 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning From Routine Histology Improves Risk Stratification for Biochemical Recurrence in Prostate Cancer
Mar 15, 2026Accurate prediction of biochemical recurrence (BCR) after radical prostatectomy is critical for guiding adjuvant treatment and surveillance decisions in prostate cancer. However, existing clinicopathological risk models reduce complex morphology to relatively coarse descriptors, leaving substantial prognostic information embedded in routine histopathology underexplored. We present a deep learning-based biomarker that predicts continuous, patient-specific risk of BCR directly from H&E-stained whole-slide prostatectomy specimens. Trained end-to-end on time-to-event outcomes and evaluated across four independent international cohorts, our model demonstrates robust generalization across institutions and patient populations. When integrated with the CAPRA-S clinical risk score, the deep learning risk score consistently improved discrimination for BCR, increasing concordance indices from 0.725-0.772 to 0.749-0.788 across cohorts. To support clinical interpretability, outcome-grounded analyses revealed subtle histomorphological patterns associated with recurrence risk that are not captured by conventional clinicopathological risk scores. This multicohort study demonstrates that deep learning applied to routine prostate histopathology can deliver reproducible and clinically generalizable biomarkers that augment postoperative risk stratification, with potential to support personalized management of prostate cancer in real-world clinical settings.
Designing UNICORN: a Unified Benchmark for Imaging in Computational Pathology, Radiology, and Natural Language
Mar 03, 2026Medical foundation models show promise to learn broadly generalizable features from large, diverse datasets. This could be the base for reliable cross-modality generalization and rapid adaptation to new, task-specific goals, with only a few task-specific examples. Yet, evidence for this is limited by the lack of public, standardized, and reproducible evaluation frameworks, as existing public benchmarks are often fragmented across task-, organ-, or modality-specific settings, limiting assessment of cross-task generalization. We introduce UNICORN, a public benchmark designed to systematically evaluate medical foundation models under a unified protocol. To isolate representation quality, we built the benchmark on a novel two-step framework that decouples model inference from task-specific evaluation based on standardized few-shot adaptation. As a central design choice, we constructed indirectly accessible sequestered test sets derived from clinically relevant cohorts, along with standardized evaluation code and a submission interface on an open benchmarking platform. Performance is aggregated into a single UNICORN Score, a new metric that we introduce to support direct comparison of foundation models across diverse medical domains, modalities, and task types. The UNICORN test dataset includes data from more than 2,400 patients, including over 3,700 vision cases and over 2,400 clinical reports collected from 17 institutions across eight countries. The benchmark spans eight anatomical regions and four imaging modalities. Both task-specific and aggregated leaderboards enable accessible, standardized, and reproducible evaluation. By standardizing multi-task, multi-modality assessment, UNICORN establishes a foundation for reproducible benchmarking of medical foundation models. Data, baseline methods, and the evaluation platform are publicly available via unicorn.grand-challenge.org.
Label-free Concept Based Multiple Instance Learning for Gigapixel Histopathology
Jan 06, 2025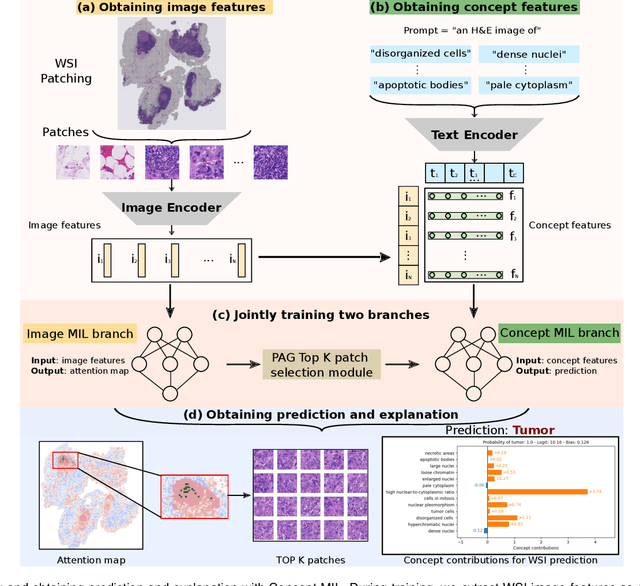
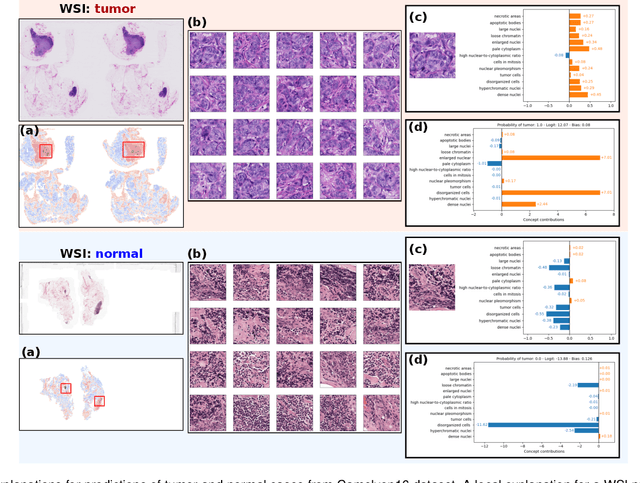
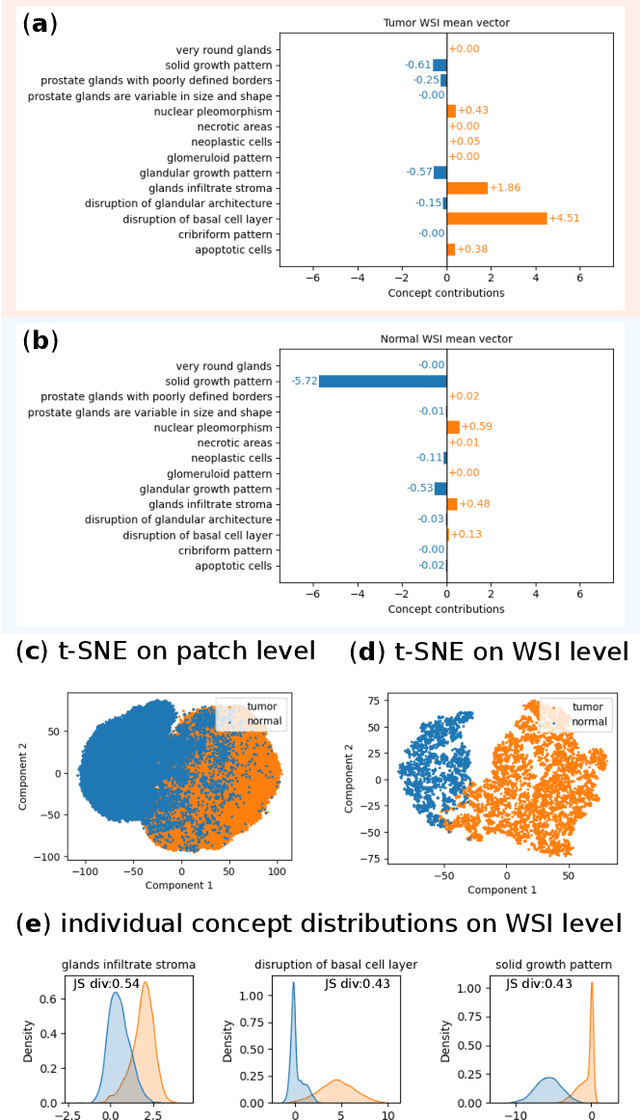
Multiple Instance Learning (MIL) methods allow for gigapixel Whole-Slide Image (WSI) analysis with only slide-level annotations. Interpretability is crucial for safely deploying such algorithms in high-stakes medical domains. Traditional MIL methods offer explanations by highlighting salient regions. However, such spatial heatmaps provide limited insights for end users. To address this, we propose a novel inherently interpretable WSI-classification approach that uses human-understandable pathology concepts to generate explanations. Our proposed Concept MIL model leverages recent advances in vision-language models to directly predict pathology concepts based on image features. The model's predictions are obtained through a linear combination of the concepts identified on the top-K patches of a WSI, enabling inherent explanations by tracing each concept's influence on the prediction. In contrast to traditional concept-based interpretable models, our approach eliminates the need for costly human annotations by leveraging the vision-language model. We validate our method on two widely used pathology datasets: Camelyon16 and PANDA. On both datasets, Concept MIL achieves AUC and accuracy scores over 0.9, putting it on par with state-of-the-art models. We further find that 87.1\% (Camelyon16) and 85.3\% (PANDA) of the top 20 patches fall within the tumor region. A user study shows that the concepts identified by our model align with the concepts used by pathologists, making it a promising strategy for human-interpretable WSI classification.
Masked Attention as a Mechanism for Improving Interpretability of Vision Transformers
Apr 28, 2024
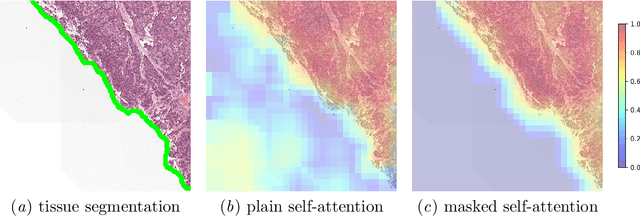

Vision Transformers are at the heart of the current surge of interest in foundation models for histopathology. They process images by breaking them into smaller patches following a regular grid, regardless of their content. Yet, not all parts of an image are equally relevant for its understanding. This is particularly true in computational pathology where background is completely non-informative and may introduce artefacts that could mislead predictions. To address this issue, we propose a novel method that explicitly masks background in Vision Transformers' attention mechanism. This ensures tokens corresponding to background patches do not contribute to the final image representation, thereby improving model robustness and interpretability. We validate our approach using prostate cancer grading from whole-slide images as a case study. Our results demonstrate that it achieves comparable performance with plain self-attention while providing more accurate and clinically meaningful attention heatmaps.
Hierarchical Vision Transformers for Context-Aware Prostate Cancer Grading in Whole Slide Images
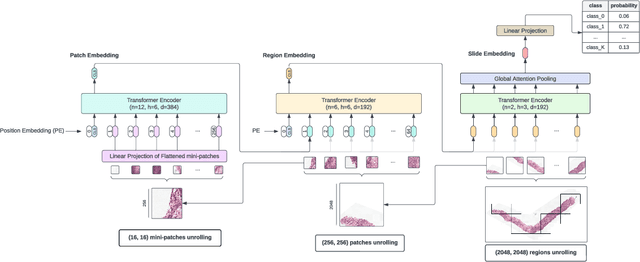
Dec 19, 2023Vision Transformers (ViTs) have ushered in a new era in computer vision, showcasing unparalleled performance in many challenging tasks. However, their practical deployment in computational pathology has largely been constrained by the sheer size of whole slide images (WSIs), which result in lengthy input sequences. Transformers faced a similar limitation when applied to long documents, and Hierarchical Transformers were introduced to circumvent it. Given the analogous challenge with WSIs and their inherent hierarchical structure, Hierarchical Vision Transformers (H-ViTs) emerge as a promising solution in computational pathology. This work delves into the capabilities of H-ViTs, evaluating their efficiency for prostate cancer grading in WSIs. Our results show that they achieve competitive performance against existing state-of-the-art solutions.