 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemocratizing Pathology Co-Pilots: An Open Pipeline and Dataset for Whole-Slide Vision-Language Modelling
Dec 19, 2025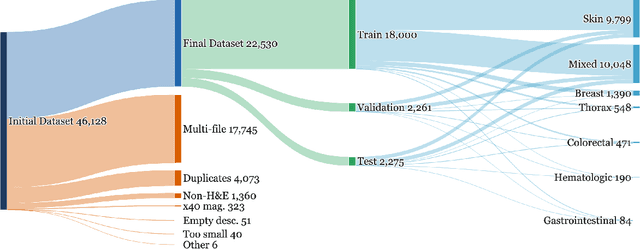
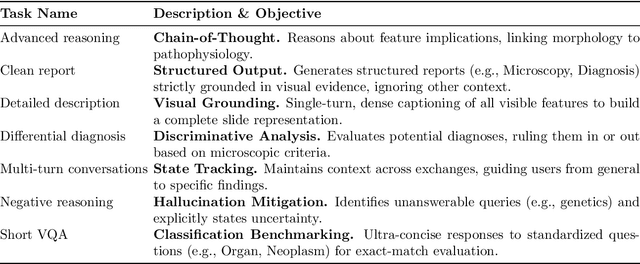
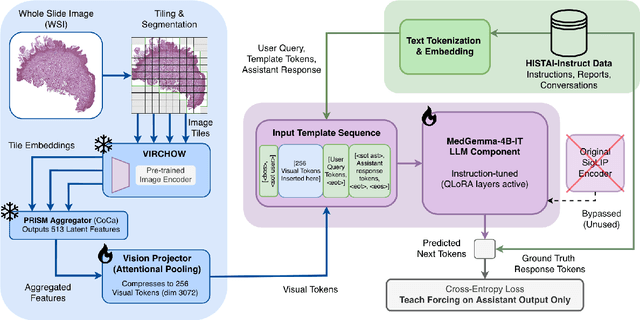
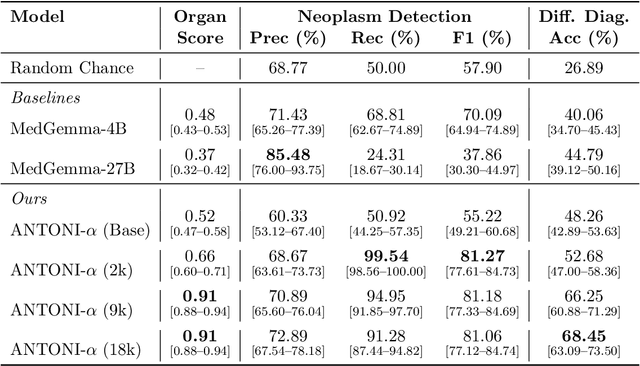
Vision-language models (VLMs) have the potential to become co-pilots for pathologists. However, most VLMs either focus on small regions of interest within whole-slide images, provide only static slide-level outputs, or rely on data that is not publicly available, limiting reproducibility. Furthermore, training data containing WSIs paired with detailed clinical reports is scarce, restricting progress toward transparent and generalisable VLMs. We address these limitations with three main contributions. First, we introduce Polysome, a standardised tool for synthetic instruction generation. Second, we apply Polysome to the public HISTAI dataset, generating HISTAI-Instruct, a large whole-slide instruction tuning dataset spanning 24,259 slides and over 1.1 million instruction-response pairs. Finally, we use HISTAI-Instruct to train ANTONI-α, a VLM capable of visual-question answering (VQA). We show that ANTONI-α outperforms MedGemma on WSI-level VQA tasks of tissue identification, neoplasm detection, and differential diagnosis. We also compare the performance of multiple incarnations of ANTONI-α trained with different amounts of data. All methods, data, and code are publicly available.
A Multicentric Dataset for Training and Benchmarking Breast Cancer Segmentation in H&E Slides
Oct 02, 2025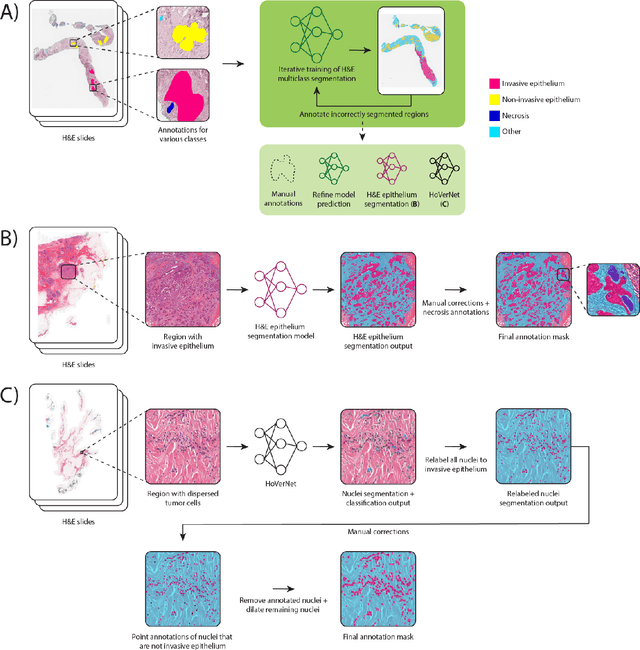


Automated semantic segmentation of whole-slide images (WSIs) stained with hematoxylin and eosin (H&E) is essential for large-scale artificial intelligence-based biomarker analysis in breast cancer. However, existing public datasets for breast cancer segmentation lack the morphological diversity needed to support model generalizability and robust biomarker validation across heterogeneous patient cohorts. We introduce BrEast cancEr hisTopathoLogy sEgmentation (BEETLE), a dataset for multiclass semantic segmentation of H&E-stained breast cancer WSIs. It consists of 587 biopsies and resections from three collaborating clinical centers and two public datasets, digitized using seven scanners, and covers all molecular subtypes and histological grades. Using diverse annotation strategies, we collected annotations across four classes - invasive epithelium, non-invasive epithelium, necrosis, and other - with particular focus on morphologies underrepresented in existing datasets, such as ductal carcinoma in situ and dispersed lobular tumor cells. The dataset's diversity and relevance to the rapidly growing field of automated biomarker quantification in breast cancer ensure its high potential for reuse. Finally, we provide a well-curated, multicentric external evaluation set to enable standardized benchmarking of breast cancer segmentation models.
Label-free Concept Based Multiple Instance Learning for Gigapixel Histopathology
Jan 06, 2025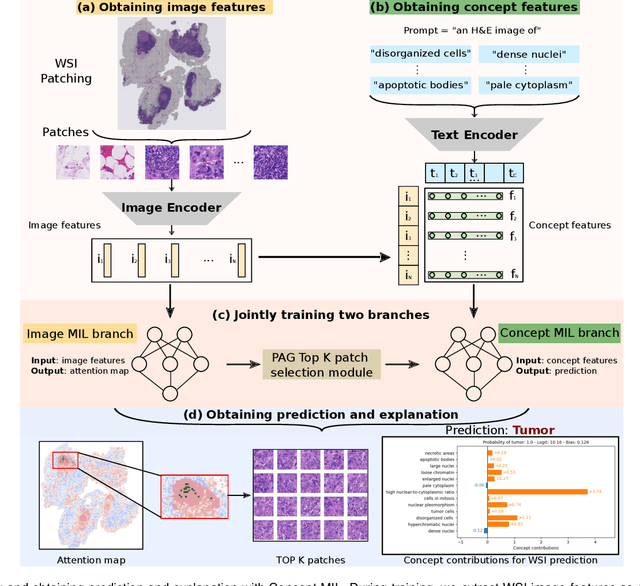
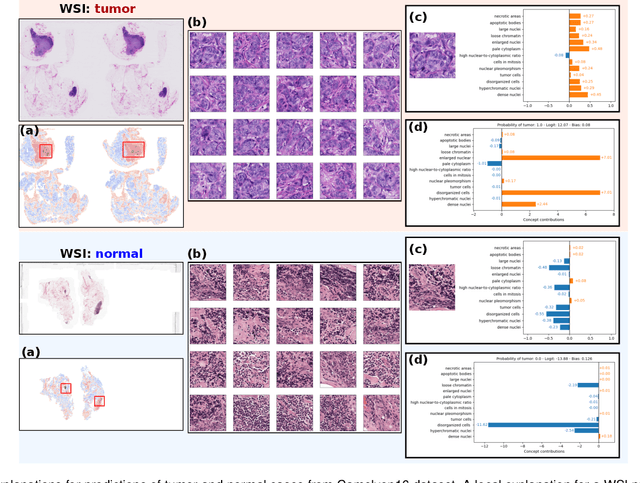
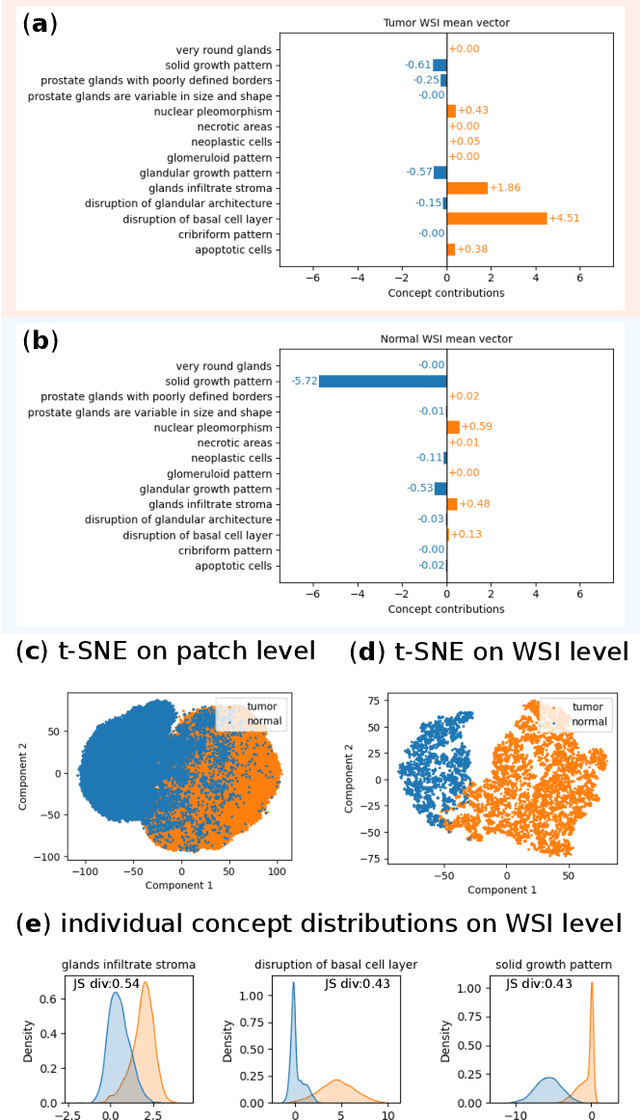
Multiple Instance Learning (MIL) methods allow for gigapixel Whole-Slide Image (WSI) analysis with only slide-level annotations. Interpretability is crucial for safely deploying such algorithms in high-stakes medical domains. Traditional MIL methods offer explanations by highlighting salient regions. However, such spatial heatmaps provide limited insights for end users. To address this, we propose a novel inherently interpretable WSI-classification approach that uses human-understandable pathology concepts to generate explanations. Our proposed Concept MIL model leverages recent advances in vision-language models to directly predict pathology concepts based on image features. The model's predictions are obtained through a linear combination of the concepts identified on the top-K patches of a WSI, enabling inherent explanations by tracing each concept's influence on the prediction. In contrast to traditional concept-based interpretable models, our approach eliminates the need for costly human annotations by leveraging the vision-language model. We validate our method on two widely used pathology datasets: Camelyon16 and PANDA. On both datasets, Concept MIL achieves AUC and accuracy scores over 0.9, putting it on par with state-of-the-art models. We further find that 87.1\% (Camelyon16) and 85.3\% (PANDA) of the top 20 patches fall within the tumor region. A user study shows that the concepts identified by our model align with the concepts used by pathologists, making it a promising strategy for human-interpretable WSI classification.