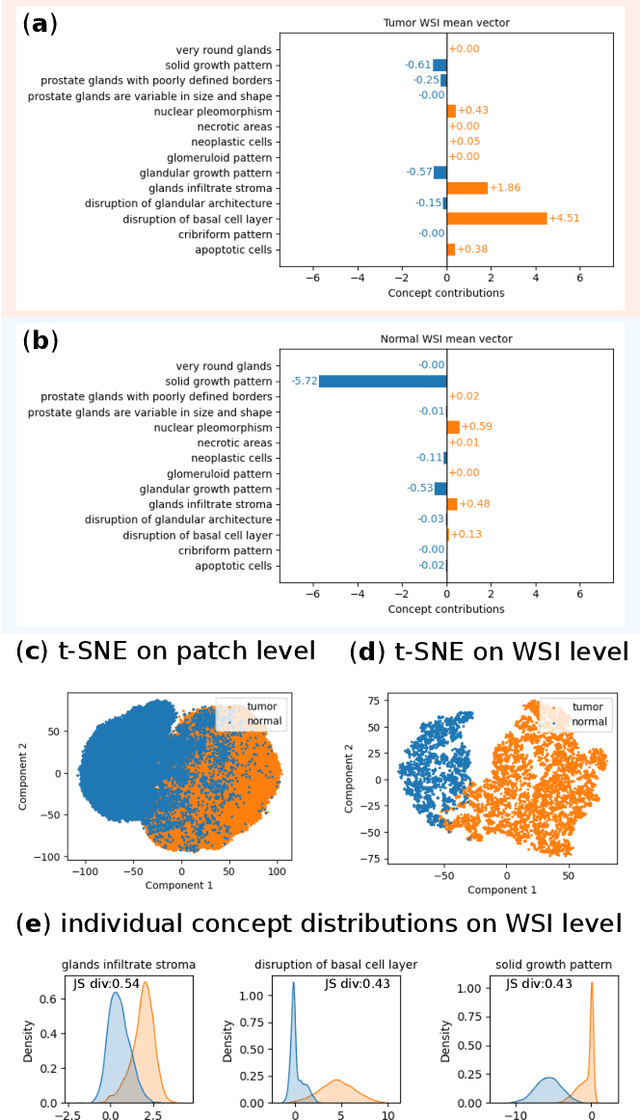
Multiple Instance Learning (MIL) methods allow for gigapixel Whole-Slide Image (WSI) analysis with only slide-level annotations. Interpretability is crucial for safely deploying such algorithms in high-stakes medical domains. Traditional MIL methods offer explanations by highlighting salient regions. However, such spatial heatmaps provide limited insights for end users. To address this, we propose a novel inherently interpretable WSI-classification approach that uses human-understandable pathology concepts to generate explanations. Our proposed Concept MIL model leverages recent advances in vision-language models to directly predict pathology concepts based on image features. The model's predictions are obtained through a linear combination of the concepts identified on the top-K patches of a WSI, enabling inherent explanations by tracing each concept's influence on the prediction. In contrast to traditional concept-based interpretable models, our approach eliminates the need for costly human annotations by leveraging the vision-language model. We validate our method on two widely used pathology datasets: Camelyon16 and PANDA. On both datasets, Concept MIL achieves AUC and accuracy scores over 0.9, putting it on par with state-of-the-art models. We further find that 87.1\% (Camelyon16) and 85.3\% (PANDA) of the top 20 patches fall within the tumor region. A user study shows that the concepts identified by our model align with the concepts used by pathologists, making it a promising strategy for human-interpretable WSI classification.
Navigating the landscape of multimodal AI in medicine: a scoping review on technical challenges and clinical applications
Nov 06, 2024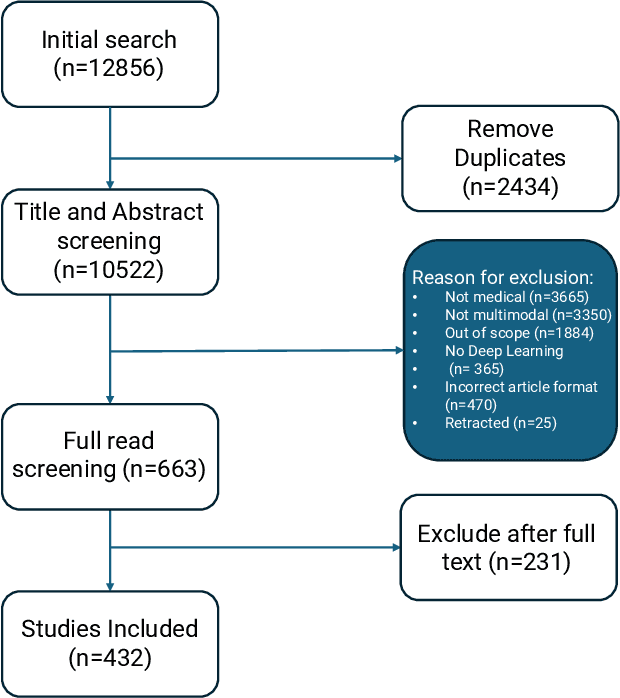
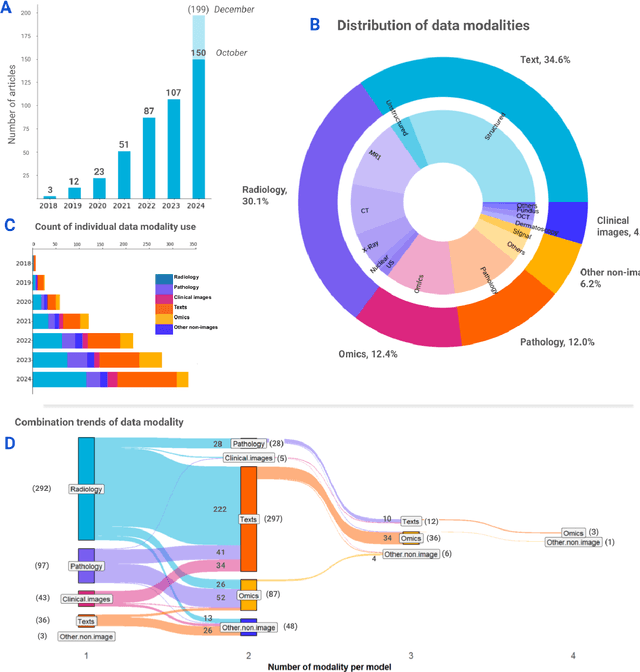
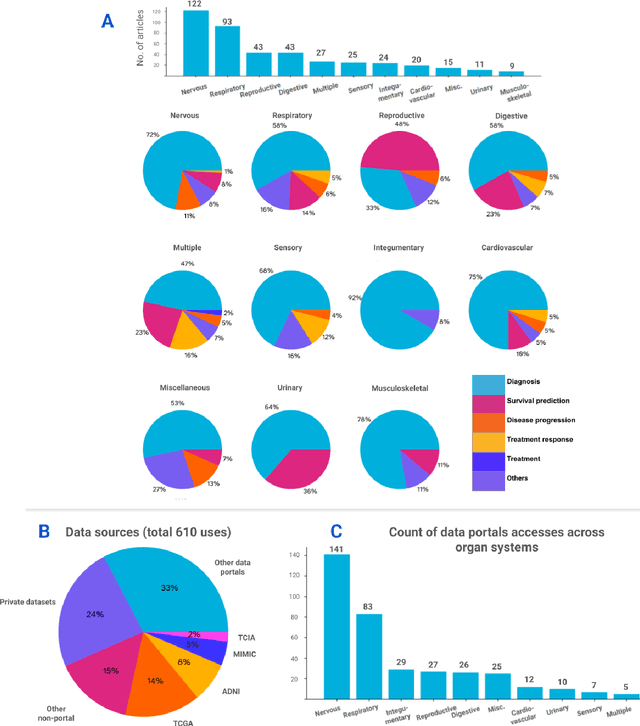
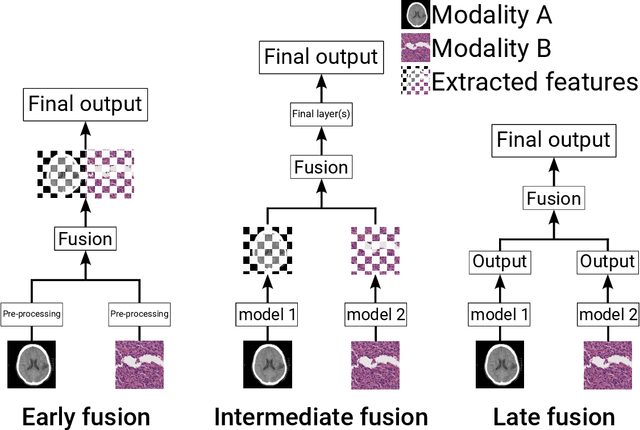
Recent technological advances in healthcare have led to unprecedented growth in patient data quantity and diversity. While artificial intelligence (AI) models have shown promising results in analyzing individual data modalities, there is increasing recognition that models integrating multiple complementary data sources, so-called multimodal AI, could enhance clinical decision-making. This scoping review examines the landscape of deep learning-based multimodal AI applications across the medical domain, analyzing 432 papers published between 2018 and 2024. We provide an extensive overview of multimodal AI development across different medical disciplines, examining various architectural approaches, fusion strategies, and common application areas. Our analysis reveals that multimodal AI models consistently outperform their unimodal counterparts, with an average improvement of 6.2 percentage points in AUC. However, several challenges persist, including cross-departmental coordination, heterogeneous data characteristics, and incomplete datasets. We critically assess the technical and practical challenges in developing multimodal AI systems and discuss potential strategies for their clinical implementation, including a brief overview of commercially available multimodal AI models for clinical decision-making. Additionally, we identify key factors driving multimodal AI development and propose recommendations to accelerate the field's maturation. This review provides researchers and clinicians with a thorough understanding of the current state, challenges, and future directions of multimodal AI in medicine.
Masked Attention as a Mechanism for Improving Interpretability of Vision Transformers
Apr 28, 2024
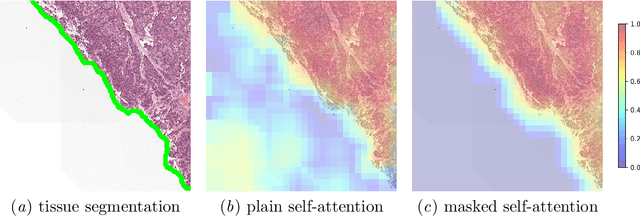

Vision Transformers are at the heart of the current surge of interest in foundation models for histopathology. They process images by breaking them into smaller patches following a regular grid, regardless of their content. Yet, not all parts of an image are equally relevant for its understanding. This is particularly true in computational pathology where background is completely non-informative and may introduce artefacts that could mislead predictions. To address this issue, we propose a novel method that explicitly masks background in Vision Transformers' attention mechanism. This ensures tokens corresponding to background patches do not contribute to the final image representation, thereby improving model robustness and interpretability. We validate our approach using prostate cancer grading from whole-slide images as a case study. Our results demonstrate that it achieves comparable performance with plain self-attention while providing more accurate and clinically meaningful attention heatmaps.
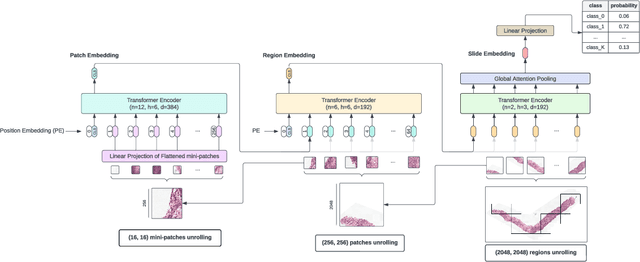
Hierarchical Vision Transformers for Context-Aware Prostate Cancer Grading in Whole Slide Images
Dec 19, 2023Vision Transformers (ViTs) have ushered in a new era in computer vision, showcasing unparalleled performance in many challenging tasks. However, their practical deployment in computational pathology has largely been constrained by the sheer size of whole slide images (WSIs), which result in lengthy input sequences. Transformers faced a similar limitation when applied to long documents, and Hierarchical Transformers were introduced to circumvent it. Given the analogous challenge with WSIs and their inherent hierarchical structure, Hierarchical Vision Transformers (H-ViTs) emerge as a promising solution in computational pathology. This work delves into the capabilities of H-ViTs, evaluating their efficiency for prostate cancer grading in WSIs. Our results show that they achieve competitive performance against existing state-of-the-art solutions.
Understanding metric-related pitfalls in image analysis validation
Feb 09, 2023Validation metrics are key for the reliable tracking of scientific progress and for bridging the current chasm between artificial intelligence (AI) research and its translation into practice. However, increasing evidence shows that particularly in image analysis, metrics are often chosen inadequately in relation to the underlying research problem. This could be attributed to a lack of accessibility of metric-related knowledge: While taking into account the individual strengths, weaknesses, and limitations of validation metrics is a critical prerequisite to making educated choices, the relevant knowledge is currently scattered and poorly accessible to individual researchers. Based on a multi-stage Delphi process conducted by a multidisciplinary expert consortium as well as extensive community feedback, the present work provides the first reliable and comprehensive common point of access to information on pitfalls related to validation metrics in image analysis. Focusing on biomedical image analysis but with the potential of transfer to other fields, the addressed pitfalls generalize across application domains and are categorized according to a newly created, domain-agnostic taxonomy. To facilitate comprehension, illustrations and specific examples accompany each pitfall. As a structured body of information accessible to researchers of all levels of expertise, this work enhances global comprehension of a key topic in image analysis validation.
Domain adaptation strategies for cancer-independent detection of lymph node metastases
Jul 13, 2022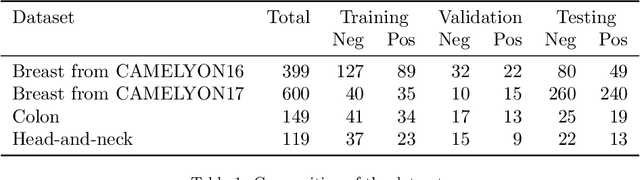

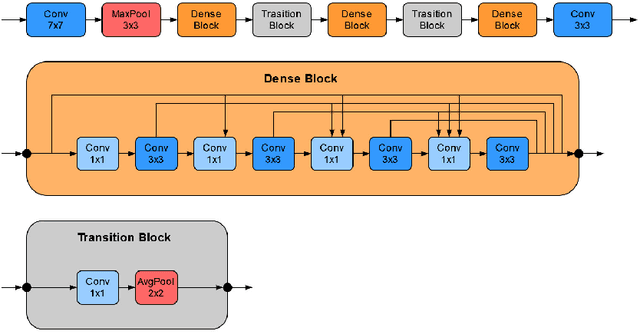
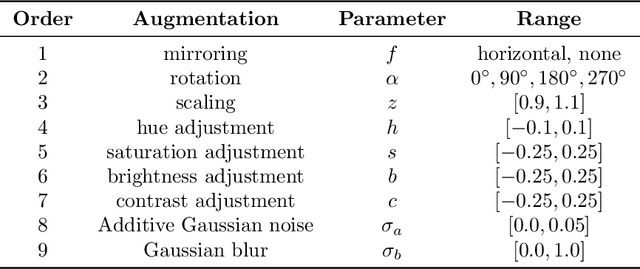
Recently, large, high-quality public datasets have led to the development of convolutional neural networks that can detect lymph node metastases of breast cancer at the level of expert pathologists. Many cancers, regardless of the site of origin, can metastasize to lymph nodes. However, collecting and annotating high-volume, high-quality datasets for every cancer type is challenging. In this paper we investigate how to leverage existing high-quality datasets most efficiently in multi-task settings for closely related tasks. Specifically, we will explore different training and domain adaptation strategies, including prevention of catastrophic forgetting, for colon and head-and-neck cancer metastasis detection in lymph nodes. Our results show state-of-the-art performance on both cancer metastasis detection tasks. Furthermore, we show the effectiveness of repeated adaptation of networks from one cancer type to another to obtain multi-task metastasis detection networks. Last, we show that leveraging existing high-quality datasets can significantly boost performance on new target tasks and that catastrophic forgetting can be effectively mitigated using regularization.